Attention Guided Anomaly Detection and Localization in Images
摘要
这篇论文的工作着手解决“异常的检测和定位(Anomaly detection and localization)”问题,这个task的challenge有两点,1.真实场景下异常样本非常少 2.图像中异常位置像素覆盖面积很小。之前的工作need(后面多次提到)训练异常帧来计算出检测和定位的阈值。为了去掉这个need(motivation),作者提出一种“基于引导注意的卷积对抗性变分自编码器(CAVGA)”,这个模型通过卷积隐藏变量来保存空间信息完成异常的定位。在无监督模式下,作者提出一个“注意扩张损失(attention expansion loss)”,期望在不使用异常图像训练情况下,模型的注意能够关注图像的所有正常区域。此外,在弱监督模式下,仅使用占比2%的异常图像,作者提出一种”互补引导注意损失“,期望正常注意覆盖全图同时最小化正常图像中的异常注意覆盖区域。CAVGA模型在多个数据集上实现SOTA。
介绍
随着数个突破性的工作,DNN在诸如图像分类、动作检测、人脸识别等领域表现已经超过人类,其中一个取得重大进展的领域是识别一副图像是否与这个模型之前所学习到图像分布一致,或者是一种新分布/异常分布。数据的限制尤其是真实场景异常数据过于稀有,为机器学习的算法设计带来了困难。以前的异常检测使用手工制作的特征,后来提出了自动编码器网络。GAN网络也可以应用于这个任务......,仅使用正常样本来训练的方法,在输入图像和重建图像之间使用像素级阈值来检测和定位异常。然而这种方法need训练异常样本来获取阈值,这在真实场景下并不可取。
为了去除这个need,我们提出一种“卷积对抗变分自编码器(CAVGA)”,这个模型是一种无监督的异常检测和定位方法同时也不需要使用异常图像参与训练。为了应对少量异常样本参与训练的情况,作者将模型拓展到了弱监督模式。在没有关于异常的先验情况下,通常需要遍历整个图像来定位异常,在此基础上设计了CAVGA的引导注意机制。无监督模式下仅使用正常样本来训练模型,希望网络能把注意放在正常图像的所有区域,这样latent variable能编码所有正常区域。弱监督模式下,在CAVGA中加入分类器,并提出以仅针对分类器是否预测出正常图像类别的互补引导注意损失。使用这样的loss来扩大正常图像的正常注意同时抑制其异常注意,其中正常/异常注意代表图像中影响分类器判断的区域。图1(a)展示了这种引导注意机制,并且作者发现它提升了模型的异常定位能力(section5中介绍),另外与我们直觉相符的是在测试图像中正常注意和异常注意是互补的 图1(b)。
这篇论文是第一个提出可训练端到端的基于注意引导的异常检测和定位的框架,只用正常图像来训练网络。对比之前的方法,CAVGA不需要异常数据来计算检测和定位异常的阈值。贡献有三点:
1.提出CAVGA网络,其中使用卷积潜变量,以保持输入和潜变量之间的空间关系,而不是变成一维向量
2.提出attention expansion loss,使无监督模式下的注意是关注正常图像的所有区域。
3.提出complementary guided attention loss,对分类器分类正确的正常图像,最大化其正常注意同时最小化异常注意。
4.在多个数据集上实现SOTA。

图1.CAVGA通过complementary guided attention loss使训练集中的正常图像的正常注意扩大至全图,同时抑制其异常注意,这使训练后的模型在测试时生成的异常注意图中更好的定位出异常。
2. CAVGA
2.1 无监督CAVGAu
图2(a)是CAVGA的无监督模式。CAVGAu使用卷积潜变量来保留输入数据的空间信息。从feature map中得到的attention map表示图像中负责特定神经元激活的区域,作者提出了attention expansion loss,使得潜变量的特征表示可以编码所有的正常区域。这个损失使从卷积潜变量中生成的attention map覆盖正常图像的全图,如图1(a)。测试阶段通过输入图像产生的异常attention map定位异常。
2.1.1 Convolutional latent variable
变分自编码器(VAE)广泛应用于异常检测,损失函数如下:
![]()
是交叉熵损失项,
是输入图像,
是重构图像,
是样本总数量。
是相对熵。由于VAEc重构出来的图像会模糊,作者加入鉴别器
来提升模型性能,通过对抗学习(公式如下)生成更好的图像
。
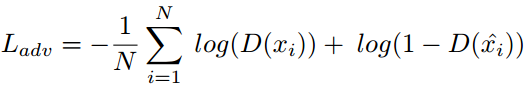
传统的自编码器的latent variable 是向量化的,而作者提出使用convolutional latent variable来保留空间信息。在section 5来验证这种方法的有效性。
2.1.2 Attention expansion loss
在检测帧级异常的同时,还着重于对图像中的异常进行空间定位。大多数方法是计算生成图像和原图的阈值像素差来定位异常,阈值是由异常图像训练而来。CAVGA通过一个端到端得训练过程从attention map中学习定位异常,并且不需要异常图像参与训练。attention map A由latent variable z 通过方法Grad-CAM计算得到,并使用sigmoid来标准化,A中每一个像素值都在(0,1),使其在端到端训练过程中便于区分。
直觉来看,A基于激活的神经元及其重要性来注意到图像的特定区域。由于没有异常的先验知识,故而需要遍历全图来定位异常。作者提出一种attention expansion loss,从整个正常图像训练集中学习特征,期望网络生成的zttention map能覆盖全图。对每个图像的loss公式如下:
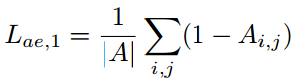
最终的attention expansion loss 是N幅图像
的平均值。定义网络的最终损失为:
![]()
在验证时,设置=1,
=1,
=0.01。
在测试时,对编码器输入图片,解码器重构图片
。计算原图和重构图片的像素级误差作为异常得分
。直观来说,如果
是
中已知的分布,那么
的值会很小(也就是说生成器只学习过正常图片,如果输入异常图片,生成器生成的图片与异常图会产生较大的重构误差,即
值较大)。
值在(0, 1)之间并设定正常和异常区分阈值为0.5。使用Grad-CAM从
中计算出attention map
,异常attention map是
。作者通过实验发现
对阈值不敏感。

2.2 Weakly supervised approach:
无监督拓展到
的弱监督,训练集中加入少量的异常图片来提高模型的检测和定位效果。由训练分类器生成的注意图已被用于弱监督语义分割任务。训练时只给帧级label没有像素级的label,作者以
为基础,在输出
后加入一个二分类器
(如图2(b)),用二元交叉熵损失
来训练
。
由
、
、
联合训练。由于生成的attention map依赖于分类器
的性能,作者提出complementary guided attention loss(互补引导注意损失)来提升
的性能。
给定图片及其label
,定义分类器
的预测为
,
和
分别是异常和正常类。对图2(b),复制一个
张量通过全连接层输出一维
,最后添加两个输出节点来组成
。
和
共享权值。
在正常图像(
)使用Grad-CAM计算出异常类的异常attention map
和正常类的正常attention map
。作者提出互补引导注意来使异常attention map注意的区域最小化,同时正常attention map尽可能覆盖全图。由于attention map是通过从
反向传播梯度来计算的,所以任何不正确的
都会产生错误的attention map。这将导致网络在训练过程中把注意力集中在图像的错误区域,这种情况下不使用互补引导注意损失。仅在
即正常图像分类正确的时候计算互补引导注意损失项。在弱监督模式下,对每张图计算互补引导注意损失
:
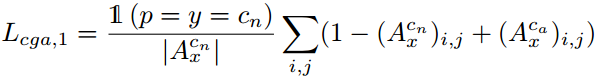
这里是一个指示函数。最终的引导注意损失
是N幅图像的
的平均值。
最终损失定义为:
![]()
在验证时,设置=1,
=1,
=0.001,
=0.01。测试时,用分类器
来预测输入图片
是正常还是异常。当
时计算异常attention map
。

