文件生成
1直接进入cd 【pycharm终端即可】
scrapy.strstproject images
cd images
scrapy genspider -t crawl pexels(爬虫主题文件名) pexels.com(网站名称)
步骤设置
注:scrapy框架内部提供两个 Item Pipeline
FilesPipeline 用于下载文件
ImagePipeline 用于下载 图片
1,在settings中导入imagepipeline路径:‘scrapy.pipelines.images.ImagesPipeline’:1
2,添加图片本地保存路径 IMAGE_STORE
3,下载延迟设置
4,在items.py中创建字典
5,在pexels.py(爬虫主体文件)中导入items
细节说明
直接上图
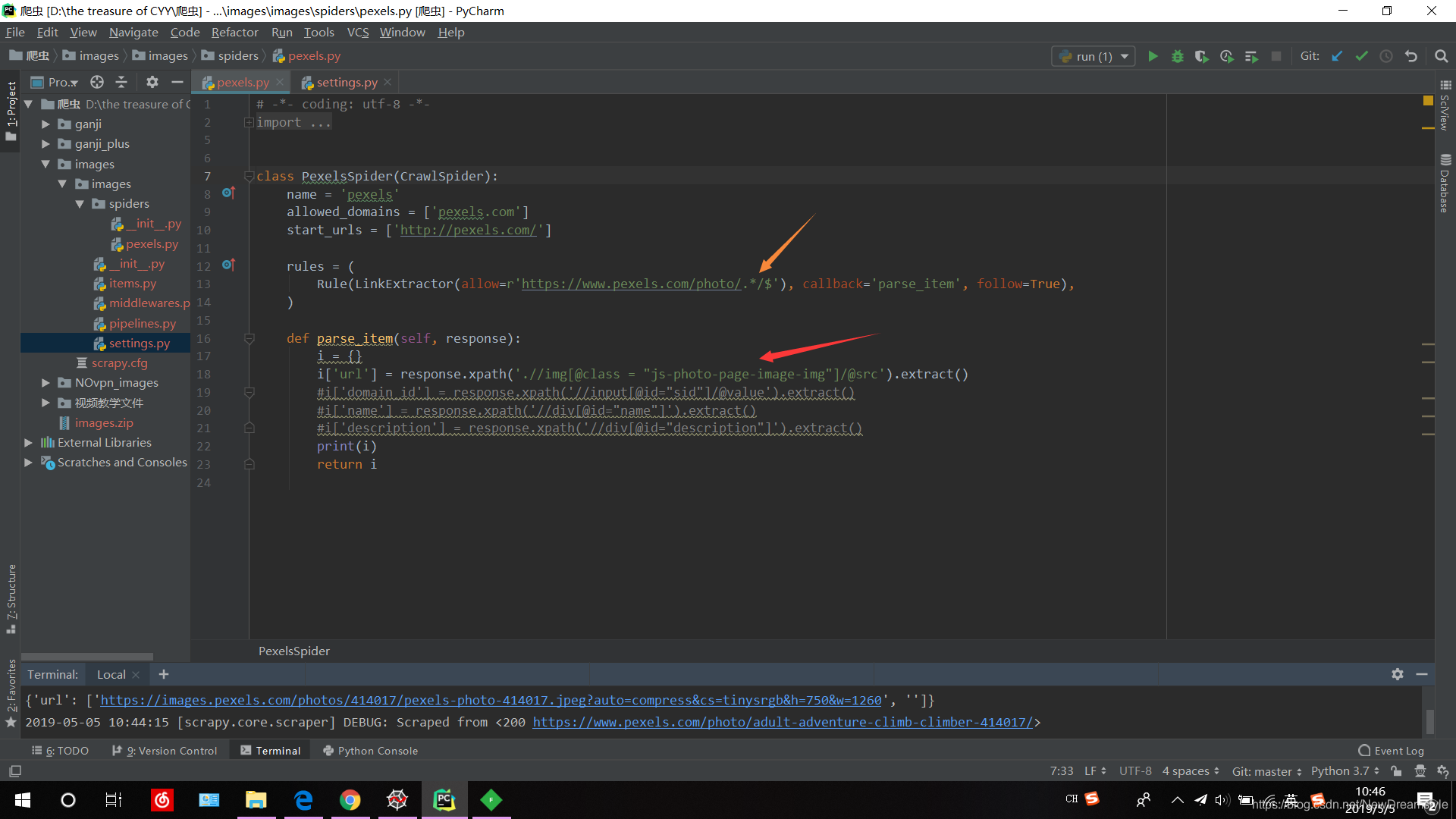


报错记录
raise ValueError(‘Missing scheme in request url: %s’ % self._url)
