LLMs:大型语言模型进化树结构图之模型(BERT-style/GPT-style)、数据(预训练数据/微调数据/测试数据)、NLP任务(五大任务+效率+可信度+基准指令调优+对齐)、三大类模型的使用和限制(Encoder-only、Encoder-Decoder、Decoder-only)
目录
大型语言模型进化树结构图之模型(BERT-style/GPT-style)、数据(预训练数据/微调数据/测试数据)、NLP任务(五大任务+效率+可信度+基准指令调优+对齐)
一、模型的实用指南:BERT-style/GPT-style
1.1、BERT-style 的语言模型:编码器-解码器或仅编码器
三、自然语言处理任务的实用指南:NLP五大任务+效率+可信度+基准指令调优+对齐
3.7.3、参数高效微调Parameter-Efficient Fine-Tuning
3.8.1、鲁棒性和校准性Robustness and Calibration
3.9、基准指令调优Benchmark Instruction Tuning
3.10.1、安全对齐(无害)Safety Alignment (Harmless)
3.10.2、真实对齐(诚实) Truthfulness Alignment (Honest)
3.10.3、指导实践(有帮助)Practical Guides for Prompting (Helpful)
3.10.4、开源社区的对齐努力Alignment Efforts of Open-source Communtity
四、三大类模型的使用和限制:Encoder-only、Encoder-Decoder、Decoder-only
大型语言模型进化树结构图之模型(BERT-style/GPT-style)、数据(预训练数据/微调数据/测试数据)、NLP任务(五大任务+效率+可信度+基准指令调优+对齐)
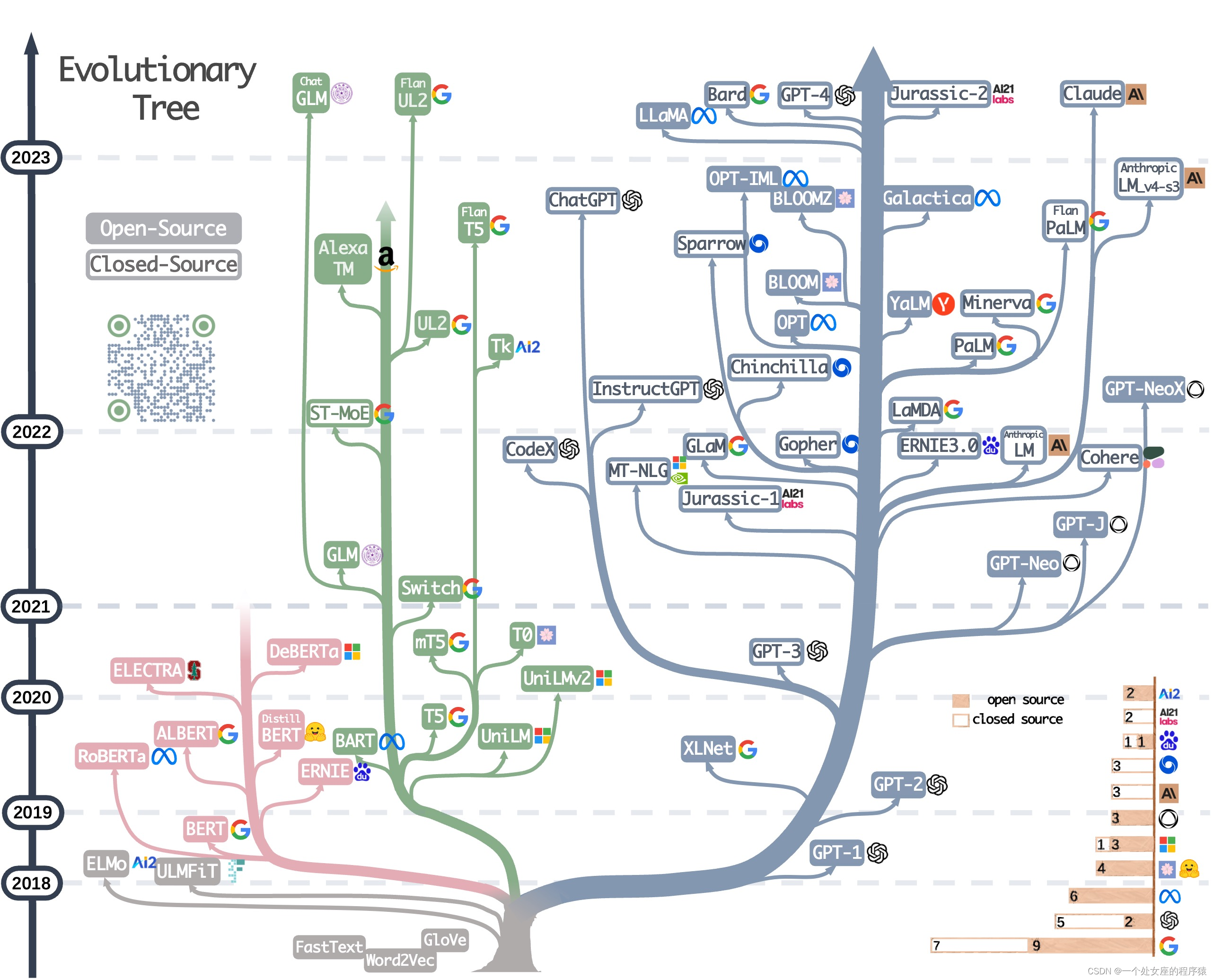
大型语言模型进化树结构图
该列表基于我们的调研论文《在实践中利用LLMs的威力:关于ChatGPT及其后续发展的调研》,以及@xinyadu的努力。该调研部分基于这篇博客的后半部分。我们还构建了一个现代大型语言模型(LLMs)的演化树,以追踪近年来语言模型的发展,并突出了一些最知名的模型。
这些资源旨在帮助从业者在大型语言模型(LLMs)及其在自然语言处理(NLP)应用中的应用方面进行导航。我们还根据模型和数据许可信息包括它们的使用限制。如果您发现我们仓库中的任何资源有帮助,请随意使用(不要忘记引用我们的论文!���)。我们欢迎拉取请求来完善这个图表!
一、模型的实用指南:BERT-style/GPT-style
1.1、BERT-style 的语言模型:编码器-解码器或仅编码器
|
BERT BERT:用于语言理解的深度双向转换器的预训练,2018年 RoBERTa RoBERTa:一种优化稳健的BERT预训练方法,2019年 DistilBERT DistilBERT:BERT的精简版本:更小、更快、更便宜、更轻巧,2019年 ALBERT ALBERT:一种轻量级的自监督学习语言表示方法,2019年 UniLM 统一语言模型预训练用于自然语言理解和生成,2019年 ELECTRA ELECTRA:将文本编码器作为判别器而非生成器进行预训练,2020年 T5 "探索具有统一文本到文本Transformer的迁移学习的极限"。Colin Raffel等人,JMLR 2019年 GLM "GLM-130B:一种开放的双语预训练模型",2022年 AlexaTM "AlexaTM 20B:使用大规模多语言Seq2Seq模型进行少样本学习"。Saleh Soltan等人,arXiv 2022年 ST-MoE ST-MoE:设计稳定且可转移的稀疏专家模型。2022年 |
1.2、GPT-style的语言模型:仅解码器
|
