YOLOv7是一种优秀的端到端检测算法。YOLOv7由Alexey Bochkovskiy和Chien-Yao Wang等人(YOLOv4团队)于2022年提出。在 5 FPS 到 120 FPS 的范围内,YOLOv7 的速度和准确性都超过了所有已知的物体检测器,在 30 FPS 的所有已知实时物体检测器中,YOLOv7 的准确性最高,达到 56.8% AP。
一、工程总体介绍
yolov7工程文件夹和数据集datasets文件夹在同一级,datasets下面分为images(放图片)和labels(放标签),images和labels下面分为test(测试集)、train(训练集)、val(验证集)三个文件夹。



yolov7文件夹中第一个cfg文件夹存放的是模型配置文件(model.yaml)。data文件夹中存放的是数据集配置文件(data.yaml)和超参数配置文件(hyperparameters.yam)。deploy文件夹中为nvidia triton推理服务器部署的demo。figure文件夹中是yolov7的一些demo结果图(3D检测,关键点检测等)。inference中存放的是带推理的数据(图片,文件夹)。models中存放的是yolov7网络结构组成常用的代码。paper中为yolov7论文。runs为训练、测试的结果。tools中为一些一些ipynb文件格式的工具(模型转换、模型对比等)。utils中存放工具类函数(激活函数、画图函数等)。.gitignore为docker的ignore文件。LICENSE.md为许可文件。README.md为使用说明文件。detect.py检测代码。export.py模型导出代码。hubconf.py为pytorch hub文件。requirements.txt依赖环境文件。test.py测试文件。train.py为yolov7-tiny、yolov7训练文件。train_aux.py为yolov7-w6、yolov7-e6训练文件。 
二、网络结构介绍
1.总体结构图
yolov7总体结构由Input、Backbone、Head、Detect四部分组成。Input为640*640*3的数据输入。Backbone为骨干网络由CBS、ELAN、MP-1组成。Head由CBS、SPPCSPC、E-ELAN、MP-2、RepConv组成。Detect为三个检测头。除了Detect模块代码在models/yolo.py,其余模块代码均在models/common.py。
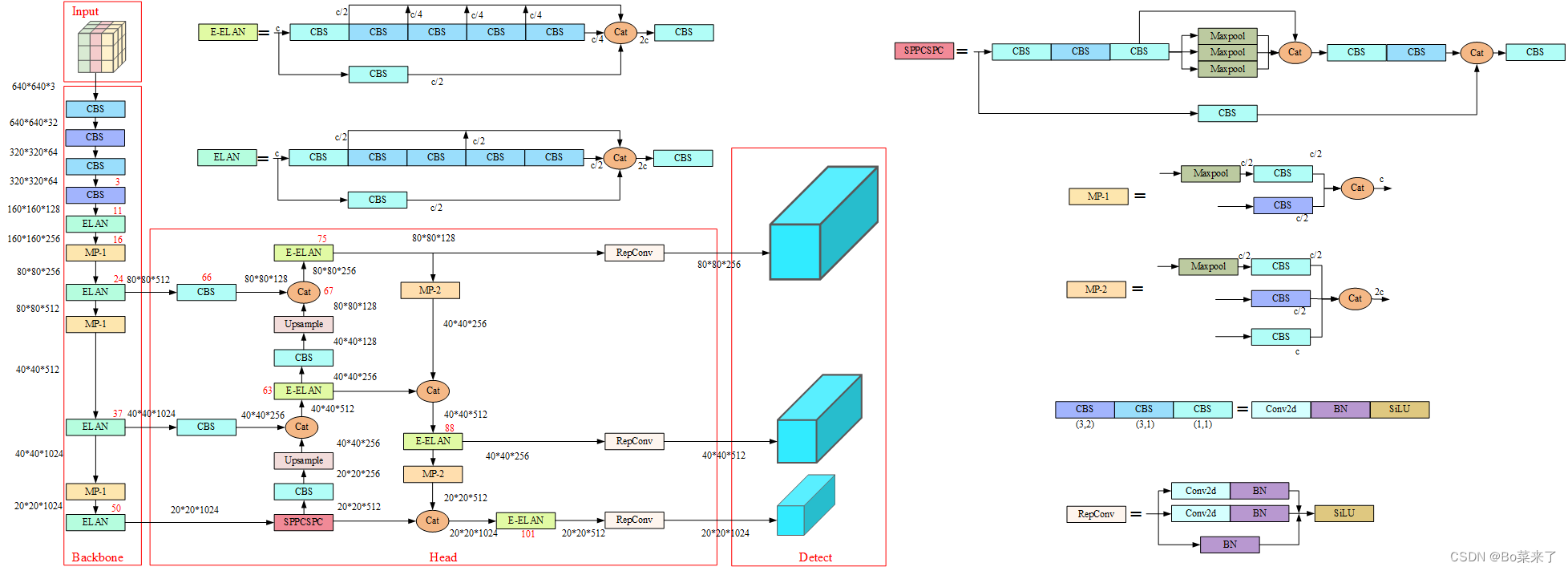
2.CBS
代码如下:
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))结构如下:

