分类模型的误差
1.训练误差:也称再代入误差或表现误差,是在训练记录上误分类样本比例(拟合训练数据的程度)。
2.泛化误差:模型在未知记录上的期望误差(对未知样本分类的能力)。
模型拟合问题
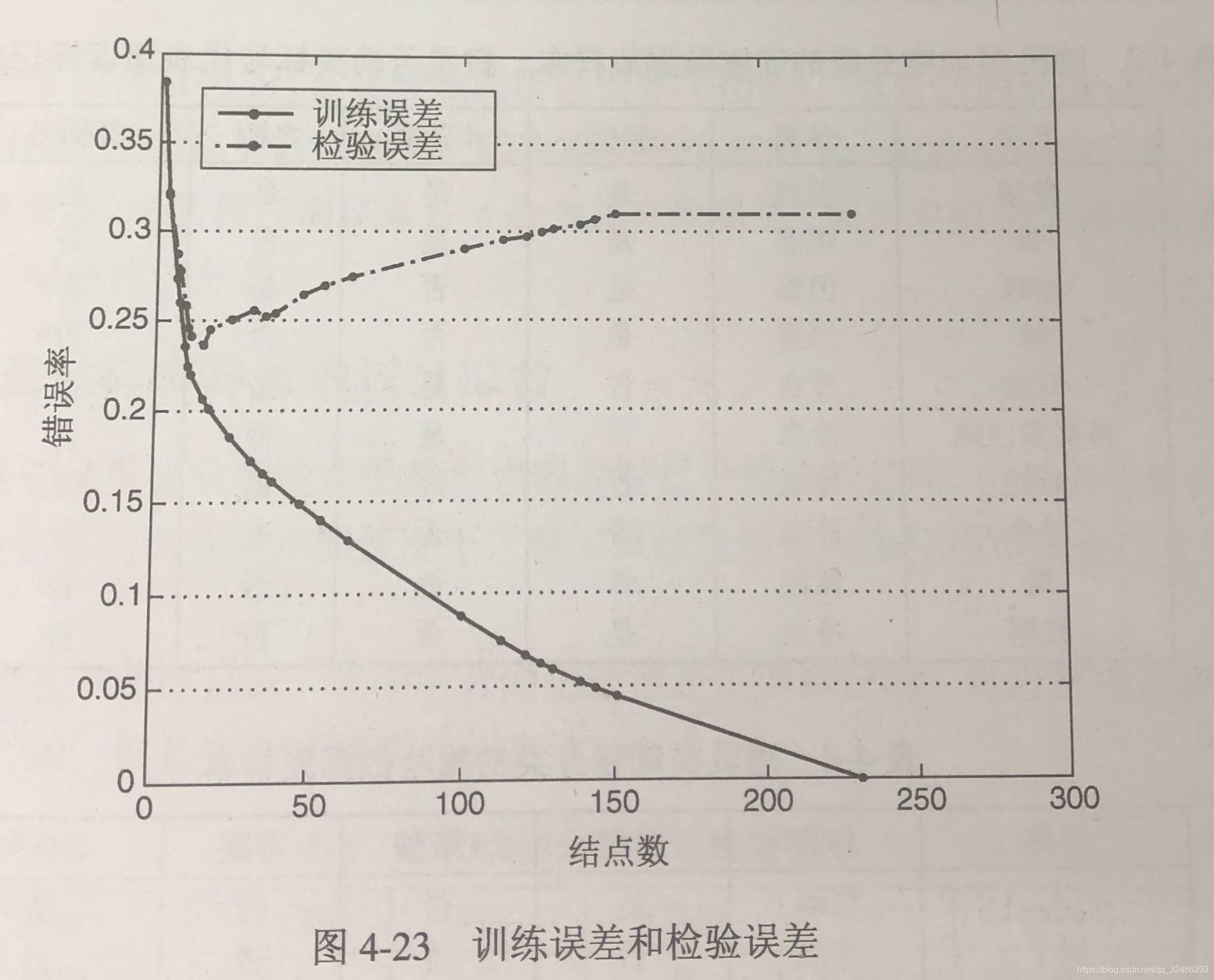
1.模型拟合不足:当决策树很小时,训练和检验误差都很大。
2.模型过拟合:随着决策树中结点数的增加,模型的训练误差和检验误差都会随之降低,一旦树的规模变得太大,即使训练误差还在继续降低,但是检验误差开始增大。
过分拟合原因
- 噪声导致的过分拟合(数据错误)
- 缺乏代表性样本导致的过分拟合(数据不足)
- 多重比较过程导致的过分拟合
- 模型复杂度对过分拟合的影响
处理过分拟合方法
1.先剪枝(提前终止规则)
概念:树增长算法在产生完全拟合整个训练数据集的完全增长的决策树之前就停止决策树的生长。
优点:避免产生过分拟合训练数据的过于复杂的子树。
缺点:阈值不好选取,阈值太高将导致拟合不足,阈值太低将导致过分拟合;此外,即便使用已有的属性测试条件得不到显著的增益,接下来的划分也可能产生较好的子树。
2.后剪枝
概念:初始决策树按照最大规模生长,然后进行剪枝的步骤,按照自底向上的方式修剪完全增长的决策树。
方法:
a. 用新的叶结点替换子树,该叶结点的类标号由子树记录下的多数类确定(子树替换)
b. 用子树中最常使用的分支代替子树(子树提升)
3.比较
后剪枝技术会产生更好的结果,后剪枝技术根据完全增长的决策树做出的剪枝决策,先剪枝则可能过早终止决策树的生长;另一方面,后剪枝剪掉的子树对应的额外计算被浪费了。