GPT 通过生成式预训练改进语言理解。2018年 GPT-2 语言模型是无监督多任务学习者。2018年 GPT-3 "语言模型是少样本学习者"。NeurIPS 2020年 OPT "OPT:开放预训练转换器语言模型"。2022年 PaLM "PaLM:通过路径扩展语言建模"。Aakanksha Chowdhery等人,arXiv 2022年 BLOOM "BLOOM:一种拥有176B参数的开放式多语言语言模型"。2022年 MT-NLG "使用DeepSpeed和Megatron训练Megatron-Turing NLG 530B,一种大规模生成语言模型"。2021年 GLaM "GLaM:通过专家混合实现语言模型的高效扩展"。ICML 2022年 Gopher "扩展语言模型:方法、分析和Gopher训练见解"。2021年 chinchilla "训练计算优化的大型语言模型"。2022年 LaMDA "LaMDA:用于对话应用的语言模型"。2021年 LLaMA "LLaMA:开放和高效的基础语言模型"。2023年 GPT-4 "GPT-4技术报告"。2023年 BloombergGPT BloombergGPT:一种面向金融领域的大型语言模型,2023年 GPT-NeoX-20B:"GPT-NeoX-20B:一种开源自回归语言模型"。2022年 |
二、数据实用指南:预训练数据/微调数据/测试数据
2.1、预训练数据
|
RedPajama,2023年,代码库 The Pile:一份用于语言建模的800GB多样化文本数据集,Arxiv 2020年 预训练目标如何影响大型语言模型对语言属性的学习?ACL 2022年 神经语言模型的扩展定律,2020年 以数据为中心的人工智能:一份调查,2023年 GPT如何获得其能力?追踪语言模型的新兴能力源自何处,2022年,博客 |
2.2、微调数据
| 基于零样本文本分类的基准测试:数据集、评估和蕴含方法,EMNLP 2019年 语言模型是少样本学习者,NIPS 2020年 合成数据生成对临床文本挖掘有帮助吗?Arxiv 2023年 |
2.3、测试数据/用户数据
|
自然语言理解中大型语言模型的快捷学习:一份调查,Arxiv 2023年 关于ChatGPT的鲁棒性:从对抗和分布外的角度看,Arxiv 2023年 SuperGLUE:一项用于通用语言理解系统的更具挑战性的基准测试,Arxiv 2019年 |
三、自然语言处理任务的实用指南:NLP五大任务+效率+可信度+基准指令调优+对齐
我们为用户的自然语言处理(NLP)应用程序构建了一个决策流程,用于选择LLMs或经过微调的模型\protect\footnotemark。该决策流程帮助用户评估他们手头的下游NLP应用程序是否满足特定条件,并基于该评估确定LLMs或经过微调的模型是否是他们应用程序的最佳选择。
3.1、传统的NLU任务
| Civil Comments数据集上有害评论分类的基准 Arxiv 2023 ChatGPT是否是一个通用的自然语言处理任务求解器?Arxiv 2023 大型语言模型在新闻摘要中的基准测试Arxiv 2022 |
3.2、生成任务
|
在GPT-3时代的新闻摘要和评估 Arxiv 2022 ChatGPT是否是一个好的翻译器?是的,使用GPT-4作为引擎Arxiv 2023 微软的多语言机器翻译系统用于WMT21共享任务,WMT2021 ChatGPT能够理解吗?关于ChatGPT和经过微调的BERT的对比研究Arxiv 2023 |
3.3、知识密集型任务
|
测量大规模多任务语言理解 ICLR 2021 超越模仿游戏:量化和推断语言模型的能力 Arxiv 2022 Inverse scaling prize, 2022 链接 Atlas: 带有检索增强的少样本学习语言模型Arxiv 2022 大型语言模型编码临床知识,Arxiv 2022 |
3.4、随着规模增长的能力
|
训练计算优化的大型语言模型 NeurIPS 2022 神经网络语言模型的缩放定律,Arxiv 2020 使用基于过程和结果的反馈解决数学问题,Arxiv 2022 思维链引导引发大型语言模型的推理,NeurIPS 2022 大型语言模型的新兴能力,TMLR 2022 Inverse scaling可能呈U形,Arxiv 2022 走向大型语言模型的推理:一项调查,Arxiv 2022 |
3.5、特定任务
|
图像作为外语:针对所有视觉和视觉-语言任务的BEiT预训练模型 Arixv 2022 PaLI:一个联合缩放的多语言语言-图像模型,Arxiv 2022 AugGPT:利用ChatGPT进行文本数据增强 Arxiv 2023 GPT-3是否是一个好的数据标注器?Arxiv 2022 想要降低标注成本吗?GPT-3可以帮助,EMNLP findings 2021 GPT3Mix:利用大规模语言模型进行文本增强,EMNLP findings 2021 LLM用于患者-试验匹配:隐私感知的数据增强以提高性能和普适性,Arxiv 2023 ChatGPT在文本注释任务中胜过众包工作者,Arxiv 2023 G-Eval:使用GPT-4进行自然语言生成评估,Arxiv 2023 GPTScore:根据需求进行评估,Arxiv 2023 大型语言模型是翻译质量的最先进评估器,Arxiv 2023 ChatGPT是一个好的自然语言生成评估器吗?初步研究,Arxiv 2023 |
