版权声明:版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_42658739/article/details/91357810
思路:
【郑重说明,少量爬取公开数据仅供分析以及爬虫学习使用】
1.确定起始URL:https://search.51job.com/list/000000,000000,0000,00,9,99,%E5%A4%A7%E6%95%B0%E6%8D%AE,2,1.html
2.观察网页内容:
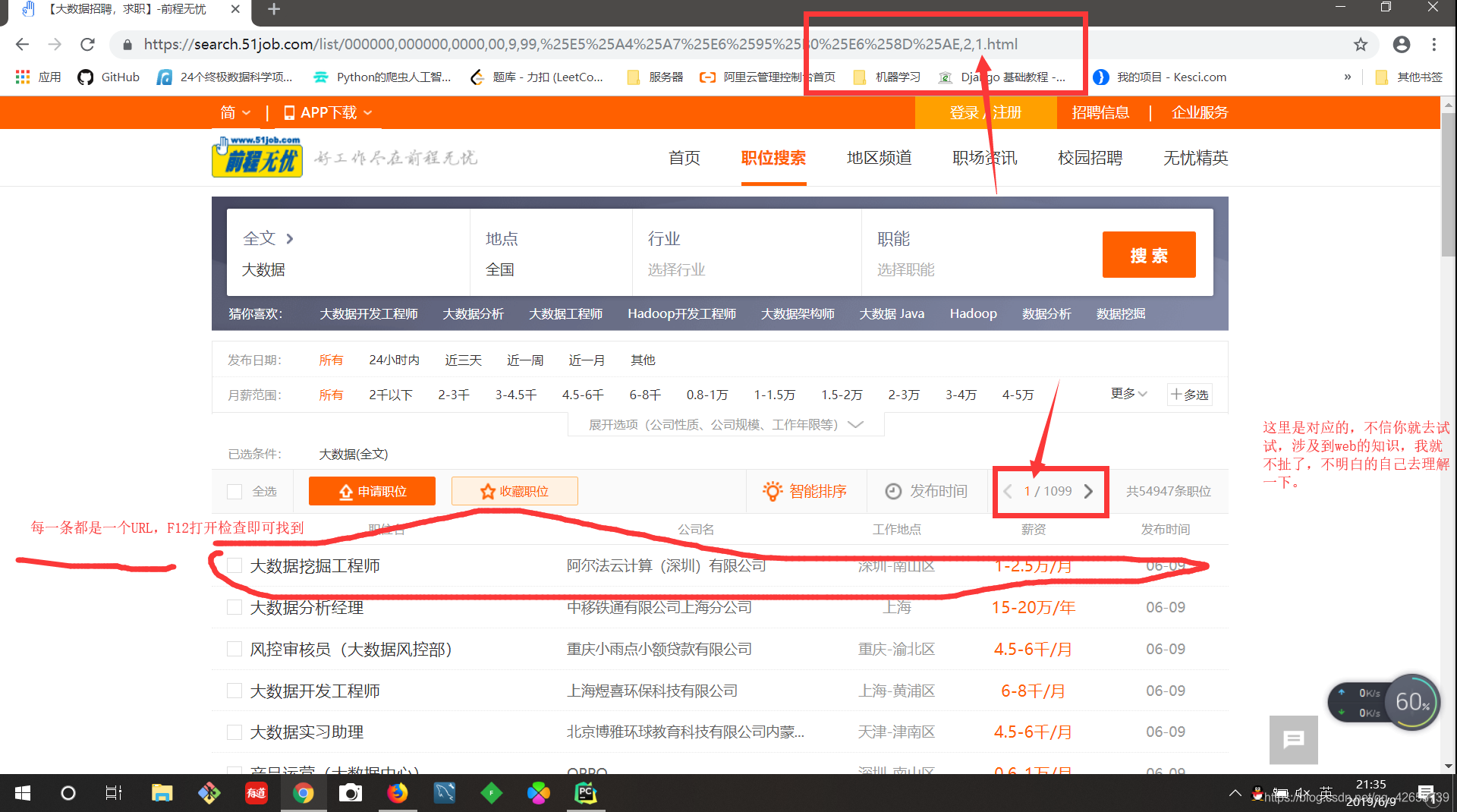
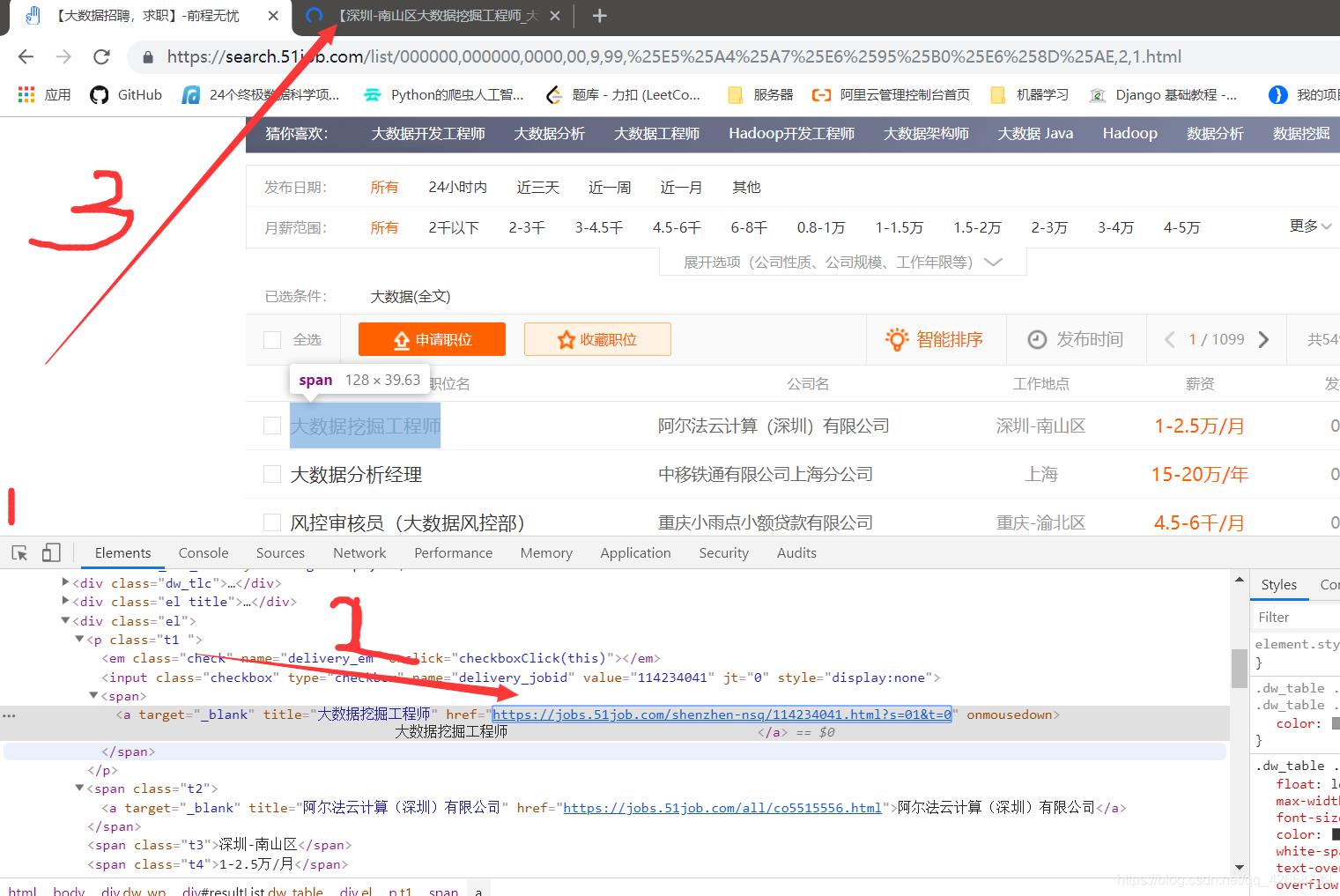
3.寻找字段

4.完整代码
注释代码里面,很好理解
# -*- coding: utf-8 -*-
# @Time : 2019/6/5 18:45
# @Author : baby
# @File : get_51.py
import requests
from lxml import etree
import pandas as pd
import logging
class Job:
def __init__(self):
self.headers = {'User-Agent':'换成你自己的'}
def get_URL(self):
logging.captureWarnings(True)
file_List = []
for i in range(1,4): #215
start_urls = 'https://search.51job.com/list/000000,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE%25E6%258C%2596%25E6%258E%2598,2,{}.html'.format(i)
response = requests.get(start_urls, headers=self.headers, timeout=10,verify=False)
response.encoding = 'gbk'
if response.status_code == 200:
print("主页start_urls爬取成功,等待解析:",start_urls)
HTML = etree.HTML(response.text)
job_URL = HTML.xpath('//div[@id="resultList"]/div[@class="el"]/p/span/a/@href')
for url in job_URL:
html = requests.get(url, headers=self.headers,verify=False,timeout=5)
if html.status_code == 200:
print("爬取当前岗位成功:", url)
html.encoding = 'gbk'
job_html = etree.HTML(html.text)
#---
if job_html.xpath('//div[3]//div[@class="cn"]/h1/@title'):
jobName = str(job_html.xpath('//div[3]//div[@class="cn"]/h1/@title')[0]) # 工作岗位
