引言
yolo v3用于提取特征的backbone是Darknet-53,他借鉴了yolo v2中的网络(Darknet-19)结构,在名字上我们也可以窥出端倪。不同于Darknet-19的是,Darknet-53引入了大量的残差结构,并且使用步长为2,卷积核大小为3×3卷积层Conv2D代替池化层Maxpooling2D。通过在ImageNet上的分类表现,Darknet-53经过以上改造在保证准确率的同时极大地提升了网络的运行速度,证明了Darknet-53在特征提取能力上的有效性。
网络结构讲解
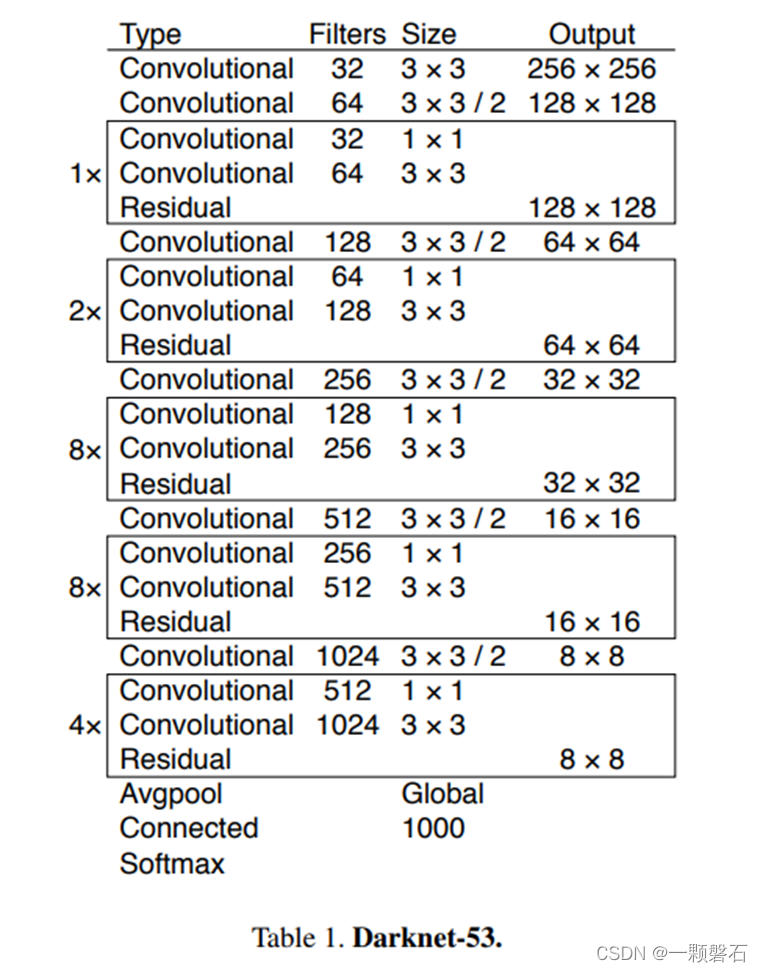
图1. Darknet-53网络结构图
图1中为Darknet-53的网络结构图。从图1中可以看出,网络中堆叠了大量的残差结构Residual,而且每两个残差结构之间插着一个步长为2,卷积核大小为3×3卷积层,用于完成下采样的操作。在源码中,Darknet-53网络的输入尺寸是416416,最后卷积层输出的特征图尺寸为1313,通道数为1024。如果是分类任务,最后一个残差结构之后接入全局池化层Global Avgpool,1000个神经元的全连接层Connected,以及一个激活函数层Softmax。但是,在YOLO v3中,Darknet-53只用于提取特征,所以没有最后的这三层,只是输出了三种不同尺寸的特征图(13 * 13、26 * 26、52 * 52)。
图2中展示了Darknet-53中堆叠的残差单元的结构图。其中Input和Output分别是残差单元的输入和输出,In_channels是输入的通道数,h,w分别为输入的高和宽。

图2. Darknet-53中残差单元的网络结构
从图2中可以看到,输入首先经过一个1×1的卷积层Conv(1×1,stride=1)将通道数降低一半变为 I n c h a n n e l s 2 \frac{In_channels}{2} 2Inchannels,然后进入一个3×3的卷积层Conv(3×3,stride=1)进行特征提取,这时通道数又从 I n c h a n n e l s 2 \frac{In_channels}{2} 2Inchannels恢复为In_channels。最后3×3卷积的输出与经过Shorcut传递过来的输入Input相加得到最终的Output(此时3×3卷积的输出与Input的形状(In_channels,h,w)相同,可以直接相加)。我们看到,经过Residual运算之后,输入的特征图形状保持不变。
从图1中我们可以看到,Darknet-53中总共有6个单独的卷积层和23个Residual,每个Residual包含2个卷积层(一个1×1,一个3×3),所以Darknet-53中共有52层卷积,可为什么叫做Darknet-53呢?因为Darknet-53在YOLO v3中,前52层只用作特征提取,最后一层是用于输出预测值的,故加上输出那一层称为Darknet-53。
网络结构设计理念
Darknet-53在Darknet-19的基础上增加了大量的残差结构Residual,并且使用步长为2,卷积核大小为3×3卷积层Conv2D代替池化层Maxpooling2D。作者为什么要做这两点改进呢?