其中(3,2)为3*3的卷积核,步长为2。组成为二维卷积、批量归一化、SiLU激活函数。
3.ELAN和E-ELAN
ELAN模块由最长和最短的梯度路径构成,通过最短路径堆叠更多block,学习更多特征。

结构如下(左边E-ELAN,右边ELAN):
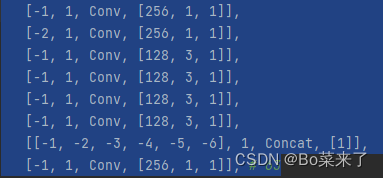
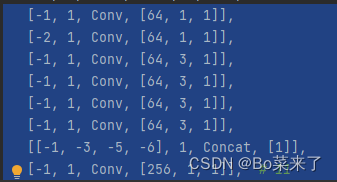

4.MP
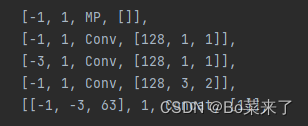
MP的整体作用:实现减少特征损失的下采样。MP-1模块由2个分支组成,MP-2由3个分支组成。第一个分支首先利用Maxpool(最大池化)实现了下采样,接着利用一个1*1的卷积实现通道数的改变。MP-1另一条分支为3*3的卷积核步长为2的卷积,实现了下采样。
网络结构(左边MP-1,右边MP-2):


5. SPPCSP
SPP的作用是实现不同特征尺度信息的融合,利用四个不同尺度的最大池化进行处理,最大池化的池化核大小分别为13x13、9x9、5x5、1x1(1x1即无处理)。CSP模块为两部分,一部分进行了SPP结构处理,一部分通过1*1的卷积进行通道数处理,最终将两部分进行concat。SPPCSP实现了不同特征尺度信息的融合,并且减少了计算量,实现了速度的提升。
代码如下:
class SPPCSPC(nn.Module):
# CSP https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=(5, 9, 13)):
super(SPPCSPC, self).__init__()
c_ = int(2 * c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(c_, c_, 3, 1)
self.cv4 = Conv(c_, c_, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
self.cv5 = Conv(4 * c_, c_, 1, 1)
self.cv6 = Conv(c_, c_, 3, 1)
self.cv7 = Conv(2 * c_, c2, 1, 1)
def forward(self, x):
x1 = self.cv4(self.cv3(self.cv1(x)))
y1 = self.cv6(self.cv5(torch.cat([x1] + [m(x1) for m in self.m], 1)))
y2 = self.cv2(x)
return self.cv7(torch.cat((y1, y2), dim=1))网络结构如下:

