新浪微博美女图片的爬虫
一 引言
由于毕设要获取微博上的一些数据,但是微博的openAPI不仅有次数限制,还不方便获取某一类别的数据,所以还是爬虫方便一些,自己需要什么数据就获取什么数据,不过能够调用API实现的还是调吧,毕竟微博的反爬机制还是很强的。作为新手就选择爬取手机网页的新浪微博,相对电脑网页上的反爬要好多了。
二 新浪微博的模型登陆
1、获取微博的验证码
微博的验证码没有那么好获取,经过对站点分析,在获取验证码的时候请求的数据有
“checkpin” “entry” “su” “callback”这四个参数,而su是经过base64对用户名加密的,callback则是对当前时间进行了变换。获取了验证码,自动识别验证码难度挺大,就选择人工识别并输入。
def login_pre(username, Session):
'''
获取验证码
'''
su = (base64.b64encode(quote_plus(username).encode('utf-8'))
).decode('utf-8') # 用户名用base64加密
pre_Data = {
"checkpin": '1',
"entry": 'mweibo',
"su": su,
"callback": 'jsonpcallback' + str(int(time.time() * 1000) + math.floor(random.random() * 100000))
}
pre_headers = headers.copy()
pre_headers['Host'] = 'login.sina.com.cn'
pre_headers['Referer'] = 'https://passport.weibo.cn/signin/login'
pre_url = 'https://login.sina.com.cn/sso/prelogin.php'
pre_text = Session.get(pre_url, params=pre_Data, headers=pre_headers).text
try:
pre_json = json.loads(pre_text[0])
if pre_json['showpin'] == 1: # 验证码
pre_headers['Host'] = 'passport.weibo.cn'
capt = Session.get(
'https://passport.weibo.cn/captcha/image', headers=pre_headers)
capt_json = capt.json()
capt_base64 = capt_json["data"]["image"].split('base64',)[
1] # captcha image
with open('../../data/weibo_data/captcha.png', 'wb') as f:
f.write(base64.b64encode(capt_base64))
