第一次尝试爬取—>[Python爬虫]爬虫实例:三种方式爬取PEXELS图片
在爬取PEXELS时,遇到了这样问题:
页面使用Ajax的异步加载技术来实现分页,所以通过request.text无法获取动态加载的内容.而如果想正确获取这些数据,则需要使用名为逆向工程的过程(“抓包”).PS:如果对上面的文字感到疑惑,那么可以阅读下面的例子和说明,做基础的了解.
例如:要在PEXELS上看猫片 https://www.pexels.com/search/cat/ ,我们虽然在浏览器中看到很多图片,如图:

但是使用在response能爬到的下载链接却只有这么一点:
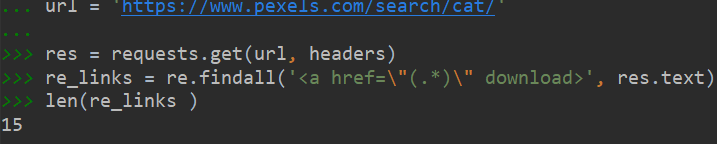
意味着网站的每一页只刷新15张图片,每次拖动滚动条向下,才再次刷新15张图片.
异步加载的说明
传统的网页如果需要更新内容,必须重载整个网页页面,网页加载速度慢,用户体验差,而且数据传输少,会造成带宽浪费.异步加载技术(AJAX),是指一种创建交互式网页应用的网页开发技术.通过在后台与服务器进行少量数据交换,AJAX可以使网页实现异步更新.意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新.
逆向工程的说明
因为使用异步加载技术后,不再是立刻加载所有的网页内容然后返回response就完事了,所以展示的新内容就不再HTML的源码中,无法抓取这些新的数据.于是我们需要抓取这些通过异步加载方法的网页数据,需要了解网页是如何加载这些数据,这个过程就叫做逆向过程.
逆向工程的实践
通过逆向工程,能够找到网页新加载的数据以及对应的新页面用于设计新的爬虫代码.
打开网页https://www.pexels.com/search/cat/ ,按F12打开开发者工具,选择Network选项卡,找到并点击XHR,之后向下拖动滚动条,就能发现右侧刷新出来一些新的文件,如图:

点第一个文件看到Headers请求的URL,https://www.pexels.com/search/cat/?page=2&format=js&seed=2018-11-15 03:21:06 +0000

然后点Response

复制内容到文本

这不就是我要爬取的图片的地址吗?
https://www.pexels.com/search/cat/?page=2&format=js&seed=2018-11-15 03:21:06 +0000
猜测上面网址将?page=2改为page=x就能得到第x页的信息了,将后面的删掉后直接访问也没问题了:https://www.pexels.com/search/cat/?page=3
就这样,我们得到了需要爬取的网页.

印证了前面的每一页刷新15张图片的结论.
现在知道了网页的地址,那么爬虫修改起来也很方便,
爬虫代码
import requests
import re
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/67.0.3396.79 Safari/537.36'
}
def pic_scratch(url):
res = requests.get(url, headers)
links = re.findall('<a href=\"(.*)\" download>', res.text)
for link in links:
pic = requests.get(link, headers)
pic_name = re.search('(?<=dl=).*\.jpg', link).group()
with open('d:/cat/' + pic_name, 'wb') as pf:
pf.write(pic.content)
print("完成图片下载:" + pic_name)
if __name__ == '__main__':
start_time = time.time()
urls = ['https://www.pexels.com/search/cat/?page=={}'.format(i) for i in range(1, 7)]
for url in urls:
pic_scratch(url)
end_time = time.time()
print("总用时:", end_time - start_time)
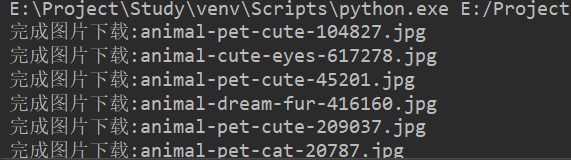
爬取结果

写在最后
为什么图片没有截全部,因为下载真的超!级!慢,对于现在这个爬虫手段,是单进程爬虫,也就是说,在每爬取一张图片时,必须先等待加载完这张图片,再爬下一张,可见如果像在网络较差的地方,那么加载时间将会非常长,不划算.所以在下一次爬取中,我将实现多进程爬虫,以加快爬取速度