“万事万物都存在不确定性,包括真理”
对于分类模型,我们知道利用模型确实能进行预测分类,为其加上标签,但是,模型预测的内部机制也是依据概率计算的,大概率属于1类,则分到1类。
大部分算法都有predict_proba属性
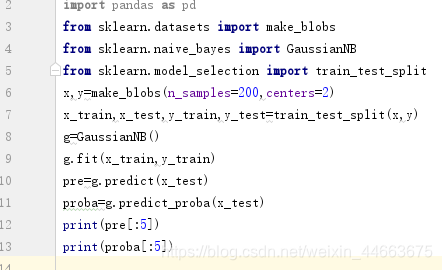

我们利用高斯贝叶斯算法进行分类,利用predict_proba属性查看内部是怎样计算的,我们发现,对于测试集而言,前5个分类是1,0,0,0,1 ; 而后的列表表示的是概率,如列表的第一行,4.02843511e-18表示有接近0的概率属于第一类别, 1.00000000e+00表示有1的概率属于第二类别,至于第一类别是什么,第二类别是什么,我们貌似不需要去关心。
除了predict_proba属性,我们还有决定系数属性
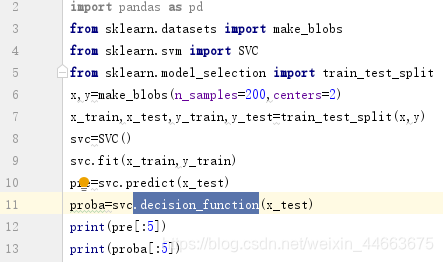
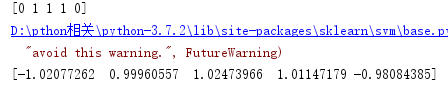
列表内容表示,如果数值为正数就属于1类,如果负数就属于0类。
不同的分类算法,概率模型可能不尽相同,大家可以行决定。
其实,我们并不需太在意可信度评估,分类结果达到即可。