针对二元分类结果,常用的评估指标有如下三个:查准率(Precision)、查全率(Recall)以及F-score。这篇文章将讨论这些指标的含义、设计初衷以及局限性。
一、二元分类问题
在机器学习领域,我们常常会碰到二元分类问题。这是因为在现实中,我们常常面对一些二元选择,比如在休息时,决定是否一把吃鸡游戏。不仅如此,很多事情的结果也是二元的,比如向妹子表白时,是否被发好人卡。
当然,在实际中还存在一些结果是多元的情况,比如红、黄、蓝三种颜色中,喜欢哪一个,而这些多元情况对应着机器学习里的多元分类问题。对于多元分类问题,在实际的处理过程中常将它们转换为多个二元分类问题解决,比如图1所示的例子。
 图1
图1
那么自然地,一个多元分类结果可以分解为多个二元分类结果来进行评估。这就是为什么我们只讨论二元分类结果的评估。为了更加严谨的表述,我们使用变量 来表示真实的结果, 表示预测的结果。其中 表示正面的结果(在实际应用中更加关心的类别),比如妹子接受表白,而 表示负面的结果,比如妹子拒绝表白。
二、查准率与查全率
在讨论查准查全的数学公式之前,我们先来探讨:针对二元分类问题,应该如何正确评估一份预测结果的效果。
沿用上面的数学记号。如图2所示,图中标记为1的方块表示 ,但 的数据;标记为3的凹型方块表示 ,但 的数据;标记为2的方块表示 ,且 的数据。而且这些图形的面积与对应数据的数据量成正比,比如, ,且 的数据个数越多,标记2的面积越大。
很容易发现,图中标记为2的部分表示模型预测结果正确,而标记为1和3的部分则表示模型预测结果错误。
- 对于一份预测结果,一方面希望它能做到“精确”:当时 ,有很大概率,真实值 就等于1。这表现在图形上,就是标记2的面积很大,而标记3的面积很小。
- 另一方面也希望它能做到“全面”:对于几乎所有的 ,对应的预测值 也等于1。在图形上,这表示标记2的面积很大,而标记1的面积很小。
于是,对应地定义查准率(precision)和查全率(recall)这两个技术指标(有的文献里,将查准率翻译为精确率;将查全率翻译为召回率)来评估一份预测结果的效果。比较直观的定义如图2所示。
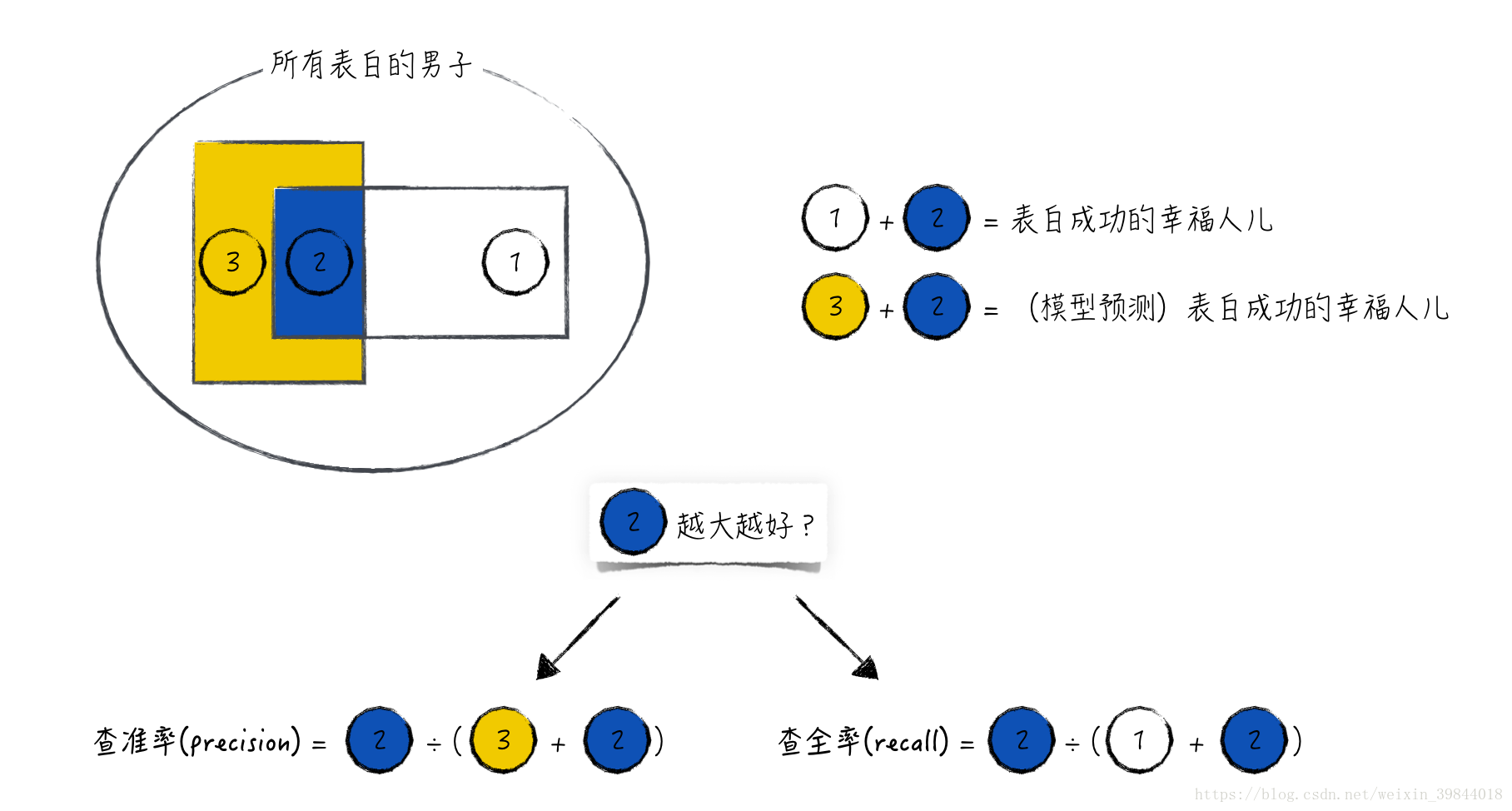 图2
图2
为了更加严谨,下面将从数学的角度给出这两个指标的严格定义。首先将数据按预测值和真实值分为4类,具体见表1。
 表1
表1
于是可以得到公式(1):
公式(1)经过进一步的推导,可以得到这两个技术指标的概率定义,如公式(2)。从概率上来讲:预测值等于1时,真实值等于1的概率为查准率;真实值等于1时,预测值等于1的概率为查全率。
理想的情况是这两个指标都很高,但现实往往是残酷的。这两个指标通常存在着此消彼长的现象。比如降低预测表白成功的标准(也就是增加 的数量),往往会提高它的查全率,但同时会降低它的查准率,反之依然。整个过程的直观图像如图3所示。
 图3
图3
三、F-score
