微博爬虫系列1-微博粉丝列表获取分析
大家好,我是W
前言:不知道大家学爬虫有没有想过怎么爬微博,那么这个微博爬虫系列就是一步步解析如何爬取微博的全部信息,并且可以让大家实现全站爬取、指定用户全部微博爬取。本篇内容包括微博登录、微博多平台分析、微博个人信息抓取、微博粉丝列表分析。
微博登录
众所周知微博未登录也是可以看到一些信息的,但是也仅限于首页ajax异步加载的信息,在个人主页下也只能看近期发的微博(如图1),在微博话题下看最近几十条(如图2)。能够使用高级搜索,但是相当于查看微博话题只能看最近几十条,所以若要实现特定话题搜索、指定用户爬虫的话还是需要登录微博。明确了微博的拦截范围之后对我们项目有了初步的认识。
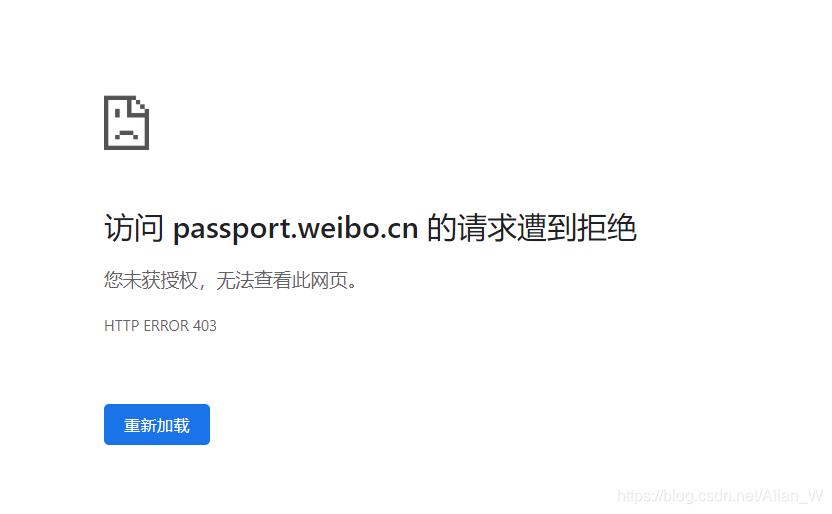
那么接下来就需要找到微博登录的api看看能不能实现带参登录。经过半天的寻找硬是没找到带参数的api,应该是微博经过js加密过了。并且在移动端的登录接口处是可以找到上传的参数的(如图3),好像是可以通过传参数实现登录的,但是通过修改URL查看结果发现已经被服务器预先拦截了(如图5)。
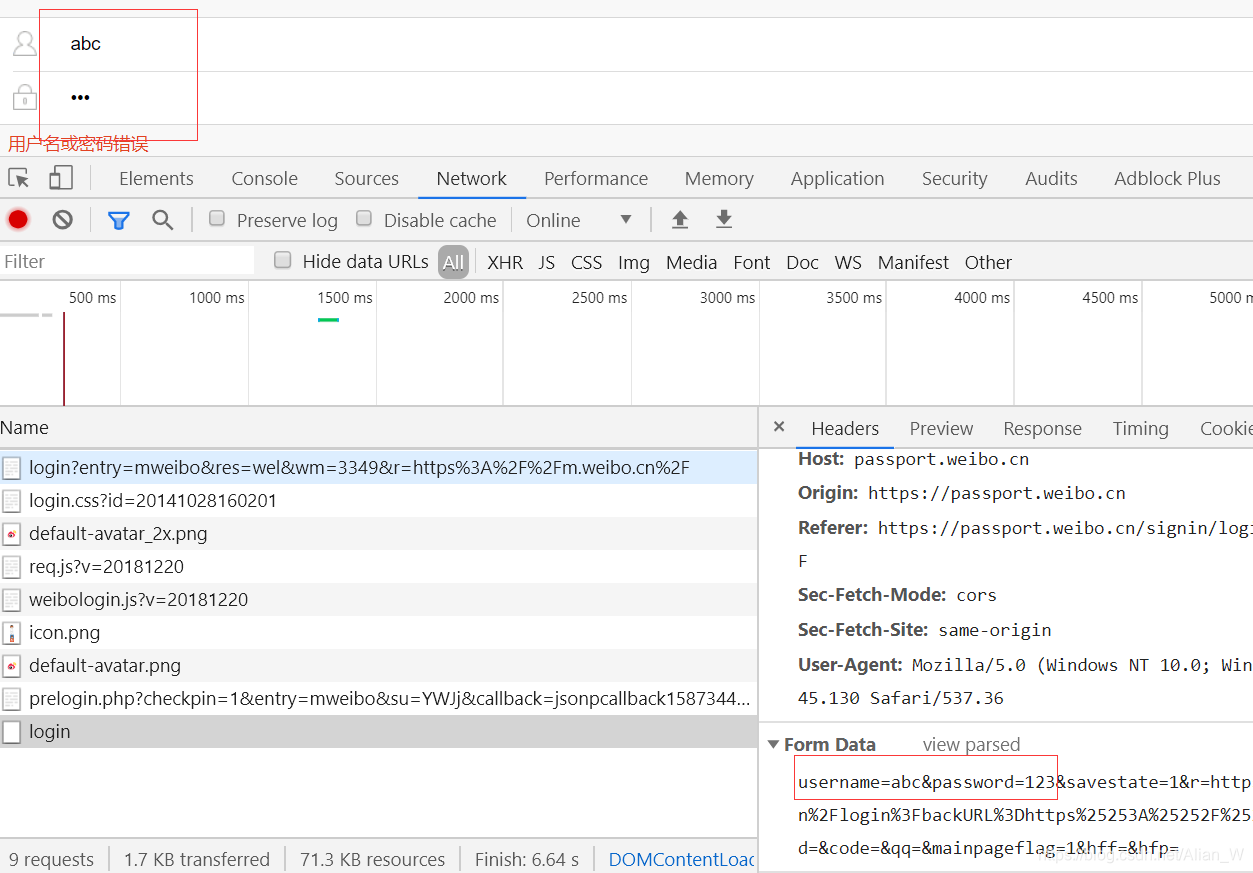
没办法,一般首选肯定是通过请求api传参然后获得cookie实现登录。现在只能使用selenium模拟登录了。微博移动端的元素比较少,所以就选择移动端作为模拟登陆的端口了。 URL为 https://passport.weibo.cn/signin/login,在实现微博登录后需要将其cookie保存下来用于第二次登录(当然也有cookie里带时间戳的,就需要另外攻克,先试试看)。这段代码比较简单,我直接贴出来。
from pymongo.errors import DuplicateKeyError
from selenium import webdriver
from time import sleep
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
import pymongo
class weibo():
def __init__(self, username, password):
self.username = username
self.password = password
self.chrome = webdriver.Chrome()
