多进程爬取淘宝商品信息
爬取思路、策略:一开始试着通过抓包模拟请求来爬取淘宝,但是淘宝返回的数据并不全是正确的,即通过返回真和假数据来达到反爬的目的,上网查资料也没多少是涉及到直接抓包请求爬取淘宝的,就这样自己瞎琢磨了一阵子后还是没有弄明白如何破解淘宝的反爬,于是决定采用selenium无头浏览器先实现爬取淘宝商品信息的目的,往后会继续来填这个坑。
采用selenium无头浏览器,完全模拟浏览器人为操作,故淘宝的反爬策略在它面前就束手无策了,但爬取效率还是没有直接请求url的逆向分析方式快,为了提高爬取效率,采取多进程爬取,之所以采用多进程而不是多线程,是因为打开多个浏览器同时运行是个CPU密集型操作,而不是I/ O密集型操作,故选择了多进程爬取,爬取流程图如下:
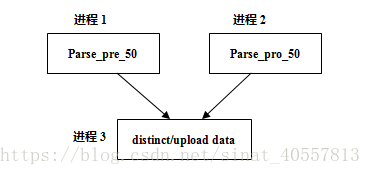
起初打算只采用两个进程爬取,但发现淘宝商品展示有重复现象,而且去重对于爬虫来说也是必要的,这里采用将商品ID的MD5压缩数据放入一集合set()中判断是否重复,从而达到去重的目的,利用一个进程来实现统一去重和上传数据,而且必须将去重和爬取分开进程执行,因为多进程是在独立的虚拟内存中运行的,两个爬取进程都产生一个集合set()用来去重,就无法达到统一去重的目的,这样去重效果会大大减低,故需要单独一进程来执行去重操作。
最后想谈谈多线程/多进程:由于python中全局解释器锁(GIL)的存在,在任意时刻只允许一个线程在解释器中运行,因此python的多线程不适合处理cpu密集型的任务。想要处理CPU密集型任务,可以使用多进程模型;多个进程之间,使用的虚拟地址空间是独立的,只能通过Queue、Pipe来互相通信,这也是爬虫中考虑采用单独一个进程来去重的原因。而多进程间的同步和停止也是很关键的,若要判断进程是否该停止,队列的empty()方法应该尽量少用,因为你不知道是否还有数据等待着put到队列中,所以会容易产生误判;要判断进程停止,可以在数据插入队列最后插入一结束标示符,一旦其他进程检测到这个结束标示符,结束进程。
上面是纯文字描述,下面就该是code了。
爬取前50页:
def parse_pre_50page_product(self , queue):
options = Options()
options.add_argument('-headless')
driver = Firefox(executable_path='D:\SeleniumDriver\geckodriver.exe', firefox_options=options)
wait = WebDriverWait(driver, timeout=20)
# 搜索关键字
driver.get('https://www.taobao.com/')
wait.until(expected.visibility_of_element_located((By.CSS_SELECTOR, '.search-combobox-input-wrap input'))).send_keys('充电宝')
wait.until(expected.visibility_of_element_located((By.CSS_SELECTOR, 'button.btn-search.tb-bg'))).click()
print('---------------process 1 is running--------------')
for i in range(50):
page_num = i+1
current_url = driver.current_url
#点击下一页
try:
driver.get(current_url)
print('Click the next page')
wait.until(expected.visibility_of_element_located((By.CSS_SELECTOR, '.item.next a.J_Ajax.num.icon-tag'))).click()
except:
print('no page to next')
break
# time.sleep(5)
print('--------------parse {}nth page product--------------'.format(page_num))
# 加锁,是为了防止散乱的打印。 保护一些临界状态
# 多个进程运行的状态下,如果同一时刻都调用到parse,那么显示的打印结果(数据处理结果)将会混乱
# lock.acquire()
self.parse(driver.page_source , queue)
# lock.release()爬取后50页:
def parse_pro_50page_product(self , queue):
options = Options()
options.add_argument('-headless')
driver = Firefox(executable_path='D:\SeleniumDriver\geckodriver.exe', firefox_options=options)
wait = WebDriverWait(driver, timeout=20)
# 搜索关键字
driver.get('https://s.taobao.com/search?q=%E5%85%85%E7%94%B5%E5%AE%9D&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.2&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=-141&ntoffset=-141&p4ppushleft=1%2C48&s=2156')
print('------------process 2 is running--------------')
for i in range(50 , 100):
page_num = i+1
current_url = driver.current_url
#点击下一页
try:
driver.get(current_url)
print('Click the next page')
wait.until(expected.visibility_of_element_located((By.CSS_SELECTOR, '.item.next a.J_Ajax.num.icon-tag'))).click()
except BaseException as e:
print('no page to next or' , e)
break
# time.sleep(5)
print('-------------parse {}nth page product------------'.format(page_num))
# lock.acquire()
self.parse(driver.page_source , queue)
# lock.release()
if page_num == 100:
print('parse product completed!')