3.6、现实世界的任务
|
人工通用智能的火花:GPT-4的初步实验 Arxiv 2023 |
3.7、效率Efficiency
3.7.1、成本Cost
| OpenAI的GPT-3语言模型:技术概述,2020年博客文章 测量云计算实例中人工智能的碳强度,FaccT 2022 在人工智能领域,更大是否总是更好?,2023年自然文章 语言模型是少样本学习器,NeurIPS 2020 定价,OpenAI博客文章 |
3.7.2、延迟Latency
|
HELM:语言模型的全面评估,Arxiv 2022 |
3.7.3、参数高效微调Parameter-Efficient Fine-Tuning
|
LoRA:大型语言模型的低秩适应,Arxiv 2021 Prefix-Tuning:优化生成任务的连续提示,ACL 2021 P-Tuning:在规模和任务上,提示调优可以与微调相媲美,ACL 2022 P-Tuning v2:在各种规模和任务上,提示调优可以与微调普遍相媲美,Arxiv 2022 |
3.7.4、预训练系统Pretraining System
|
ZeRO:向训练万亿参数模型进行内存优化,Arxiv 2019 Megatron-LM:使用模型并行性训练数十亿参数的语言模型,Arxiv 2019 使用Megatron-LM在GPU集群上进行高效的大规模语言模型训练,Arxiv 2021 减少大型Transformer模型中的激活重新计算,Arxiv 2021 |
3.8、可信度Trustworthiness
3.8.1、鲁棒性和校准性Robustness and Calibration
| 在使用之前进行校准:改善语言模型的少样本性能,ICML 2021 SPeC:软提示为基础的临床记录摘要中的校准,缓解性能变异性,Arxiv 2023 |
3.8.2、虚假偏见Spurious biases
|
自然语言理解中大型语言模型的快捷学习:一项调查,2023 减轻字幕系统中的性别偏见,WWW 2020 在使用之前进行校准:改善语言模型的少样本性能,ICML 2021 深度神经网络的快捷学习,Nature Machine Intelligence 2020 基于提示的模型真的理解其提示的含义吗?,NAACL 2022 |
3.8.3、安全问题Safety issues
|
GPT-4系统卡片,2023 检测LLM生成文本的科学,Arxiv 2023 通过语言分享刻板印象:社会类别和刻板印象传播(SCSC)框架的回顾和介绍,Review of Communication Research,2019 性别影子:商业性别分类中的交叉准确性差异,FaccT 2018 |
3.9、基准指令调优Benchmark Instruction Tuning
|
FLAN:微调语言模型是零样本学习器,Arxiv 2021 T0:多任务提示训练实现零样本任务泛化,Arxiv 2021 通过自然语言众包指令实现跨任务泛化,ACL 2022 Tk-INSTRUCT:超自然指令:通过1600+ NLP任务的声明性指令实现泛化,EMNLP 2022 FLAN-T5/PaLM:扩展指令微调语言模型,Arxiv 2022 Flan集合:设计数据和方法以实现有效的指令调优,Arxiv 2023 OPT-IML:通过泛化视角扩展语言模型指令元学习,Arxiv 2023 |
3.10、对齐Alignment
|
从人类偏好中进行深度强化学习,NIPS 2017 从人类反馈中学习总结,Arxiv 2020 作为对齐实验室的通用语言助手,Arxiv 2021 通过从人类反馈中进行强化学习训练一个有帮助且无害的助手,Arxiv 2022 教导语言模型通过验证的引用支持答案,Arxiv 2022 InstructGPT:通过人类反馈训练语言模型遵循指令,Arxiv 2022 通过有针对性的人类判断提高对话代理的对齐,Arxiv 2022 奖励模型过度优化的规模定律,Arxiv 2022 可扩展监督:衡量大型语言模型可扩展监督的进展,Arxiv 2022 |