self.chrome.get('https://passport.weibo.cn/signin/login?display=0&retcode=6102')
def open(self):
sleep(1) # 沉睡一秒等页面刷新
username = self.chrome.find_element_by_xpath("//p/input[@id='loginName']").send_keys(self.username)
password = self.chrome.find_element_by_xpath("//p/input[@id='loginPassword']").send_keys(self.password)
submit = self.chrome.find_element_by_xpath("//a[@id='loginAction']")
submit.click()
def run(self):
self.open()
sleep(2)
if self.chrome.title == '请先验证身份':
# sleep(60 * 60)
check = self.chrome.find_element_by_xpath("//span[@class='geetest_radar_tip_content']")
check.click()
sleep(1)
WebDriverWait(self.chrome, 30).until(
EC.title_is("微博")
)
return self.chrome.get_cookies()
if __name__ == '__main__':
# 打开mongo
client = pymongo.MongoClient('127.0.0.1', 27017)
collection = client['weibo_mongo']['account_cookie']
# 从文件读取账号
with open('weiboxiaohao.txt', 'r') as f:
lines = f.readlines()
# 循环
for line in lines:
line = line.strip()
username = line.split("----")[0]
password = line.split("----")[1]
# 返回cookie
try:
cookie = weibo(username, password).run()
cookie_str = ''
