计算机视觉工程师在面试过程中主要考察三个内容:图像处理、机器学习、深度学习。然而,各类资料纷繁复杂,或是简单的知识点罗列,或是有着详细数学推导令人望而生畏的大部头。为了督促自己学习,也为了方便后人,决心将常考必会的知识点以通俗易懂的方式设立专栏进行讲解,努力做到长期更新。此专栏不求甚解,只追求应付一般面试。希望该专栏羽翼渐丰之日,可以为大家免去寻找资料的劳累。每篇介绍一个知识点,没有先后顺序。想了解什么知识点可以私信或者评论,如果重要而且恰巧我也能学会,会尽快更新。最后,每一个知识点我会参考很多资料。考虑到简洁性,就不引用了。如有冒犯之处,联系我进行删除或者补加引用。在此先提前致歉了!
为什么使用激活函数?
很多任务是非线性的
没有激活函数的网络只能实现y=kx+b
这是线性的,无法解决非线性问题
激活函数f()是非线性的
f(kx+b)实现了线性到非线性的转变,提升了网络的表达能力
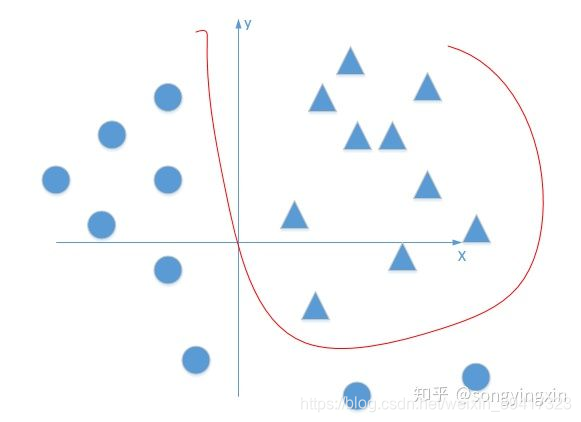
下图就是一个非线性二分类任务的例子
常用激活函数
Sigmoid
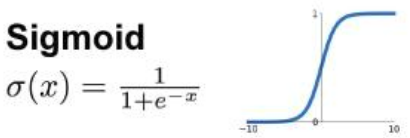
输出是0到1
适用于二分类任务最后一层的输出(输出是0到1,可以认为是概率)
导数最大是0.25
反向传播造成梯度消失
输出不是以0为中心
幂运算复杂度高
基于以上三点,几乎不使用Sigmoid
tanh

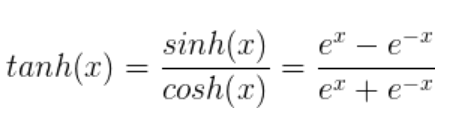
注意:一些面试题问你 tanh(x)=2*Sigmoid(x)-1 对不对?
错的
tanh(x)=2*Sigmoid(2x)-1
Sigmoid的升级版
输出以0为中心
但是依然存在梯度消失、幂运算复杂度高的问题
ReLU
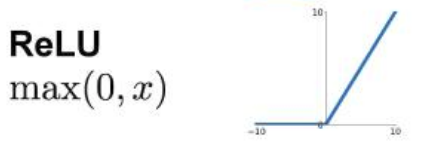
激活函数的第一选择
计算复杂度低
x>0时不存在梯度消失
缺点是Dead ReLU(x<0时,等于0,没有被激活)
输出不是以0为中心
Leaky ReLU(PReLU)

ReLU升级版
解决Dead ReLU
0.1可调
ELU
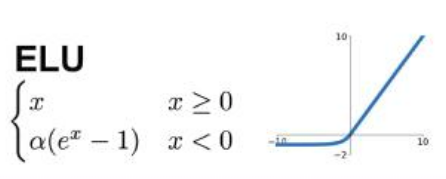
最小值逼近-a,具有饱和性
介于PReLU和ReLU之间
输出更加接近以0为中心,对噪声具有鲁棒性
(这两点不懂,请大佬指教)
幂运算复杂度高
理论上,PReLU和ELU都比ReLU好
但是一般使用ReLU:
- 不用设置a参数
- PReLU和ELU提升不大
- ReLU逻辑相对简单,没有ELU的幂运算
- 如果没有较大提升,使用ReLU的习惯性难以被撼动
Dead ReLU
如果x<0
反向传播的时候ReLU激活函数的导数为0
该神经元的参数就不更新了
与该神经元相连的前面的所有神经元也不更新了
导致一些神经元会失去意义
为什么希望输出以0为中心?
以0为中心,输出有正有负,反向传播梯度有正有负
可以满足有的参数增大,有的参数减小
如果输出全大于0,梯度的正负全部相同
所有参数只可能一起增大或者一起缩小
以上“所有参数”指的是一个神经元对应的所有参数
为什么梯度正负取决于输出(下图的x是上一层的输出)?
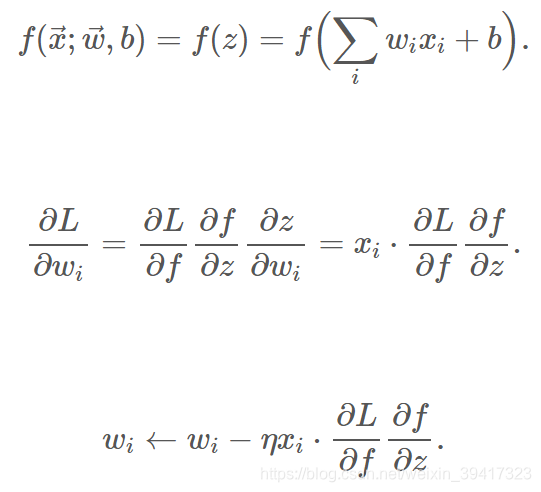
这是反向传播的简单推导
对于同一个神经元,最后一个公式的求导部分是常数
所以,梯度方向取决于x的正负
完
欢迎讨论 欢迎吐槽
