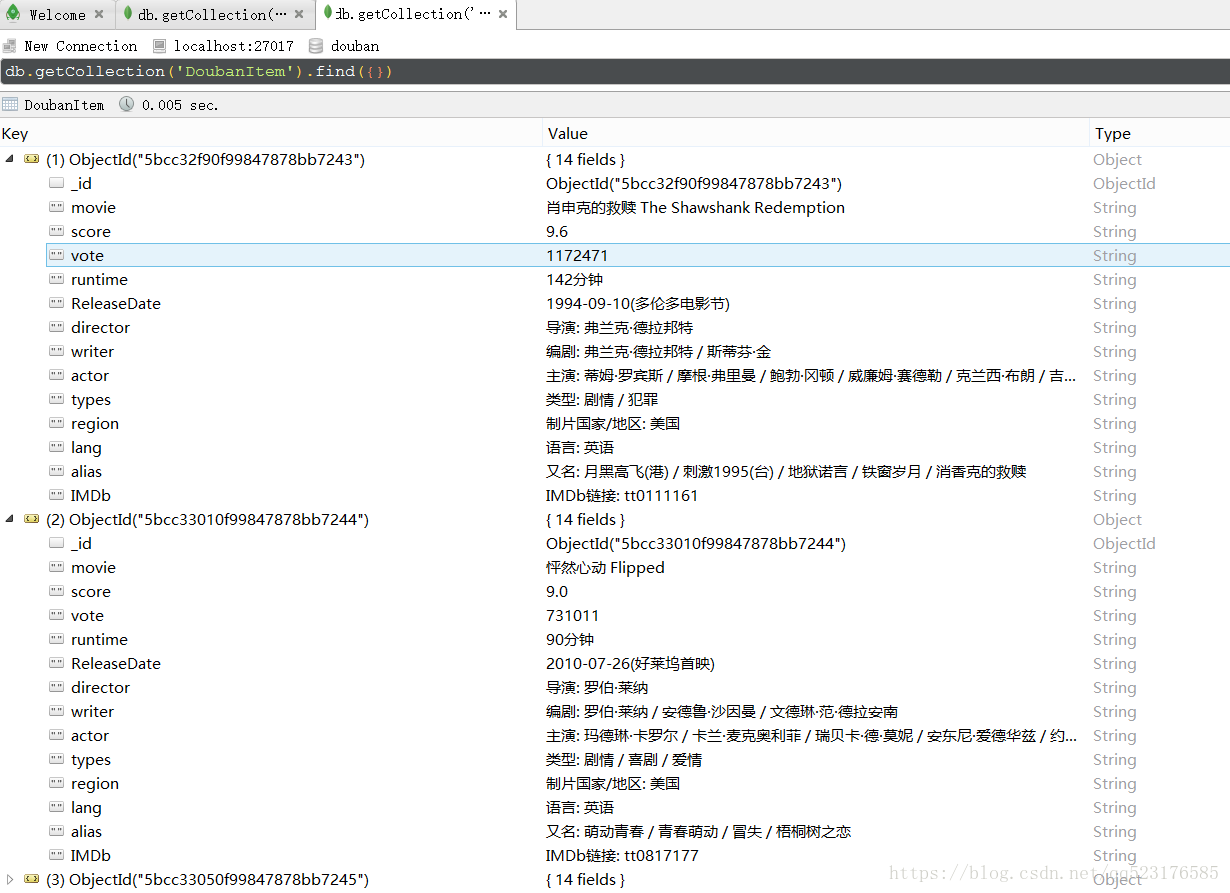
1.新建项目及使用crawl模板
2.页面解析
rules = (Rule(LinkExtractor(allow=r'subject/\d+/',restrict_css = '.hd > a[class = ""]'), callback='parse_item', follow=True), #获取每个电影详情的url
Rule(LinkExtractor(restrict_css='.next a')) ) #获取下一页3.item定义
from scrapy import Item,Field
class DoubanItem(Item):
table = 'movies' #MySql表名称
movie = Field() #电影名
director = Field() #导演
writer = Field() #编剧
actor = Field() #主演
types = Field() #类型
region = Field() #国家和地区
lang = Field() #语音
ReleaseDate = Field() #上映日期
runtime = Field() #片长
alias = Field() #其它译名
IMDb = Field() #IMDb链接
score = Field() #豆瓣评分
vote = Field() #投票人数4.新建MySql数据库
#coding=utf-8
import pymysql
def setMySql():
db = pymysql.connect(host = 'localhost',user = 'root',password = '123456',port = 3306)
cursor = db.cursor() #设置游标
sql = "CREATE DATABASE doubanTop DEFAULT CHARACTER SET utf8" #新建一个数据库
cursor.execute(sql)
db = pymysql.connect(host = 'localhost',user = 'root',password = '123456',port = 3306,db = "doubanTop") #连接到doubanTop数据库
cursor = db.cursor() #设置游标
#新建一张表
sql = """CREATE TABLE IF NOT EXISTS movies(movie VARCHAR(255) NOT NULL,director VARCHAR(255) NOT NULL,writer VARCHAR(255) NOT NULL,actor VARCHAR(512) NOT NULL,types VARCHAR(255) NOT NULL,
region VARCHAR(255) NOT NULL,lang VARCHAR(255) NOT NULL,ReleaseDate VARCHAR(255) NOT NULL,runtime VARCHAR(255) NOT NULL,alias VARCHAR(255) NOT NULL,IMDb VARCHAR(255) NOT NULL,
score VARCHAR(255) NOT NULL,vote VARCHAR(255) NOT NULL,PRIMARY KEY(movie))"""
cursor.execute(sql) #执行sql语句,即建表
db.close()
if __name__=='__main__':
setMySql() 5.设置MongoDBpipeline
import pymongo
class MongoPipeline(object):
def __init__(self,mongo_url,mongo_db):
self.mongo_url = mongo_url
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls,crawler):
return cls(
mongo_url = crawler.settings.get('MONGO_URL'),
mongo_db = crawler.settings.get('MONGO_DB')
)
def open_spider(self,spider):
self.client = pymongo.MongoClient(self.mongo_url)
self.db = self.client[self.mongo_db]
def process_item(self,item,spider):
name = item.__class__.__name__
self.db[name].insert(dict(item))
return item
def close_spider(self,spider):
self.client.close()6.设置MySqlPipeline
import pymysql
class MysqlPipeline():
def __init__(self,host,database,user,password,port):
self.host = host
self.database = database
self.user = user
