爬虫任务:
爬取粉丝数量,超话粉丝,阅读量,排名,帖子数量
由此可见主要需要两个网址,一个是微博主页,一个是超话主页
爬取
个人比较喜欢模拟浏览器爬取,以前有文章写过,不过这里并不是非要模拟浏览器。爬取建议大家用手机端的网址(网页结构比较简单)
网址是:https://m.weibo.cn
爬取主页
进入到要爬取人的主页:在搜索框输入,然后查找

这个粉丝数量就是我们要获取的目标
F12进入开发者模式,点击小箭头,点击粉丝数
可以看到对应的位置
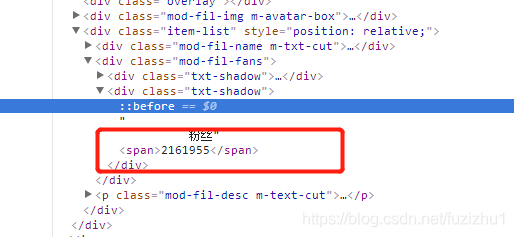
右键点击span标签,复制selector即可获取到粉丝数
text = browser.find_element_by_css_selector('#app > div:nth-child(1) > div:nth-child(1) > div:nth-child(1) > div > div.item-list > div.mod-fil-fans > div:nth-child(2)')
nums = text.text
爬取超话
基本同理,如果你想爬取的人有超话,记录网址,然后进入网址,找到对应元素
text = browser.find_element_by_css_selector('#app > div:nth-child(1) > div:nth-child(1) > div.page-cover > div.cover-wrap.bar > div > div > div > a > div:nth-child(2) > h4:nth-child(1)')
rank= browser.find_element_by_css_selector('#app > div:nth-child(1) > div:nth-child(1) > div.page-cover > div.cover-wrap.bar > div > div > div > div > div > div').text
分别对应下面两个元素

如果想要把文字去掉,还有阅读,帖子,粉丝单独显示,用正则,我有些时间的话简单说一下。
最后我的效果大概是这样
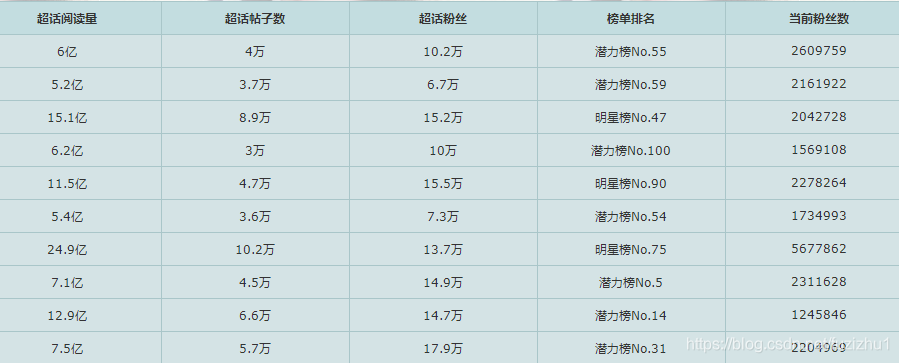
我是部署在阿里云服务器上的,大概就是这么一个效果,五分钟更新一次