else:
jobName = 'nan'
#---
if job_html.xpath('//div[@class="cn"]/strong/text()'):
jobSalary = str(job_html.xpath('//div[@class="cn"]/strong/text()')[0]) # 薪水
else:
jobSalary = 'nan'
#---
if job_html.xpath('//div[@class="cn"]/p[@class="msg ltype"]/@title'):
job_item = job_html.xpath('//div[@class="cn"]/p[@class="msg ltype"]/@title')[
0] # pattern = re.compile(r'(\S+)\s*\|')
conten_List = str(job_item).split("\xa0\xa0|\xa0\xa0")
jobPlace = str(conten_List[0]) # 工作地点
jobExperience = str(conten_List[1]) # 工作经验
jobEducation = str(conten_List[2]) # 教育要求
jobNumber = str(conten_List[3]) # 招收人数
else:
jobPlace = 'nan' # 工作地点
jobExperience = 'nan' # 工作经验
jobEducation = 'nan' # 教育要求
jobNumber = 'nan' # 招收人数
#---
if job_html.xpath('//div[@class="bmsg job_msg inbox"]/p/text()'):
job_Imformation_List = job_html.xpath('//div[@class="bmsg job_msg inbox"]/p/text()')
jobSkills = ''
for i in range(0, len(job_Imformation_List)):
jobSkills = jobSkills + str(job_Imformation_List[i]) + '\n' # 工作技能要求
else:
jobSkills = 'nan'
#---
file_List.append([jobName,jobSalary,jobPlace,jobExperience,jobEducation,jobNumber,jobSkills])
# yield file_List
else:
# print("当前页爬取失败进入下一页")
pass
return file_List
def save_File(self):
self.itemName = ['职位名','薪资','工作地点','工作经验','学历','招牌人数','招牌条件']
file_List = Job.get_URL(self)
df = pd.DataFrame(file_List)
df.to_excel('data1.xlsx',header=self.itemName)
print("文件保存完成!")
if __name__ == '__main__':
j = Job()
j.save_File()