f.close()
#img = Image.open('../../data/weibo_data/captcha.png')
#img.show()
#img.close()
captcha = raw_input('input captcha:\n>')
return captcha, capt_json["data"]["pcid"]
except Exception, e:
# print Exception, ':', e # no captcha
return ''2、模拟登陆获取cookie
这里主要是针对有验证码的时候,传入的参数。具体在下面代码里有说明,我想代码应该不难理解。
def login(username, password, Session, pincode):
'''
模拟登录手机端微博
'''
login_url = "https://passport.weibo.cn/signin/login"
data = {
'username': username,
'password': password,
'savestate': '1',
'r': 'http://m.weibo.cn/',
'ec': '0',
'pagerefer': login_url,
'entry': 'mweibo',
'wentry': '',
'loginfrom': '',
'client_id': '',
'code': '',
'qq': '',
'mainpageflag': '1',
'hff': '',
'hfp': '',
}
login_headers = headers.copy()
login_headers['Host'] = 'passport.weibo.cn'
login_headers['Accept-Encoding'] = 'gzip, deflate, br'
login_headers['Accept'] = '*/*'
login_headers['Origin'] = 'https://passport.weibo.cn'
login_headers['Referer'] = login_url
login_headers['Content-Type'] = 'application/x-www-form-urlencoded'
if pincode == '':
pass
else:
data['pincode'] = pincode[0]
data['pcid'] = pincode[1]
post_url = 'https://passport.weibo.cn/sso/login'
# Session.get(login_url)
slt = Session.post(post_url, data=data, headers=login_headers)
# print slt.status_code
# print slt.text
#login_js = slt.json()