ValueError: Missing scheme in request url:
图一里的xpath返回(图三)没有问题
图二的xpath返回(图四)报错
google了一下,上图
总结
解决方案还没有找到,毕竟现在没有深入学习源码。我找了一些书籍上的描述(以及课程助教的回答)都建议直接在settings中设置图片宽高,但我认为这并不能完美解决(目标图片限制属性可不只有宽高)
课程链接:网易scrapy课程
------------------------------------------------------分割线19:17分
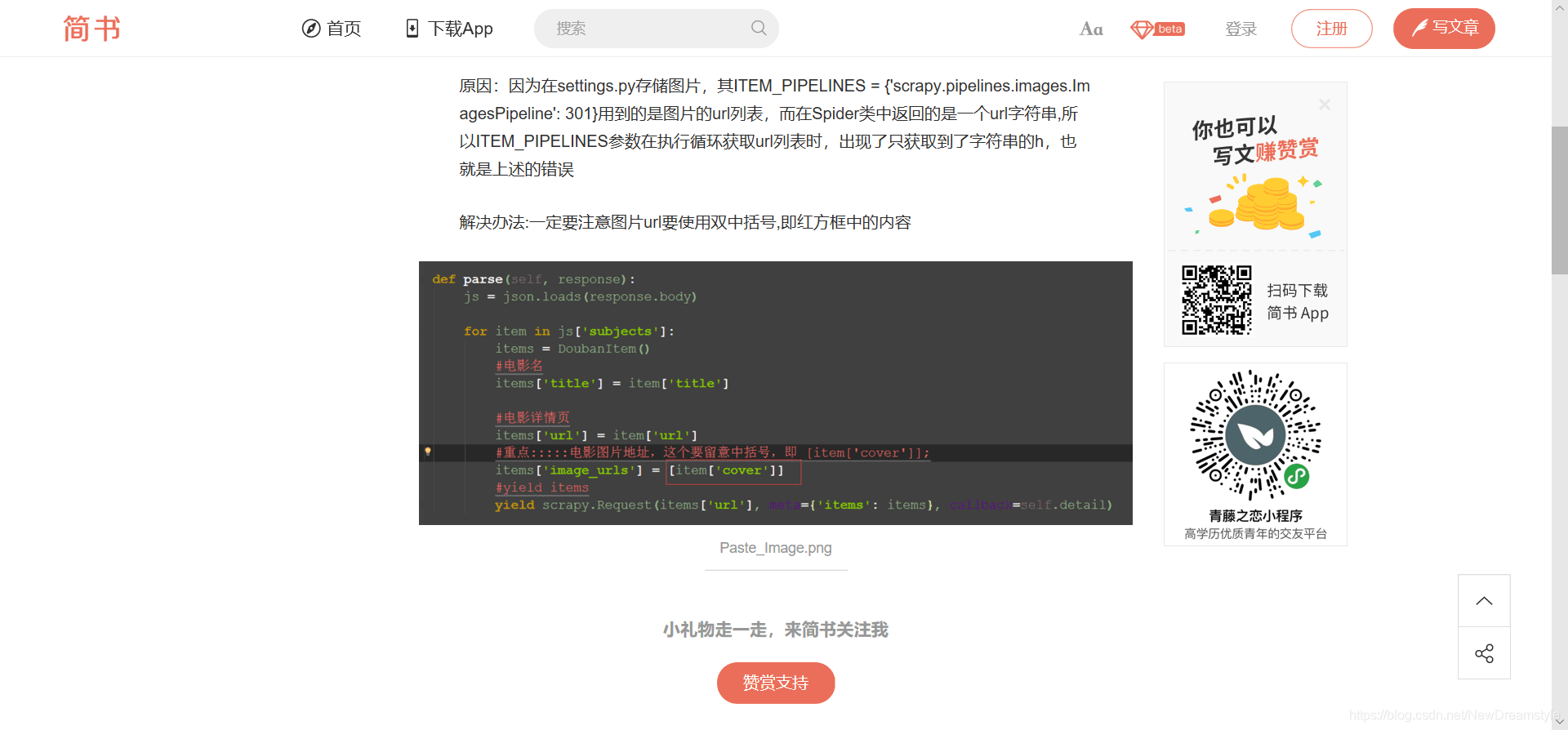
我通过在pipeline管道文件中对URL进行筛选
在settings文件中追加 图片的宽高限制 得到了理想的结果
具体改进在我的git上
但个人感觉还是没有真正的解决,报错的那个xpath毕竟网页里面也返回正常 两者区别仅仅是返回链接数不同 我现在只能通过后处理解决,不能进行预处理,脑瓜疼