文章目录
一. 网络结构

二. 网络说明

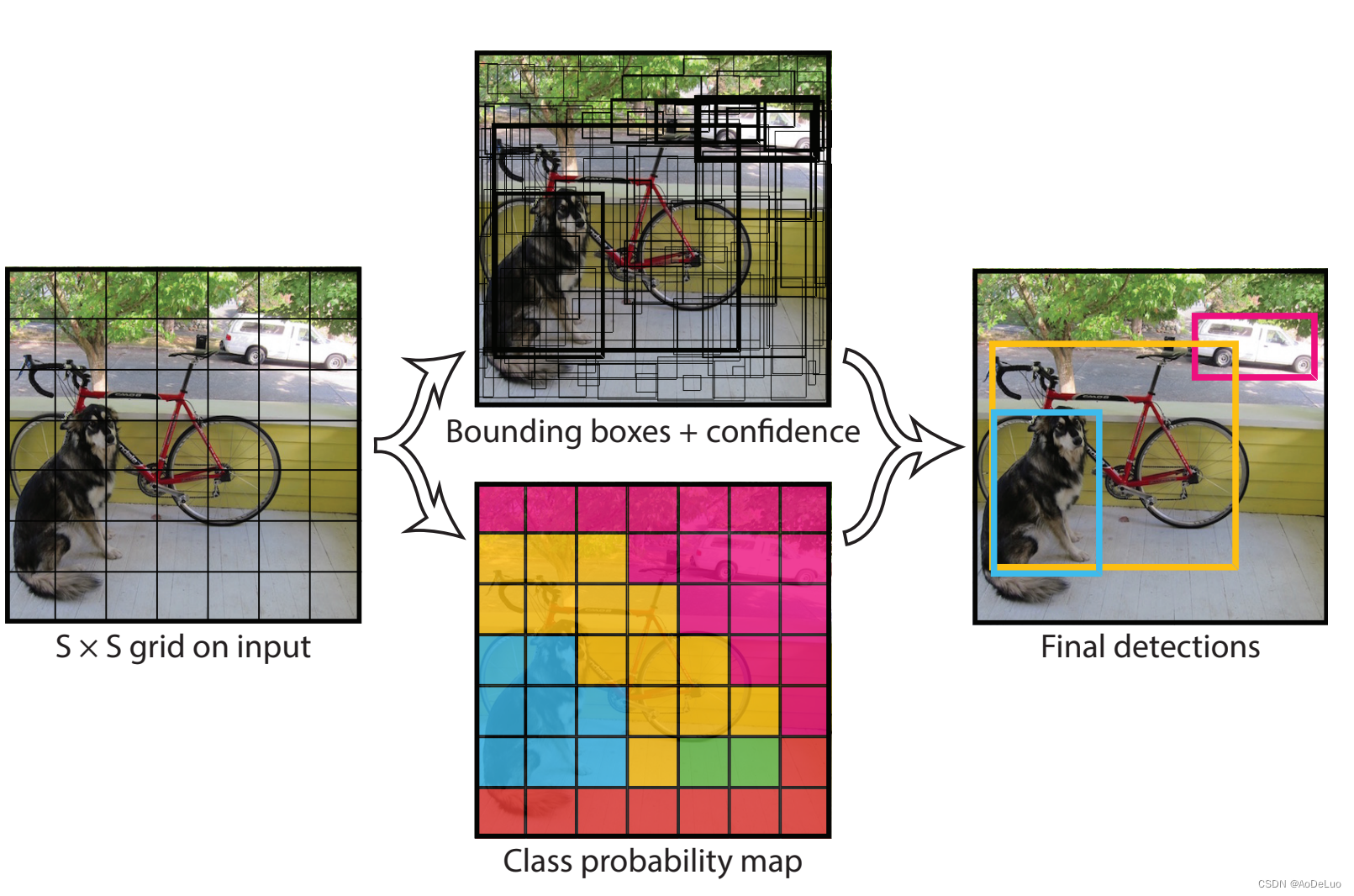
作者在YOLO算法中把物体检测(object detection)问题处理成回归问题,用一个卷积神经网络结构就可以从输入图像直接预测bounding box和类别概率。算法首先把输入图像划分成S×S的格子,然后对每个格子都预测B个bounding boxes,每个bounding box都包含5个预测值:换句话说,如果ground truth落在这个grid cell里,那么Pr(Object)就取1,否则就是0,IOU就是bounding box与实际的groud truth之间的交并比。所以confidence就是这两者的乘积。在yolov1中作者将一幅图片分成7x7个网格(grid cell),由网络的最后一层输出7×7×30的tensor,也就是说每个格子输出1×1×30的tensor。30里面包括了2个bound ing box的x,y,w,h,confidengce以及针对格子而言的20个类别概率,输出就是 7x7x(5x2 + 20) 。
- x,y,w,h和confidence。
- x,y就是bounding box的中心坐标,与grid cell对齐(即相对于当前grid cell的偏移值),使得范围变成0到1;
- w,h进行归一化(分别除以图像的w和h,这样最后的w和h就在0到1范围)。
- confidence代表了所预测的box中含有object的置信度和这个box预测的有多准两重信息
1. 网络的输入
图片大小:448 * 448 * 3 = (64 * 7) * (64 * 7)* 3 = 7 * 7 * (64 * 64 * 3)
也就是说,输入图像大小为448448的图像,被划分为77的网格,一个网格,负责检测输入图片的64 * 64 * 3个非连续的像素,来判断物体的位置、形状以及分类。
2. 网络的输出
YOLOv1把30个输出值,结构化成5 + 5 + 20。

(1) 5 + 5表示:每个网格使用两个先验框进行预测。
每个网格使用两个先验框去寻找是否有目标方框的中心点落在该网格内。
分别用B1(Box1)和B2(Box2)表示。这个2个框,称为“先验框”。
有点类似,每个网格使用两个不同尺寸的渔网去捞鱼(目标),看看能不能捞到目标。
(2) “5”表示:每个先验框包含的预测信息的数量。
方框中心点的坐标(x,y):(x,y)的坐标肯定会落在所属的网格内。
方框的尺寸(width,height):表明了方框的大小。
方框的包含物体目标的置信度C:表明方框的包含物体目标的可能性的大小。如果该方框内,没有包含人任何目标(物体),则置信度为0。如果该方框内,100%包含了目标(物体), 则置信度为1。其他值,表明方框内包含物体目标的可能性的大小。
(3) 20表示:20个分类预测值
每个值代表了某一种分类的“可能性”的预测值,每个可能性是[0, 1] 之间的一个数值。这块就是普通的图像分类,用于确定网格中检测到的目标的分类。这个长度,决定了YOLO V1最多只能识别20种分类目标。
(4) 每个网格能预测几个目标?
在YOLO V1中,虽然使用了两个先验框去找目标,但是每个网格只选用一个框中的预测结果来定位物体:位置+尺寸,依据就是每个框的置信度的大小,选择一个置信度大的框的预测结果。因此,在YOLO V1中,20分类是针对每个网格的,而不是每个先验框的,即每个先验框只需要检测是否有对象或物体。网格进一步的负责对检测到的目标的各种分类的可能性就行预测,最后选择最大可能性的分类输出。因此, YOLO V1中,对一张图而言,最多能够检测 7 * 7 = 49个目标,目标的分类数最大为20种。