#crossdomain = login_js['data']['crossdomainlist']
#cn = "https:" + crossdomain["sina.com.cn"]
#login_headers["Host"] = "login.sina.com.cn"
#Session.get(cn, headers=login_headers)
return Session
三 微博的json数据解析
当模拟登陆之后,我们就可以使用获取的session来访问其他页面,session中包含了登陆的cookie,python的session中一直带有cookie。下面的代码是根据链接获取此页面的json数据。
first_url="https://m.weibo.cn/api/container/getIndex? uid=3283836867&luicode=10000011&lfid=100103type%3D3%26q%3D
%E5%8C%97%E7%94%B5%E4%B8%AD%E6%88%8F%E7%9A%84%E7%BE%8E%
E5%A5%B3%E4%BB%AC&featurecode=20000320&type=uid&value=32
83836867&containerid=1076033283836867"
json_data = session.get(first_url)
json_data = json_data.json()
看代码中使用的first_url怎么来的呢?打开浏览器按F12,然后监控网络。刷新页面,就可以看到了,然后找哪些是请求的数据页面,就可以找到
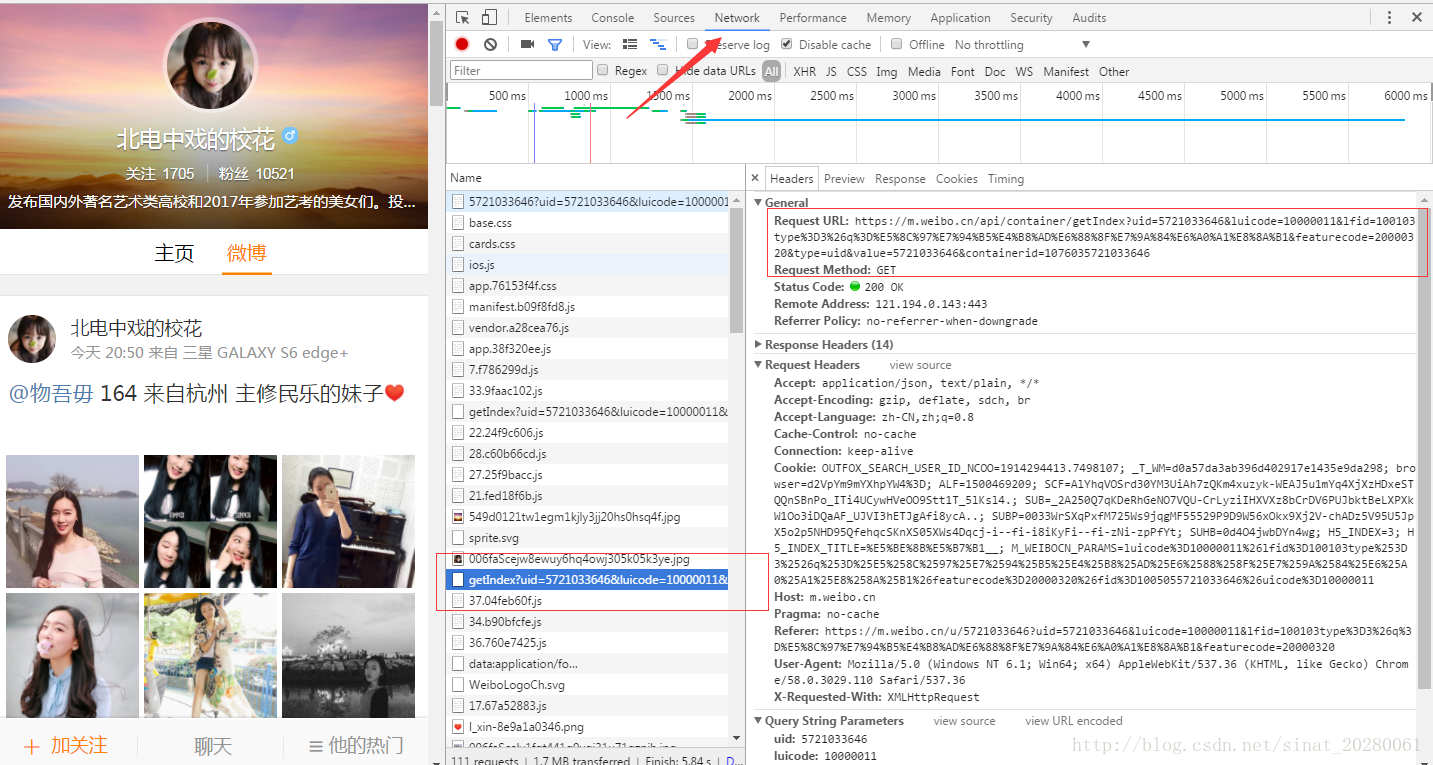
获取了数据之后,我们需要对json数据进行解析啊。可以输出json_data查看json数据,但是麻烦,直接复制那个first_url到浏览器中,即可获得页面的json数据。然后我们在json.cn这个网站在线解析json数据,如下图
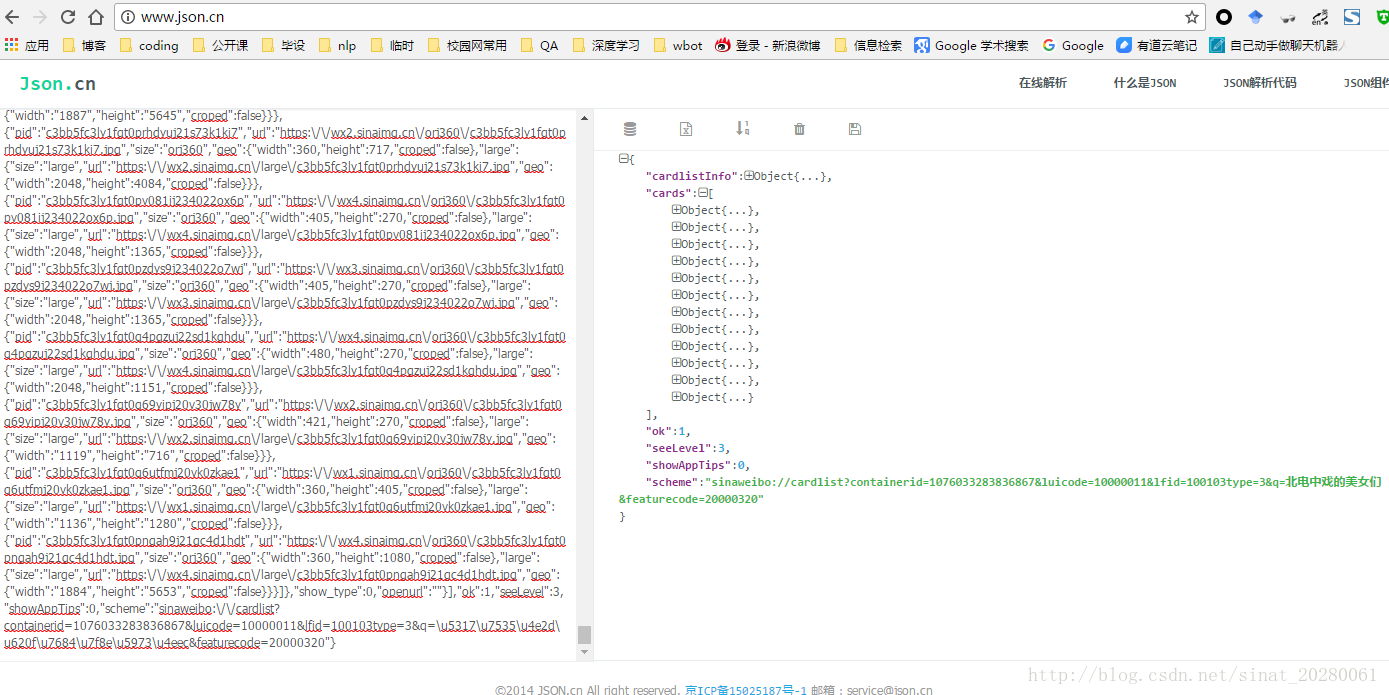
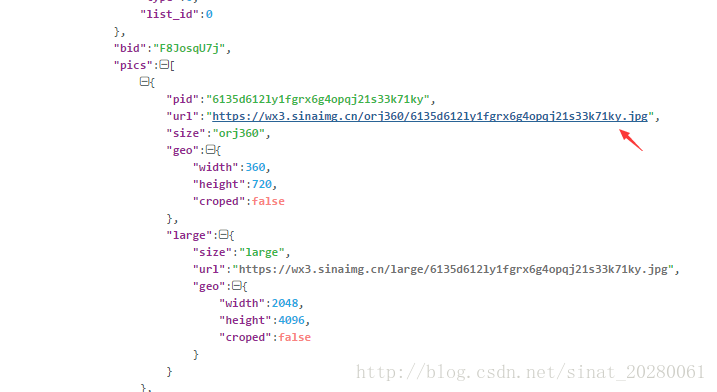
通过层层的展开,我们可以在cards->列表中的一项->mblog->retweeted_status->pics中找到妹纸照片的链接,然后访问即为妹纸照片哦!
四 图片下载
在获取照片链接之后,我们只需要下面一个简单的程序就可以将照片保存到本地哦!这里的picture_count只是为了给照片命名方便,不过记得每次存完之后要变化,否则都存在一张里面那就只有一张。
picture = session.get(pic_url)
with open("picture/"+str(picture_count)+".png",'wb') as f:
picture_count+=1
f.write(picture.content)
f.close五 结果展示
随便一运行,就有万张美女照片!