for i in cookie:
name = i['name']
value = i['value']
cookie_str += name + '=' + value + '; '
print(cookie_str)
except Exception as e:
print(e)
continue
# 保存到mongodb
try:
collection.insert_one({'_id': username, "password": password, "cookie": cookie_str, "status": 1})
except DuplicateKeyError as e:
collection.find_one_and_update({'_id': username}, {'$set': {'cookie': cookie_str, "status": 1}})
因为可能会出发微博的验证码系统,所以还是需要打开浏览器来盯着,当账号池大的时候是相当麻烦的一个过程。所以也算一个遗憾吧。给大家找几个解决验证码的思路,英文数字验证码->打码平台/自己做文字识别,滑动宫格验证码都给碰上了?没事儿,看完此文分分钟拿下!。
微博多平台分析
既然实现了登录了,那么只需要在请求时带上cookie就可以了。所以接下来我们要找找获取用户基本公开信息的方法。微博共有三个站点,分别是3G版微博、移动端微博、PC版微博,我们选择对3G版来获取,因为3G版页面最简陋、而且由于网络原因限制他不可能携带太多js文件,所以对反爬虫力度应该是最小的。
说出来你可能不信,所以我们把三个站点的用户基本公开信息页面都找一找,对比一下:
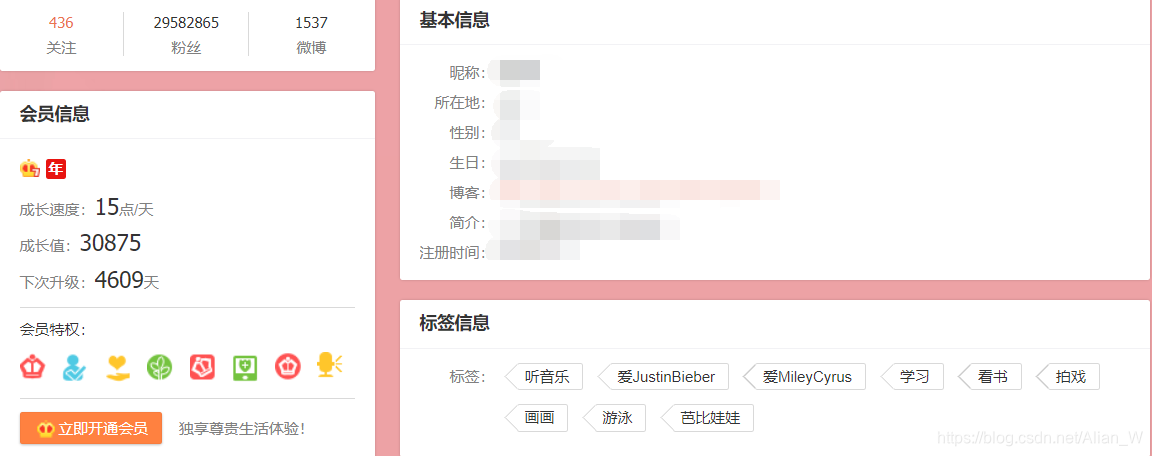
这是PC版微博用户详细信息页:
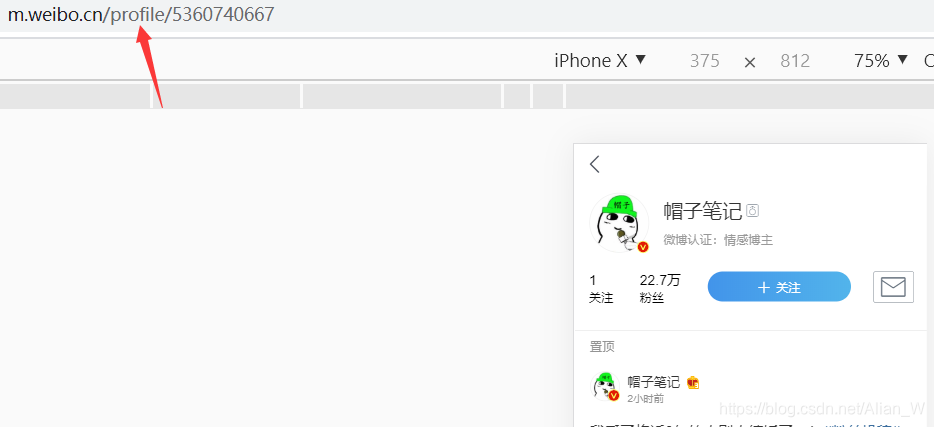
这是移动版微博:
这是3G版微博:
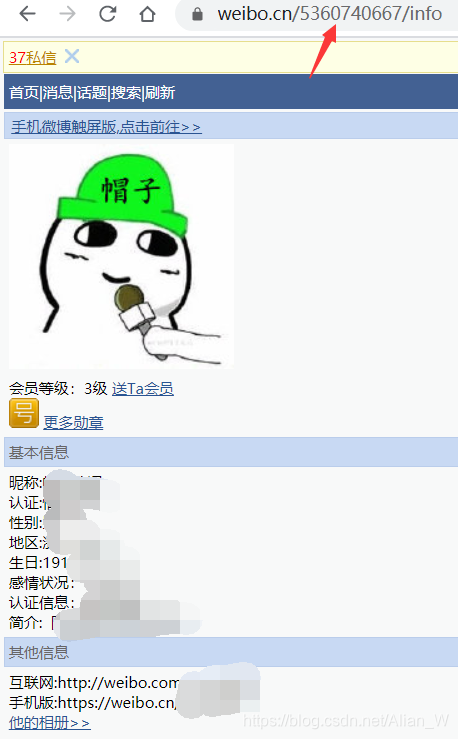
显然PC版跟3G版信息都差不多,而且3G版应该会好爬一点,所以还是选择3G版吧。那么有的朋友可能会问了,PC版还有关注数、粉丝数怎么办啊?不急,这两个字段基本上到处都是,不慌好吧。
微博个人信息抓取
分析完三个站点确定了要抓取3G版,那么接下来的工作就简单了,只需要请求到这个网页就能够使用xpath或者正则处理了。我使用的是scrapy框架进行抓取,因为之前做的一个链家二手房信息采集是自己做的小框架,写起来太累了。大致的原理都是一样的,接下来给大家看一下请求到手后解析信息的代码。
name = 'weibo_spider' # 爬虫名字
base_url = 'https://weibo.cn/' # 因为通过观察URL可以发现3G版的URL有一个base_url的存在
def start_requests(self):
start_uids = [
'6092239769', # 留一剪
'2803301701', # 人民日报
'1699432410', # 新华社
]
for uid in start_uids:
yield Request(url=self.base_url + "{}/info".format(uid), callback=self.parse_info)
def parse_info(self, response):
"""
解析微博号基本信息
包括:昵称 认证 性别 生日 认证信息 简介 标签 工作经历
然后进入其手机版微博首页 继续爬它发的微博
"""
info = InfoItem()
text = response.text
info['_id'] = re.findall('(\d+)/info', response.url)[0]
try:
info['hydj'] = re.findall('class="c">会员等级:(\d级)', text)[0] # 会员等级
except Exception as e:
info['hydj'] = '未开通'
info['nc'] = re.findall('class="c">昵称:(.+?)<br/>', text)[0] # 昵称
try:
info['rz'] = re.findall('认证:(.+?)<br/>', text)[0] # 认证
except Exception as e:
info['rz'] = None
info['xb'] = re.findall('性别:(.+?)<br/>', text)[0] # 性别
info['dq'] = re.findall('<br/>地区:(.+?)<br/>', text)[0] # 地区
try:
info['sr'] = re.findall('生日:(.+?)<br/>', text)[0] # 生日
except Exception as e:
info['sr'] = None
try:
info['rzxx'] = re.findall('认证信息:(.+?)<br/>', text)[0] # 认证信息
except Exception as e:
info['rzxx'] = None
try:
info['jj'] = re.findall('简介:(.+?)<br/>', text)[0] # 简介
except Exception as e:
info['jj'] = None
try:
bq_text = re.findall('<br/>标签:(.+)<br/>', text)[0]
info['bq'] = re.findall('">(.+?)</a>', bq_text)[:-1] # 标签
except Exception as e:
info['bq'] = None
try:
info['gzjl'] = re.findall('工作经历</div><div class="c">(.+?) <br/>', text) # 工作经历
except Exception as e:
info['gzjl'] = None
info['zy'] = "https://weibo.cn/u/{}".format(info['_id']) # 主页
request_meta = response.meta
request_meta['item'] = info
yield Request(url=self.base_url + 'u/' + info['_id'], callback=self.parse_private_weibo, meta=request_meta,
dont_filter=True)
大家可以看到因为scrapy需要一个start_url,所以我们抽出一个base_url然后通过拼接就可以访问到目标用户的详情页了。因为本项目最终的目标是实现微博全站信息获取,所以需要几个大V作为起始对象,然后通过大V的粉丝、关注列表可以获取其他用户,最终拼接成一套看不见的关系网,应该是不会遗漏什么用户的。
微博粉丝列表分析
在3G版下方可以看到有其他站点的链接,我们可以访问看看手机版有什么东西。
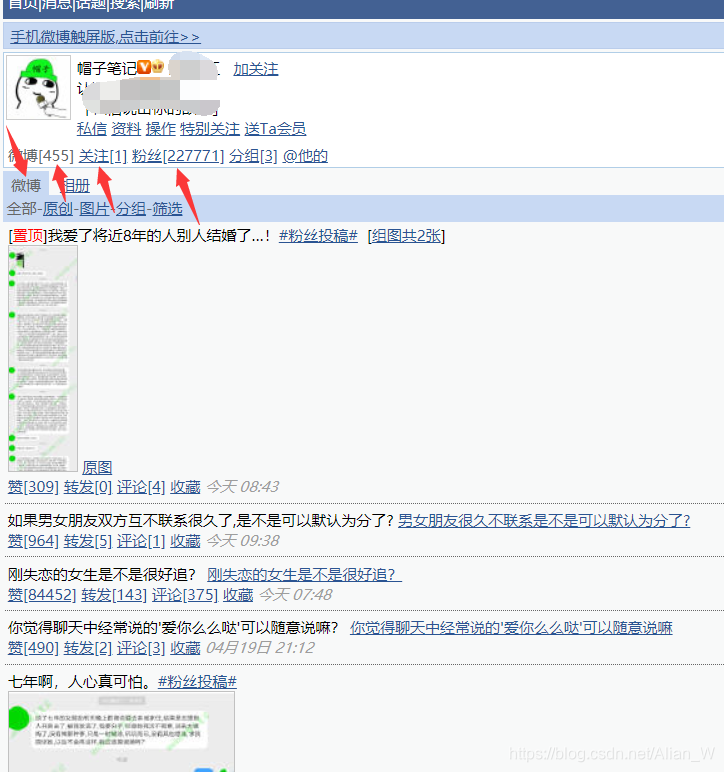
可以看到这是该用户的微博主页,里面包含的内容有发布的微博数、关注数、粉丝数、还有他发过的一些微博。多翻几页试试看,该用户共发了46页微博,好像没什么问题。多找几个大V试试,找了人民日报的微博,该用户共发布115920条微博,继续翻页发现翻到最末尾11590页也没什么问题。这时我们退出账号试试,发现退出账号后根本无法访问任何用户的信息,OK当然我们是带着cookie去访问的,影响不大。
