scrapy爬虫框架学习(二)scrapy爬取多级网页信息
1爬取目标:
1.1 针对一级页面获取专利详情页的链接信息
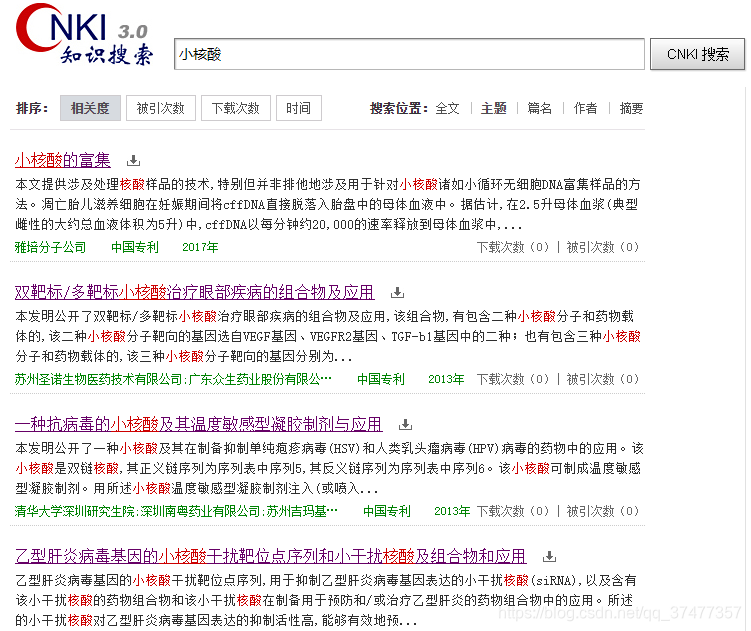
1.2 针对专利详情页进行详细信息
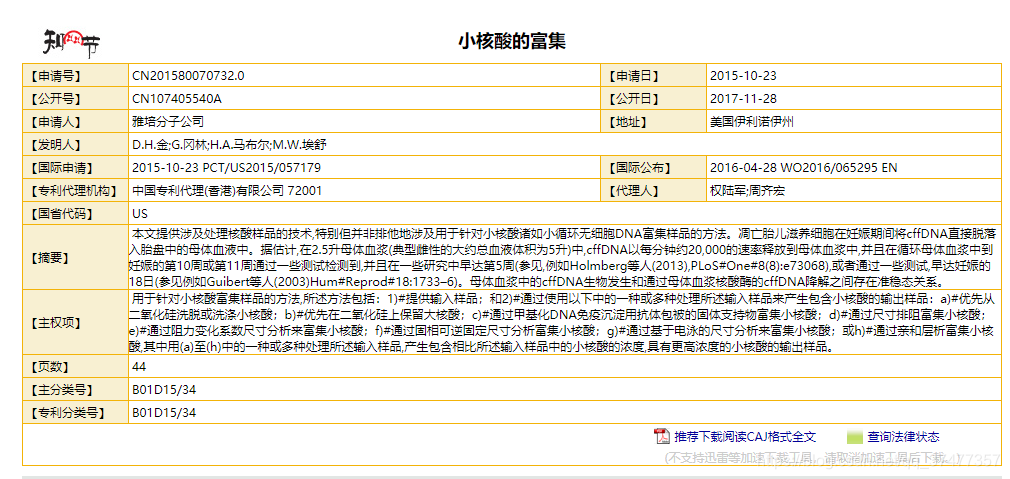
2.项目代码实现
2.1 item.py:定义要收集的详情数据结构
import scrapy
#定义要存储的数据项目
class CnkipatentItem(scrapy.Item):
application_number = scrapy.Field()
application_date = scrapy.Field()
public_number = scrapy.Field()
publication_date = scrapy.Field()
applicant = scrapy.Field()
address = scrapy.Field()
common_applicants = scrapy.Field()
inventor = scrapy.Field()
international_application = scrapy.Field()
international_publishing = scrapy.Field()
into_the_country_date = scrapy.Field()
patent_agencies = scrapy.Field()
agents = scrapy.Field()
original_application_number = scrapy.Field()
province_code = scrapy.Field()
summary = scrapy.Field()
sovereignty_item = scrapy.Field()
page = scrapy.Field()
main_classification_number = scrapy.Field()
patent_classification_Numbers = scrapy.Field()
2.2 patentSpider.py:完成爬取和解析策略
# -*- coding: utf-8 -*-
import scrapy
import re
#引入定义的item数据结构
from cnkiPatent.items import CnkipatentItem
#继承自spider类
class PatentspiderSpider(scrapy.Spider):
name = 'patentSpider'#根据这个名字执行,如果项目中有多个爬虫记得名字要唯一
allowed_domains = ['search.cnki.net']
start_urls = ['http://search.cnki.net/search.aspx?q=%e5%b0%8f%e6%a0%b8%e9%85%b8&rank=relevant&cluster=zyk&val=SCPD']
base_url = 'http://search.cnki.net/'
#response是通过引擎、调度器、下载器工作下载到的的爬取内容
def parse(self, response):
#从一级页面爬取专利详情链接
patentTitles = response.xpath('//div[@class="wz_content"]')
for patentTitle in patentTitles:
patent_url = patentTitle.xpath('.//h3/a/@href').get()
#对每一个详情进行解析
yield scrapy.Request(url=patent_url,callback=self.parse_item,dont_filter=True)
#获取下一页一级页面
next_url = response.xpath('//div[@class="articles"]/p[@id="page"]'
'/a[@class="n"]/@href').get()
print(next_url)
if next_url is not None:
# 后续给的链接因为已经在这个域里面所以没有开头的域名,要加上
next_url = self.base_url + next_url
yield scrapy.Request(url=next_url,callback=self.parse)
#返回存储的数据结构
#item = CnkipatentItem()
#yield item
def parse_item(self,response):
patent_details = response.xpath('//table[@id="box"]//td/text()').extract()
item = CnkipatentItem()
item['application_number'] = re.sub(r'\xa0','',patent_details[1])
item['application_date'] = re.sub(r'\xa0','',patent_details[3])
item['public_number'] = re.sub(r'\xa0','',patent_details[5])
item['publication_date'] = re.sub(r'\xa0','',patent_details[7])
item['applicant'] = re.sub(r'\xa0','',patent_details[9])