queue.put('StopProcess')解析商品信息:
# 解析商品信息
def parse(self , page_source , queue):
match_obj = re.search('g_page_config = (.*).*', page_source)
if match_obj:
info_match = match_obj.group(1)
info_match = info_match.replace(';', '')
info_dict = json.loads(info_match)
product_items = info_dict['mods']['itemlist']['data']['auctions']
for product in product_items:
title = product['raw_title']
price = float(product['view_price'])
detail_url = product['detail_url']
# detail_url_md5 = self.MD5(detail_url)
product_ID = product['nid']
product_ID = self.MD5(product_ID)
shop = product['nick']
comment_count = product['comment_count']
if comment_count:
comment_count = int(comment_count)
else:
comment_count = 0
view_sales = product['view_sales']
match_obj = re.match('(\d+)人付款' , view_sales)
if match_obj:
view_sales = int(match_obj.group(1))
else:
view_sales = 0
comment_url = product['comment_url']
if comment_url:
comment_url = comment_url
else:
comment_url = None
title_gbk = title.replace(u'\u2705', u' ') #去掉gbk无法解码的符号
title_gbk = title_gbk.replace(u'\u2708', u' ')
try:
print('parsing the product:' , title_gbk)
except UnicodeEncodeError as e:
print('error:' , e)
params = (title_gbk , price , product_ID , detail_url , shop , comment_url , comment_count , view_sales)
queue.put(params)去重和上传数据:
#多进程间统一去重
def delDuplicate(self , queue):
save_flag = 0
while True:
save_flag += 1
# if queue.empty():
# time.sleep(20)
# if queue.empty():
# break
params = queue.get()
if params == 'StopProcess':
queue.put('StopProcess')
break
product_ID = params[2]
print('Deleting duplicate data')
if product_ID in self.Unduplicate:
continue
else:
self.Unduplicate.add(product_ID)
self.insert_to_mysql(params)
if save_flag % 100 == 0:
with open('Unduplicate.taobao', 'w') as wf:
wf.write(str(self.Unduplicate))
with open('Unduplicate.taobao', 'w') as wf:
wf.write(str(self.Unduplicate))
def insert_to_mysql(self , params):
insert_sql = '''
insert into TaobaoProduct values (%s , %s , %s , %s , %s , %s , %s , %s)'''
self.cursor.execute(insert_sql , params)
self.conn.commit() #执行完这条语句后数据才实际写入数据库
print('Insert to mqsql,succeed!')爬取的数据:
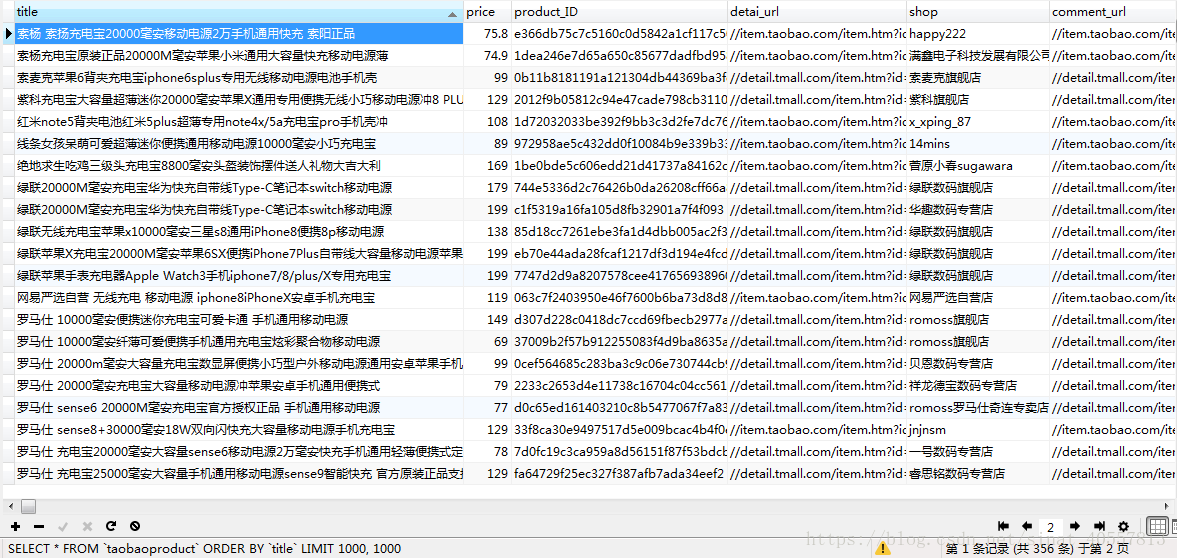
所遇到的问题也就是如何统一进行去重和多进程间的处理上