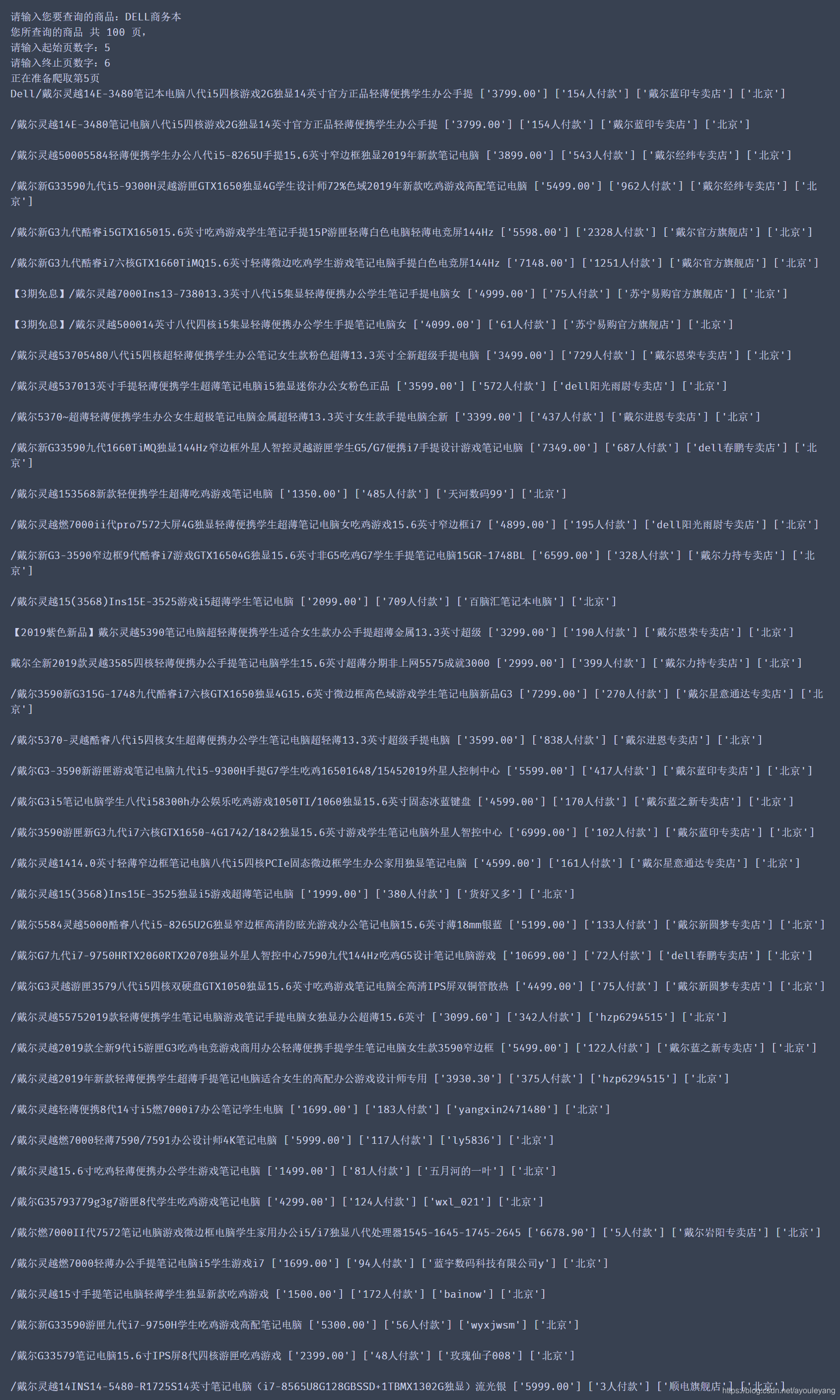
淘宝网: 淘宝网是亚太地区较大的网络零售、商圈,由阿里巴巴集团在2003年5月创立。淘宝网 是中国深受欢迎的网购零售平台,拥有近5亿的注册用户数,每天有超过6000万的固定访客,同时每天的在线商品数已经超过了8亿件,平均每分钟售出4.8万件商品。随着淘宝网规模的扩大和用户数量的增加,淘宝也从单一的C2C网络集市变成了包括C2C、团购、分销、拍卖等多种电子商务模式在内的综合性零售商圈。目前已经成为世界范围的电子商务交易平台之一。
淘宝官网: https://taobao.com/
注册/登录淘宝: https://login.taobao.com/member/login.jhtml
操作环境: python3.6+jupyter notebook,win10,goole
技术难点:
- 模拟登录
- 跳过滑块验证
实现步骤讲解
1、模拟登录
1.1、为什么要模拟登录?