item['address'] = re.sub(r'\xa0','',patent_details[11])
item['common_applicants'] = re.sub(r'\xa0','',patent_details[13])
item['inventor'] = re.sub(r'\xa0','',patent_details[15])
item['international_application'] = re.sub(r'\xa0','',patent_details[17])
item['international_publishing'] = re.sub(r'\xa0','',patent_details[19])
item['into_the_country_date'] = re.sub(r'\xa0','',patent_details[21])
item['patent_agencies'] = re.sub(r'\xa0','',patent_details[23])
item['agents'] = re.sub(r'\xa0','',patent_details[25])
item['original_application_number'] = re.sub(r'\xa0','',patent_details[27])
item['province_code'] = re.sub(r'\xa0','',patent_details[29])
item['summary'] = re.sub(r'\xa0','',patent_details[31])
item['sovereignty_item'] = re.sub(r'\xa0','',patent_details[33])
item['page'] = re.sub(r'\xa0','',patent_details[35])
item['main_classification_number'] = re.sub(r'\xa0','',patent_details[37])
item['patent_classification_Numbers'] = re.sub(r'\xa0','',patent_details[39])
yield item
2.3 pipelines.py:定义存储方法,用json为例
import json
import pandas as pd
class CnkipatentPipeline(object):
#打开时的操作,例如打开要存储的文件:txt、json等
def open_spider(self,spider):
self.file = open('小核酸.json', 'wb')
#将spider中parse函数yield返回来的内容装进item给到这个函数
def process_item(self, item, spider):
data = json.dumps(dict(item), ensure_ascii=False, indent=4) + ','
#编码
self.file.write(data.encode('utf-8'))
#关闭spider时的操作,例如关闭要存储的文件
def close_spider(self,spider):
self.file.close()
3.得到的数据
仅以一条数据为例
{
"application_number": "CN201210437612.8",
"application_date": "2012-11-06",
"public_number": "CN102899327A",
"publication_date": "2013-01-30",
"applicant": "清华大学深圳研究生院;深圳南粤药业有限公司;苏州吉玛基因股份有限公司",
"address": "518055 广东省深圳市南山区西丽镇深圳大学城清华校区",
"common_applicants": "",
"inventor": "张雅鸥;王纠;何杰;谢伟东;许乃寒;李颖;张佩琢;苏宏瑞;万刚;吕青;卢锦华;柳忠义",
"international_application": "",
"international_publishing": "",
"into_the_country_date": "",
"patent_agencies": "北京纪凯知识产权代理有限公司 11245",
"agents": "关畅;王慧凤",
"original_application_number": "",
"province_code": "44",
"summary": "本发明公开了一种小核酸及其在制备抑制单纯疱疹病毒(HSV)和人类乳头瘤病毒(HPV)病毒的药物中的应用。该小核酸是双链核酸,其正义链序列为序列表中序列5,其反义链序列为序列表中序列6。该小核酸可制成温度敏感型凝胶制剂。用所述小核酸温度敏感型凝胶制剂注入(或喷入)阴道或口腔等不规则腔道,能抑制上述腔道和宫颈上皮细胞中宿主B2M基因的表达和或外来的HPV?E7的表达,从而能用于抑制HSV-1病毒的人类乳头瘤病毒(HPV)感染和/或治疗HVP所致宫颈癌前病变。",
"sovereignty_item": "一种小核酸,是双链核酸,其正义链序列为序列表中序列5,其反义链序列为序列表中序列6。",
"page": "25",
"main_classification_number": "C12N15/113",
"patent_classification_Numbers": "C12N15/113;A61K48/00;A61K9/06;A61P35/00;A61P31/20;A61P31/22"
}
