最近花了不少时间来学python爬虫,觉得还是有很多问题的,比如说requests.get获得Pixiv的网页源代码,一直获取不到,不过我猜测大概是headers的问题,准备之后处理。
废话少说我们先来讲一讲模拟登陆微博的问题。
第一步:用Chrome来抓包
打开微博(https://www.weibo.cn,这个是手机微博的网址,之所以用这个网址,是因为源代码少,方便分析)
点击登陆
在这里按F12查看网页源代码,选择network,把preserve log勾上,然后右击name把method勾上。
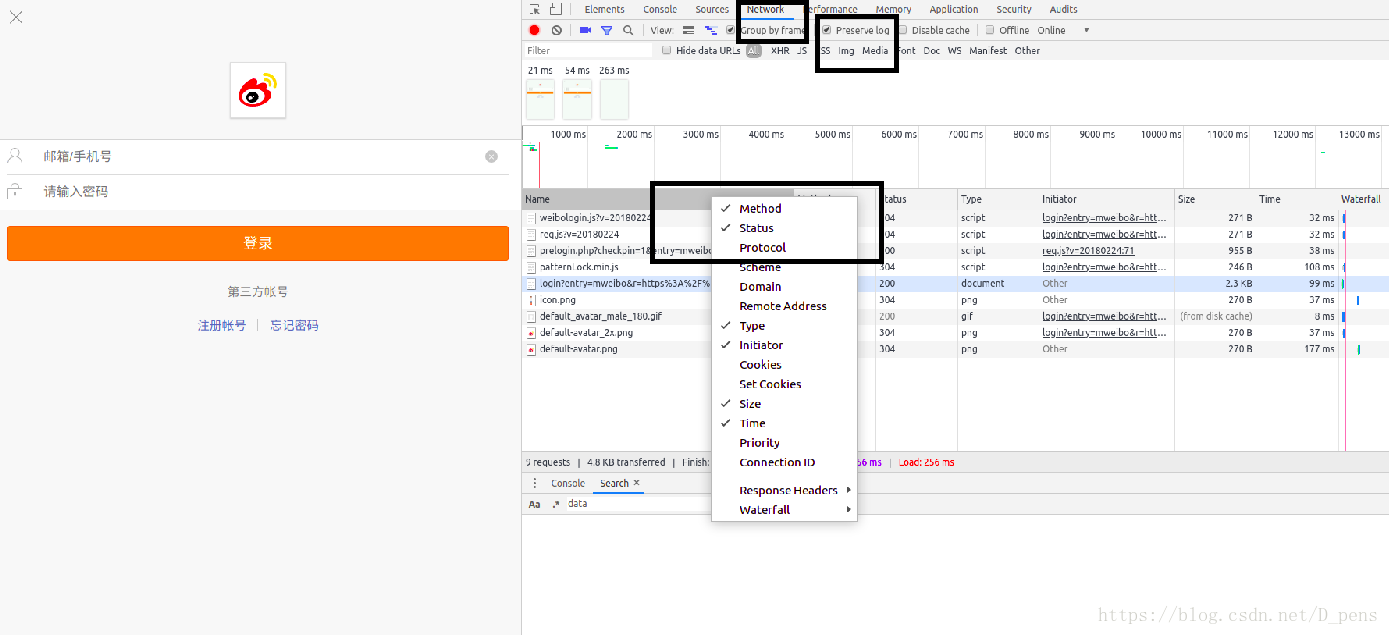
输入账号密码登陆
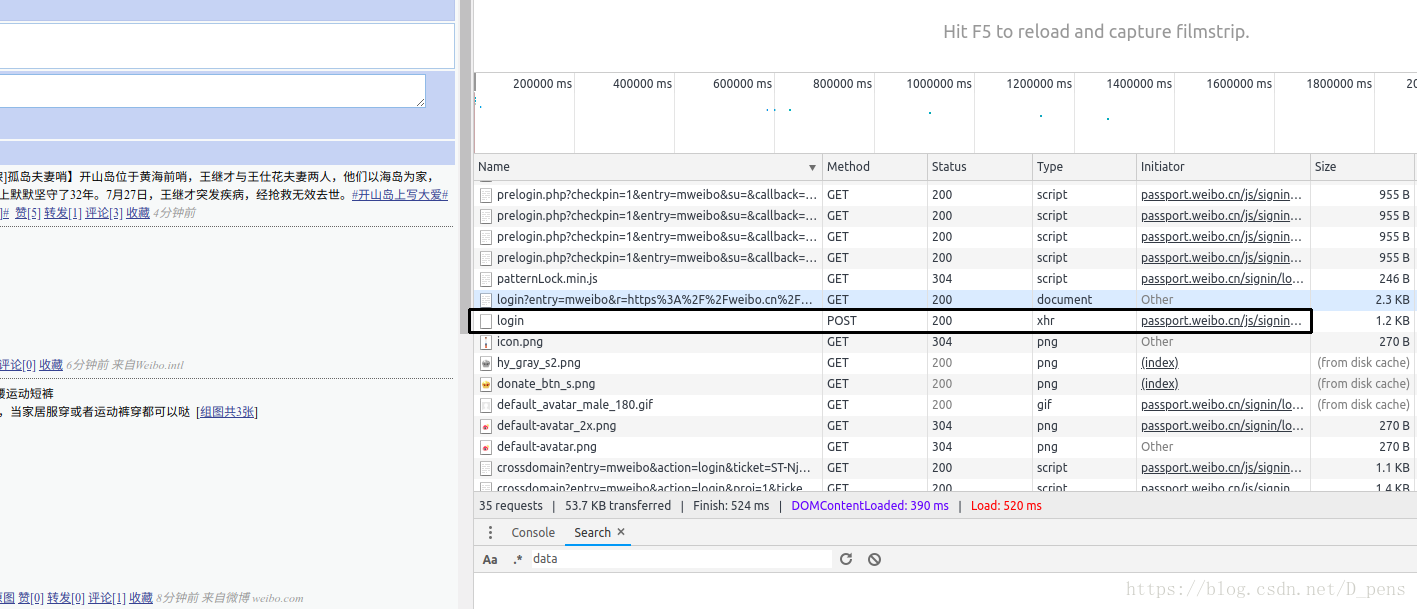
找到method为POST的那一行,然后点击
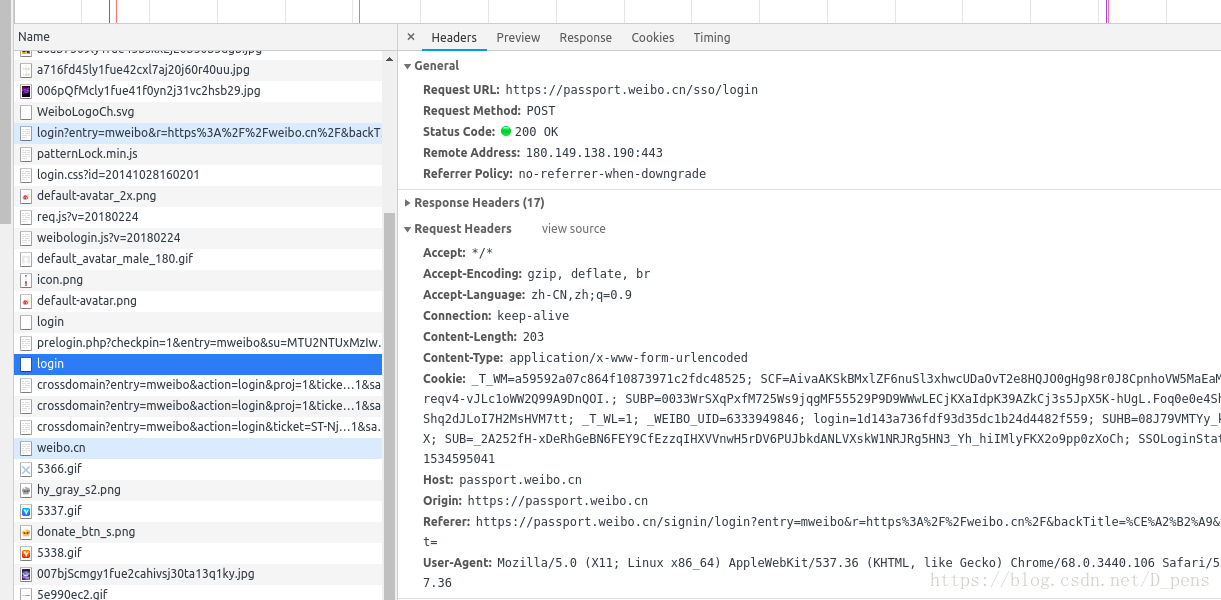
这里有一些我们需要的信息,首先是Request URL,这个是表单提交的地址,我们的数据就是发送到了这里。
然后就是Request headers,这里也有一些有用的东西,虽然说只有User-Agent是必需的,但在实际操作中发现还需要Accept,Accept-Encoding,Accept-Language,Connection,Origin,Referer。那我全都要不就行了,然而加了Content-Length,Content-Type,Host就出现了Bug,我也不知道是为什么,有兴趣的朋友可以去查一查。