淘宝商城的商品信息可以说要比京东商城多一些保护,京东商城可以直接搜索商品进行下拉加载数据进行爬取信息,但是淘宝不让直接搜索商品,必须要登录后才能查看商品。
1.2、模拟登录方式
- 可以直接使用淘宝的账号登录
直接使用淘宝账号登录,平时普通的登录可以直接登录,但是使用selenium模拟登录时需要进行进行滑块验证 - 支付宝登录
- 第三方登录(微博)
需要进行验证码验证才能登录 - APP扫码登录
也需要使用滑块验证,但是可以使用IP模拟用户访问跳过滑块
1.3、模拟扫码登录
#跳过滑动验证
chrome_option = webdriver.ChromeOptions()
chrome_option.add_argument('--proxy--server=127.0.0.1:8080')#使用IP地址
2、选取爬取页数
2.1、为什么要选取爬取的页数,而不是全部爬取?
- 淘宝使用模糊可重复搜索,随便提供一个词都可以查找的几十页的商品信息,后面的很多商品都会和前面的商品重复,全部爬取的数据价值不大。
- 全部爬取技术更容易实现,学习的技术价值也不大。
- 使用选取片段获取数据更方便
2.1、定点具体页数
搜索商品后,下拉网页到底部,我们可以看到进行切换页面的按钮
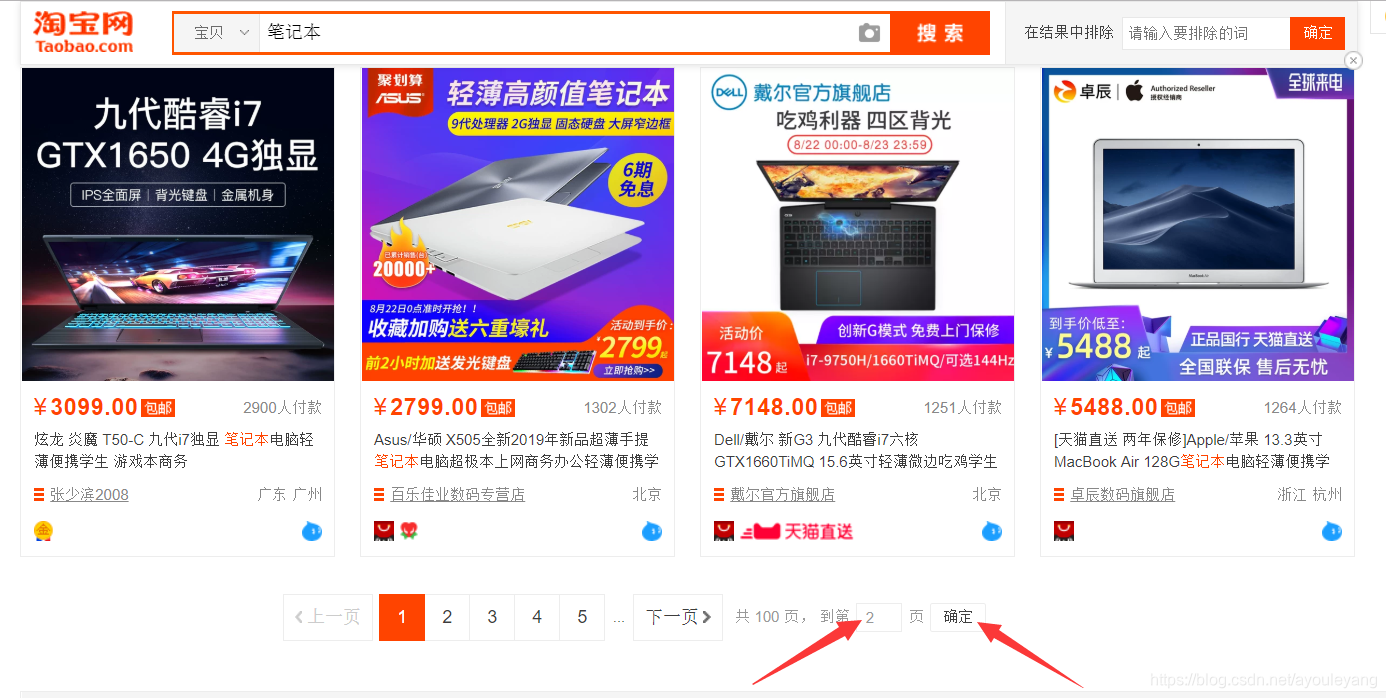
我们在这个框内输入要跳转到的页数,点击“确定”就可以跳转了。
实现逻辑: 找到搜索框—>清空—>输入数字—>确定
search = driver.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[2]/input')#找到搜索框
time.sleep(2)
search.clear()#清空搜索框
time.sleep(1)
search.send_keys(num)#输入数字
driver.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[2]/span[3]').click()#点击确定按钮
2.2、定点片段页数
global starPage
global endPage
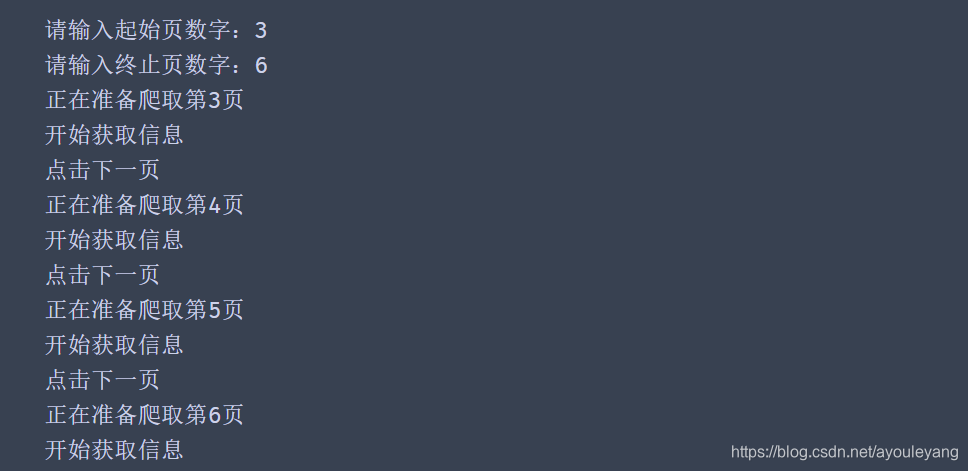
starPage = int(input("请输入起始页数字:"))
endPage = int(input("请输入终止页数字:"))
def start():
global starPage
global endPage
for num in range(starPage,endPage+1):
print ("正在准备爬取第%s页"%num)
spider()
if num < endPage:
nextPage()
def nextPage():
print("点击下一页")
def spider():
print("开始获取信息")
if __name__ == '__main__':
start()
逻辑结果:
3、源码汇总
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from lxml import etree
import time
things = input("请输入您要查询的商品:")
driver = webdriver.Chrome()
driver.implicitly_wait(5)
driver.get('https://login.taobao.com/member/login.jhtml')
# 等待扫码登录
time.sleep(10)
def scan_login():
#跳过滑动验证
chrome_option = webdriver.ChromeOptions()
chrome_option.add_argument('--proxy--server=127.0.0.1:8080')#使用代理IP,告诉服务器这是人为操作