残差结构
首先,加入残差结构Residual的目的是为了增加网络的深度,用于支持网络提取更高级别的语义特征,同时残差的结构可以帮助我们避免梯度的消失或爆炸。因为残差的物理结构,反映到反向梯度传播中,可以使得梯度传递到前面很远的网络层中,削弱反向求导的链式反应。
其次,我们看到残差结构单元里边输入首先会经过一个1×1的卷积层将输入通道降低一半,然后再进行3×3的卷积,这在相当程度上帮助网络减少了计算量,使得网络的运行速度更快,效率更高。
步长为2的卷积替换池化层
从作用上来说,步长为2的卷积替换池化层都可以完成下采样的工作,但其实现在的神经网络中,池化层已经比较少了,大家都开始尝试其他的下采样方法,比如步长为2的卷积。那么为什么要这样替换呢?参考CNN为什么不需要池化层下采样了?.
对于池化层和步长为2的卷积层来说,个人的理解是这样的,池化层是一种先验的下采样方式,即人为的确定好下采样的规则(选取覆盖范围内最大的那个值,默认最大值包含的信息是最多的);而对于步长为2的卷积层来说,其参数是通过学习得到的,采样的规则是不确定的,这种不确定性会增加网络的学习能力。
网络性能评估

图3. 不同backbone的性能对比
不同backbone进行比较的前提是每个网络都使用相同的设置进行训练,并以 256×256 的单裁剪精度进行测试。
运行时间(FPS)是在 Titan X 上以 256 × 256 的分辨率测量的。因此,从图3中,我们可以看出Darknet-53 的性能与最先进的分类器相当,但浮点运算更少,速度更快。Darknet-53比ResNet-101好,快1.5倍。Darknet-53 的性能与 ResNet-152相似,速度快2倍 Darknet-53 还实现了每秒最高测量浮点运算。 这意味着网络结构更好地利用了 GPU,使其评估效率更高,从而更快。 这主要是因为 ResNet 的层太多并且效率不高。
yolo v3中Darknet-53网络基于Pytorch的代码实现
对比图1进行阅读
import math
from collections import OrderedDict
import torch.nn as nn
#---------------------------------------------------------------------#
# 残差结构
# 利用一个1x1卷积下降通道数,然后利用一个3x3卷积提取特征并且上升通道数
# 最后接上一个残差边
#---------------------------------------------------------------------#
class BasicBlock(nn.Module):
def __init__(self, inplanes, planes):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes[0], kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(planes[0])
self.relu1 = nn.LeakyReLU(0.1)
self.conv2 = nn.Conv2d(planes[0], planes[1], kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes[1])
self.relu2 = nn.LeakyReLU(0.1)
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu2(out)
out += residual
return out
class DarkNet(nn.Module):
def __init__(self, layers):
super(DarkNet, self).__init__()
self.inplanes = 32
# 416,416,3 -> 416,416,32
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(self.inplanes)
self.relu1 = nn.LeakyReLU(0.1)
# 416,416,32 -> 208,208,64
self.layer1 = self._make_layer([32, 64], layers[0])
# 208,208,64 -> 104,104,128
self.layer2 = self._make_layer([64, 128], layers[1])
# 104,104,128 -> 52,52,256
self.layer3 = self._make_layer([128, 256], layers[2])
# 52,52,256 -> 26,26,512
self.layer4 = self._make_layer([256, 512], layers[3])
# 26,26,512 -> 13,13,1024
self.layer5 = self._make_layer([512, 1024], layers[4])
self.layers_out_filters = [64, 128, 256, 512, 1024]
# 进行权值初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
#---------------------------------------------------------------------#
# 在每一个layer里面,首先利用一个步长为2的3x3卷积进行下采样
# 然后进行残差结构的堆叠
#---------------------------------------------------------------------#
def _make_layer(self, planes, blocks):
layers = []
# 下采样,步长为2,卷积核大小为3
layers.append(("ds_conv", nn.Conv2d(self.inplanes, planes[1], kernel_size=3, stride=2, padding=1, bias=False)))
layers.append(("ds_bn", nn.BatchNorm2d(planes[1])))
layers.append(("ds_relu", nn.LeakyReLU(0.1)))
# 加入残差结构
self.inplanes = planes[1]
for i in range(0, blocks):
layers.append(("residual_{}".format(i), BasicBlock(self.inplanes, planes)))
return nn.Sequential(OrderedDict(layers))
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.layer1(x)
x = self.layer2(x)
out3 = self.layer3(x)
out4 = self.layer4(out3)
out5 = self.layer5(out4)
return out3, out4, out5
def darknet53():
model = DarkNet([1, 2, 8, 8, 4])
return model
总结
这篇博客从网络结构、创新设计以及改进的动机对YOLO v3提取特征的Backbone Darknet-53进行了详细的剖析,并最后基于Pytorch对其进行实现。对于经典网络的分析总是能让人学到很多东西,深度学习不是使用框架随便搭建出来就行了,我们要知悉网络各部分的设计理念及其深层次的统计学意义,这样才不会觉得神经网路只是机械式地搭积木,也不是盲盒调参。只有当我们知道各部分工作的底层原理之后,才能进行创新,创造出自己的东西。