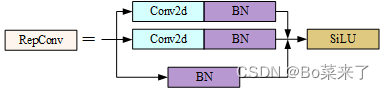
6.RepConv
yolov7在head的最后将Conv替换为RepConv。训练阶段由多分支组成,3x3,1x1,identity(映射)三个分支构成,推理阶段变成了只有一个3x3卷积,减少了参数量,加快了推理速度。RepConv训练过程学更多的特征,推理过程加快速度。
代码如下:
class RepConv(nn.Module):
# Represented convolution
# https://arxiv.org/abs/2101.03697
def __init__(self, c1, c2, k=3, s=1, p=None, g=1, act=True, deploy=False):
super(RepConv, self).__init__()
self.deploy = deploy
self.groups = g
self.in_channels = c1
self.out_channels = c2
assert k == 3
assert autopad(k, p) == 1
padding_11 = autopad(k, p) - k // 2
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
if deploy:
self.rbr_reparam = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=True)
else:
self.rbr_identity = (nn.BatchNorm2d(num_features=c1) if c2 == c1 and s == 1 else None)
self.rbr_dense = nn.Sequential(
nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False),
nn.BatchNorm2d(num_features=c2),
)
self.rbr_1x1 = nn.Sequential(
nn.Conv2d( c1, c2, 1, s, padding_11, groups=g, bias=False),
nn.BatchNorm2d(num_features=c2),
)
def forward(self, inputs):
if hasattr(self, "rbr_reparam"):
return self.act(self.rbr_reparam(inputs))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.act(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)训练过程的结构如下:
7.Detect
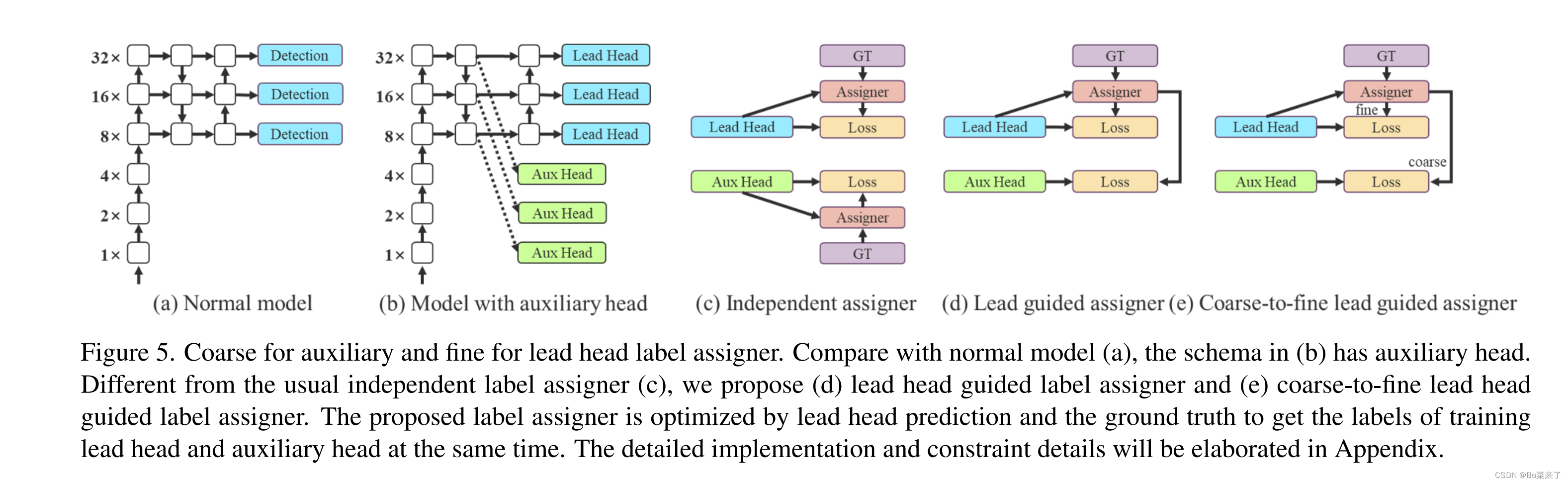
代码在yolo.py的class IDetect(nn.Module)。(d)检测头根据Lead头(领导头)和GT(标签真实值)的结果,通过优化器生成软标签。软标签在Aux头(辅助头)和Lead头训练模型时使用。这样做的原因是Lead头具有相对较强的学习能力,因此由它生成的软标签应该更能代表源数据和目标数据之间的分布和相关性。此外还加入了残差学习,让较浅的Aux头直接学习Lead头学习过的信息,这样Lead头可以更好的专注学习没有学习过的残差信息。(e)加入了微调。
三、训练自己数据
训练过程和其他YOLO大差不差。直接看README.md![]() https://github.com/WongKinYiu/yolov7#readme
https://github.com/WongKinYiu/yolov7#readme