3.10.1、安全对齐(无害)Safety Alignment (Harmless)
| 使用语言模型对抗语言模型,Arxiv 2022 宪法AI:通过AI反馈实现无害性,Arxiv 2022 大型语言模型的道德自我修正能力,Arxiv 2023 OpenAI:我们对AI安全的方法,2023博客 |
3.10.2、真实对齐(诚实) Truthfulness Alignment (Honest)
|
语言模型的强化学习,2023博客 |
3.10.3、指导实践(有帮助)Practical Guides for Prompting (Helpful)
| OpenAI食谱。博客 提示工程。博客 开发人员的ChatGPT提示工程!课程 |
3.10.4、开源社区的对齐努力Alignment Efforts of Open-source Communtity
| 自我指导:用自动生成的指令对齐语言模型,Arxiv 2022 |
四、三大类模型的使用和限制:Encoder-only、Encoder-Decoder、Decoder-only
我们从模型及其预训练数据的角度提供信息。我们敦促社区中的用户参考公共模型和数据的许可信息,并负责任地使用它们。我们敦促开发者特别注意许可证的问题,使其透明且全面,以防止任何不必要和意外的使用情况。
4.1、Encoder-only
| LLMs |
Model |
Data |
|||
| License |
Commercial Use |
Other noteable restrictions |
License |
Corpus |
|
| BERT series of models (general domain) |
Apache 2.0 |
✅ |
Public |
BooksCorpus, English Wikipedia |
|
| RoBERTa |
MIT license |
✅ |
Public |
BookCorpus, CC-News, OpenWebText, STORIES |
|
| ERNIE |
Apache 2.0 |
✅ |
Public |
English Wikipedia |
|
| SciBERT |
Apache 2.0 |
✅ |
Public |
BERT corpus, 1.14M papers from Semantic Scholar |
|
| LegalBERT |
CC BY-SA 4.0 |
❌ |
Public (except data from the Case Law Access Project) |
EU legislation, US court cases, etc. |
|
| BioBERT |
Apache 2.0 |
✅ |
PubMed, PMC |
||
4.2、Encoder-Decoder
| License |
Commercial Use |
Other noteable restrictions |
License |
Corpus |
|
| T5 |
Apache 2.0 |
✅ |
Public |
C4 |
|
| Flan-T5 |
Apache 2.0 |
✅ |
Public |
C4, Mixture of tasks (Fig 2 in paper) |
|
| BART |
Apache 2.0 |
✅ |
Public |
RoBERTa corpus |
|
| GLM |
Apache 2.0 |
✅ |
Public |
BooksCorpus and English Wikipedia |
|
| ChatGLM |
❌ |
No use for illegal purposes or military research, no harm the public interest of society |
N/A |
1T tokens of Chinese and English corpus |
4.3、Decoder-only
| License |
Commercial Use |
Other noteable restrictions |
License |
Corpus |
|
| GPT2 |
✅ |
Use GPT-2 responsibly and clearly indicate your content was created using GPT-2. |
Public |