search = driver.find_element_by_xpath('//*[@id="q"]') #在kw内输入
search.send_keys(things)#获取输入的商品
time.sleep(2)
search.send_keys(Keys.ENTER)#按回车
time.sleep(4)#大约加载4秒
maxPage = driver.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[1]').text #查找到商品的最大页数
print ("您所查询的商品",maxPage)
def start(starPage,endPage):#选择商品页数片段
for num in range(starPage,endPage+1):
print ("正在准备爬取第%s页"%num)
js="document.documentElement.scrollTop=4950"#下拉加载
driver.execute_script(js)
driver.implicitly_wait(5)
search = driver.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[2]/input')#获取输入页数框
time.sleep(4)
search.clear()#清空内容
time.sleep(1)
search.send_keys(num)
time.sleep(3)
spider()
if num < endPage:#当输入页数小于终止页时可以跳转到下一页
nextPage()
def nextPage():
driver.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[2]/span[3]').click()#点击确定,跳转页数
def spider():
time.sleep(5)
source = driver.page_source#获取网页源码
html = etree.HTML(source)#解析源网页
for et in html.xpath('//*[@id="mainsrp-itemlist"]/div/div/div[1]/div'):
names = et.xpath('./div[2]/div[2]/a/text()')
name = (str(names)).replace(" ","").replace("'","").replace(",","").replace("[\\n\\n\\n\\n","").replace("\\n]","").replace("[\\n\\n","")
#// 双斜杠可以表明转译符
price = et.xpath('./div[2]/div/div/strong/text()')
buy = et.xpath('./div[2]/div[1]/div[2]/text()')
store = et.xpath('./div[2]/div[3]/div[1]/a/span[2]/text()')
location = et.xpath('//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[5]/div[2]/div[3]/div[2]/text()')
print (name,price,buy,store,location,'\n')
if __name__ == '__main__':
scan_login()
starPage = int(input("请输入起始页数字:"))
endPage = int(input("请输入终止页数字:"))
start(starPage,endPage)
爬取部分结果: