1.分类模型中的预测准确率
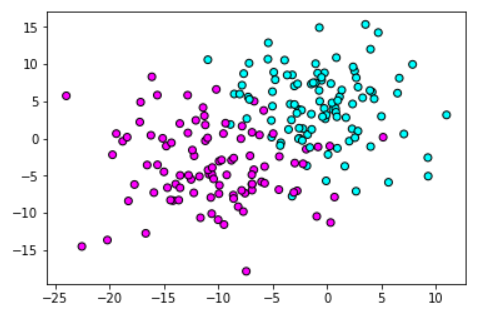
############################# 分类模型中的预测准确率 ####################################### #导入数据集生成工具 from sklearn.datasets import make_blobs #导入numpy import numpy as np #导入画图工具 import matplotlib.pyplot as plt #生成样本数为200,分类为2,标准差为5的数据集 X,y = make_blobs(n_samples=200,random_state=1,centers=2,cluster_std=5) #绘制散点图 plt.scatter(X[:,0],X[:,1],c=y,cmap=plt.cm.cool,edgecolor='k') #显示图像 plt.show()
#导入数据集拆分工具
from sklearn.model_selection import train_test_split
#导入贝叶斯模型
from sklearn.naive_bayes import GaussianNB
#将数据集拆分为训练集与测试集
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=68)
#训练高斯贝叶斯模型
gnb = GaussianNB()
gnb.fit(X_train,y_train)
#获得高斯贝叶斯的分类准确概率
predict_proba = gnb.predict_proba(X_test)
#打印结果
print('预测准确率形态:{}'.format(predict_proba.shape))
预测准确率形态:(50, 2)
#打印准确率的前5个 print(predict_proba[:5])
[[0.98849996 0.01150004] [0.0495985 0.9504015 ] [0.01648034 0.98351966] [0.8168274 0.1831726 ] [0.00282471 0.99717529]]
#设定横纵轴的范围 x_min,x_max = X[:, 0].min() - .5,X[:, 0].max() + .5 y_min,y_max = X[:, 1].min() - .5,X[:, 1].max() + .5 xx,yy = np.meshgrid(np.arange(x_min,x_max, 0.2),np.arange(y_min,y_max, 0.2)) Z = gnb.predict_proba(np.c_[xx.ravel(),yy.ravel()])[:, 1] Z = Z.reshape(xx.shape) #绘制等高线 plt.contourf(xx,yy,Z,cmap=plt.cm.summer,alpha=.8) #绘制散点图 plt.scatter(X_train[:,0],X_train[:,1],c=y_train,cmap=plt.cm.cool,edgecolor='k') plt.scatter(X_test[:,0],X_test[:,1],c=y_test,cmap=plt.cm.cool,edgecolor='k',alpha=0.6) #设置横纵轴范围 plt.xlim(xx.min(),xx.max()) plt.ylim(yy.min(),yy.max()) #设置横纵轴单位 plt.xticks(()) plt.yticks(()) #显示图像 plt.show()

- 图中的圆点代表的是测试集中的样本数据,青色区域代表第一个分类,红色区域代表第二个分类,在两个区域的中间,有一部分渐变色的区域,处于这个区域中的数据点便是模型觉得"模棱两可"的点
2.分类模型中的决定系数
#导入SVC模型 from sklearn.svm import SVC #使用训练集训练模型 svc = SVC(gamma='auto').fit(X_train,y_train) #获得SVC的决定系数 dec_func = svc.decision_function(X_test) #打印决定系数中的前5个 print(dec_func[:5])
[ 0.02082432 0.87852242 1.01696254 -0.30356558 0.95924836]
Z = svc.decision_function(np.c_[xx.ravel(),yy.ravel()])
Z = Z.reshape(xx.shape)
#绘制等高线
plt.contourf(xx,yy,Z,cmap=plt.cm.summer,alpha=.8)
#绘制散点图
plt.scatter(X_train[:,0],X_train[:,1],c=y_train,cmap=plt.cm.cool,edgecolor='k')
plt.scatter(X_test[:,0],X_test[:,1],c=y_test,cmap=plt.cm.cool,edgecolor='k',alpha=0.6)
#设置横纵轴范围
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
#设置图题
plt.title('SVC decision_function')
#设置横纵轴单位
plt.xticks(())
plt.yticks(())
#显示图像
plt.show()
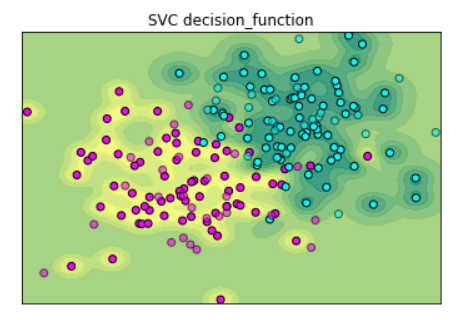
- 分类同样是用青色和红色的区域来表示,如每个数据点所处的区域青色越明显,则说明模型越确定这个数据点属于分类1,反之属于分类2,那些处于渐变色区域的点,也是模型觉得"模棱两可"的点.
#在scikit-learn中,使用网格搜索GridSearchCV类时,如果要改变评分方式,只需修改scoring参数即可. #如对随机森林分类进行评分,可以直接这样修改 #修改scoring参数为roc_auc grid = GirdSearchCV(RandomForestClassifier(),param_grid = param_grid,scoring = 'roc_auc')
总结 :
SVC(支持向量机)的decision_function和GaussianNB(朴素贝叶斯)的predict_proba有相似之处,也有很大的差异.两者都可以使用多元分类任务.
我们使用交叉验证法.网格搜索法,分类模型的可信度评估,这些方法都可以帮助我们对模型进行评估并找到相对较优的参数.
还有.score方法给模型评分:对于分类模型来说,默认情况下.score给出的评分是模型分类的准确率(accuracy)
对于回归模型来说,默认情况下.score给出的评分回归分析中的R平方的分数.
其他对模型评分的方法 : 精度(Precision),召回率(Recall),f1分数(f1-score),ROC(Receiver Operating Characteristic Curve),AUC(Area Under Curve)
文章引自 : 《深入浅出python机器学习》