WebText |
|
| GPT-Neo |
MIT license |
✅ |
Public |
||
| GPT-J |
Apache 2.0 |
✅ |
Public |
Pile |
|
| ---> Dolly |
CC BY NC 4.0 |
❌ |
CC BY NC 4.0, Subject to terms of Use of the data generated by OpenAI |
Pile, Self-Instruct |
|
| ---> GPT4ALL-J |
Apache 2.0 |
✅ |
Public |
||
| Pythia |
Apache 2.0 |
✅ |
Public |
Pile |
|
| ---> Dolly v2 |
MIT license |
✅ |
Public |
Pile, databricks-dolly-15k |
|
| OPT |
❌ |
No development relating to surveillance research and military, no harm the public interest of society |
Public |
RoBERTa corpus, the Pile, PushShift.io Reddit |
|
| ---> OPT-IML |
❌ |
same to OPT |
Public |
OPT corpus, Extended version of Super-NaturalInstructions |
|
| YaLM |
Apache 2.0 |
✅ |
Unspecified |
Pile, Teams collected Texts in Russian |
|
| BLOOM |
✅ |
No use of generating verifiably false information with the purpose of harming others; |
Public |
ROOTS corpus (Lauren¸con et al., 2022) |
|
| ---> BLOOMZ |
✅ |
same to BLOOM |
Public |
ROOTS corpus, xP3 |
|
| Galactica |
❌ |
N/A |
The Galactica Corpus |
||
| LLaMA |
❌ |
No development relating to surveillance research and military, no harm the public interest of society |
Public |
CommonCrawl, C4, Github, Wikipedia, etc. |
|
| ---> Alpaca |
CC BY NC 4.0 |
❌ |
CC BY NC 4.0, Subject to terms of Use of the data generated by OpenAI |
LLaMA corpus, Self-Instruct |
|
| ---> Vicuna |
CC BY NC 4.0 |
❌ |
Subject to terms of Use of the data generated by OpenAI; |
LLaMA corpus, 70K conversations from ShareGPT.com |
|
| ---> GPT4ALL |
GPL Licensed LLaMa |
❌ |
Public |
||
| OpenLLaMA |
Apache 2.0 |
✅ |
Public |
||
| CodeGeeX |
❌ |
No use for illegal purposes or military research |
Public |
Pile, CodeParrot, etc. |
|
| StarCoder |
✅ |
No use of generating verifiably false information with the purpose of harming others; |
Public |
||
| MPT-7B |
Apache 2.0 |
✅ |
Public |
||
| ✅/❌ |
Available under a license allowing commercial use |
Public |