然后就是form data了
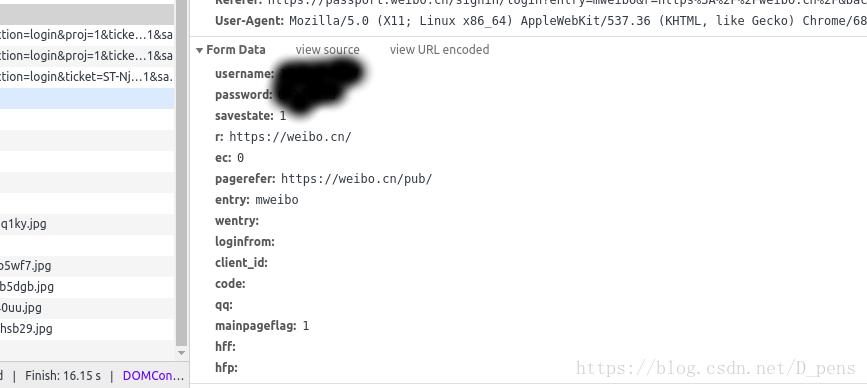
除了没有值的都需要。
好了,前期工作都完成了。
第二步:代码部分
终于完成了前期准备,我直接上代码。
import requests
user = '你的账号'
password = '你的密码'
user_headers = {
'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36',
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Origin': 'https://passport.weibo.cn',
'Referer': 'https://passport.weibo.cn/signin/login?entry=mweibo&r=https%3A%2F%2Fweibo.cn%2F&backTitle=%CE%A2%B2%A9&vt='
}
login_data = {
'username': user,
'password': password,
'savestate': '1',
'r': 'https://weibo.cn/',
'ec': '1',
'pagerefer': 'https://weibo.cn/pub/',
'entry': 'mweibo',
'mainpageflag': '1'
}
session = requests.Session()
session_url = 'https://passport.weibo.cn/sso/login'#这里是抓包时得到的地址,不是登陆页的地址
response = session.post(session_url, headers = user_headers, data = login_data)
url='https://weibo.cn/6333949***'#注意这里的网址不是https://weibo.cn,要加上你点开个人资料后那个地址中间那串数字,不然你打印出来的还是登陆页的源码。
html=session.get(url,headers=user_headers).content
print(html)
登陆的关键是session,session会把cookies保存下来,这样在cookies失效之前,你都可以访问微博而不需要再次POST表单。就比如倒数第二行代码,如果没有session,你会获得登陆页的源码,而不是登陆后网页的源码。