继续翻粉丝列表,发现粉丝列表只能访问20页。这就有问题了,如果不能够从大V的粉丝列表中获取足够多的粉丝id,我们是无法拼凑够大的关系网的,也无法实现全站爬取。这时候需要从其他方向考虑了。
来到PC版看看,随便访问一个用户的fans列表https://weibo.com/5371249259/fans,在底部发现是翻页页脚,ok,试着访问最末尾,结果直接爆系统限制,上网查了一下说是非好友什么的只能访问几十页(好像大概50),这样是不行的,50页一页20个才一千人。
来到移动版看看,现在大家进入移动版微博可能显示在维护,不知道是不是接口被维护了。总之微博的api还是能访问的,https://m.weibo.cn/api/container/getIndex?containerid=231051_-_fans_-_{}&since_id={}这个是微博的粉丝列表api,第一个{}是用户的ID,这个ID可以在3G版找到,第二个{}就是index,通过这个since_id可以最多访问到250(亲测),每次返回20个粉丝,即最多可以获取5000个粉丝/用户。好像也不是很多,但是好像也没什么其他办法了,这可比3G版微博强太多了,而且从ajax访问返回的json数据效率可是高很多,保守估计只要程序能够稳定运行一天50W条数据应该不是问题(好卑微的梦想。。。)
这是当时在移动版微博下拉粉丝列表是ajax请求截图

可以看到有一个链接是可以找到当前页显示的信息的
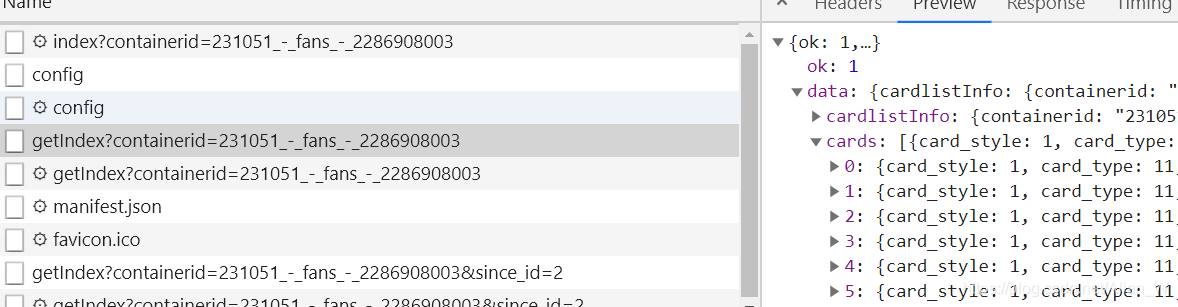
直接使用浏览器请求看看是什么情况(注意这里是不带cookie的)

可以看到即使不带cookie,也可以请求完整的粉丝列表,这可是个大宝藏。接下来就是分析这个返回的json串,看看能不能从中发现什么其他链接把。
结尾
OK,这篇微博初步分析就到这里,其实当时找到微博的这个api的时候我是很激动的,因为我知道只要拿到api相当于打开了对方的数据库一样,并且采集的效率会翻几倍的增长。但是由于中间因为个人原因拖了一些时间所以没能把博客出出来,实在是有点遗憾。这篇文章就使用价值来说其实已经因为微博这次更新大打折扣了,不过中间分析的过程还是有点价值的,我也会尽力还原当时的思路,让大家能够了解点什么,而不是吃瓜。