既然这两个指标往往是成反比的,而且在很大程度上,受预测标准的控制。那么只拿其中的某一个指标去评估预测结果是不太合适的。比如在极端情况下,预测所有表白都成功,即。这时预测的查全率是100%,但查准率肯定很低,而且这样的预测显然是没太大价值的。而两个指标同时使用,在实际应用时又不太方便。为了破解这个困局,在实践中,我们定义了新的指标去“综合”这两个指标。具体的定义如公式(3),从数学上来看,它其实是查准率与查全率的调和平均数。对于二元分类问题, 综合考虑了预测结果的查准率和查全率,是一个比较好的评估指标。
其实从模型的角度来看,查准率与查全率的“相互矛盾”给了我们更多的调整空间。应用场景不同,我们对查准率和查全率的要求是不一样的。在有的场景中,关注的焦点是查全率。例如对于网上购物的衣服推荐,电商平台关心的是那些对衣服感兴趣的客户,希望模型对这些客户的预测都正确;而那些对衣服不感兴趣的客户,即使模型结果有较大偏差,也是可以接受的。也就是说,电商平台重视查全率,但不太关心查准率。这时就可以调低模型的预测标准,通过牺牲查准率来保证查全率。但在有的场景中,查准率才是重点。例如在实时竞价(RTB)广告行业,有3种参与者:需要在互联网上对产品做广告的商家,比如Nike;广告投放中介(DSP);广告位提供者,比如新浪网。Nike将广告内容委托给广告投放中介A,A通过分析选定目标客户群。当目标客户访问新浪网时,A向新浪网购买广告位并将Nike广告推送给他。如果该客户点击了Nike广告,Nike会向投放中介A支付相应费用。否则,全部费用由中介A承担。那么对于广告投放中介A,它希望投放的每条广告都会被点击,但不太关心是否每个对Nike感兴趣的客户都被推送了广告。换句话说,广告投放中介更关心查准率。于是可以通过调高模型的预测标准来提高查准率,当然这时会牺牲一部分查全率。
对于这些偏重某一特定指标的场景,可以如公式(4),相应地定义指标(其实是的一个特例)。当靠近0时,偏向查准率,而很大时,则偏向查全率,如图4所示。
 图4
图4
四、总结
查准率、查全率和F-score是最为常用的二元分类结果评估指标。其中查准率和查全率这两个指标都只侧重于预测结果的某一个方面,并不能较全面地评价分类结果。而F-score则是更加“上层”的评估指标,它建立在前面两个指标的基础上,综合地考虑了分类结果的精确性和全面性。
从上面的讨论可以看到,这三个指标针对的是某一份给定的分类结果。但对于大多数分类模型,它们往往能产生很多份分类结果,比如对于逻辑回归,调整预测阈值可以得到不同的分类结果。也就是说,这三个指标并不能“很全面”地评估模型本身的效果,需要引入新的评估指标。这部分内容的讨论将在下一篇文章中展开(《分类模型的评估(二)》)。
五、广告时间
这篇文章的大部分内容参考自我的新书《精通数据科学:从线性回归到深度学习》。
李国杰院士和韩家炜教授在读过此书后,亲自为其作序,欢迎大家购买。
另外,与之相关的免费视频课程请关注这个链接