self.password = password
self.port = port
@classmethod
def from_crawler(cls,crawler):
return cls(
host = crawler.settings.get('MYSQL_HOST'),
database = crawler.settings.get('MYSQL_DATABASE'),
user = crawler.settings.get('MYSQL_USER'),
password = crawler.settings.get('MYSQL_PASSWORD'),
port = crawler.settings.get('MYSQL_PORT'),
)
def open_spider(self,spider):
self.db = pymysql.connect(self.host,self.user,self.password,self.database,charset = 'utf8',port = self.port)
self.cursor = self.db.cursor()
def close_spider(self,spider):
self.db.close()
def process_item(self,item,spider):
data = dict(item)
keys = ','.join(data.keys())
values = ','.join(['%s'] * len(data))
sql = 'insert into %s (%s) values (%s)' % (item.table,keys,values)
self.cursor.execute(sql,tuple(data.values()))
self.db.commit()
return item7.数据解析
import re
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from douban.items import DoubanItem
from bs4 import BeautifulSoup
class Doubantop250Spider(CrawlSpider):
name = 'doubanTop250'
#allowed_domains = ['movie.douban.com/']
start_urls = ['http://movie.douban.com/top250/']
rules = (
Rule(LinkExtractor(allow=r'subject/\d+/',restrict_css = '.hd > a[class = ""]'), callback='parse_item', follow=True),
#Rule(LinkExtractor(restrict_xpaths='//span[@class = "next"]//a[contains(.,"后页")]'))
Rule(LinkExtractor(restrict_css='.next a'))
)
def parse_item(self, response):
item = DoubanItem()
item['movie'] = response.css('span[property="v:itemreviewed"]::text').extract_first()
item['score'] = response.css('strong[class="ll rating_num"]::text').extract_first()
item['vote'] = response.css('.rating_people>span::text').extract_first()
item['runtime'] = response.css('span[property="v:runtime"]::text').extract_first()
item['ReleaseDate'] = response.css('span[property="v:initialReleaseDate"]::text').extract_first()
soup = BeautifulSoup(response.text,'lxml')
info = soup.select_one('div[id="info"]').text
item['director'] = re.findall(r'(导演:.*?)\n',info)[0]
item['writer'] = re.findall(r'(编剧:.*?)\n', info)[0]
item['actor'] = re.findall(r'(主演:.*?)\n',info)[0]
item['types'] = re.findall(r'(类型:.*?)\n', info)[0]
item['region'] = re.findall(r'(制片国家/地区:.*?)\n', info)[0]
item['lang'] = re.findall(r'(语言:.*?)\n', info)[0]
item['alias'] = re.findall(r'(又名:.*?)\n', info)[0]
item['IMDb'] = re.findall(r'(IMDb链接:.*?)\n', info)[0]
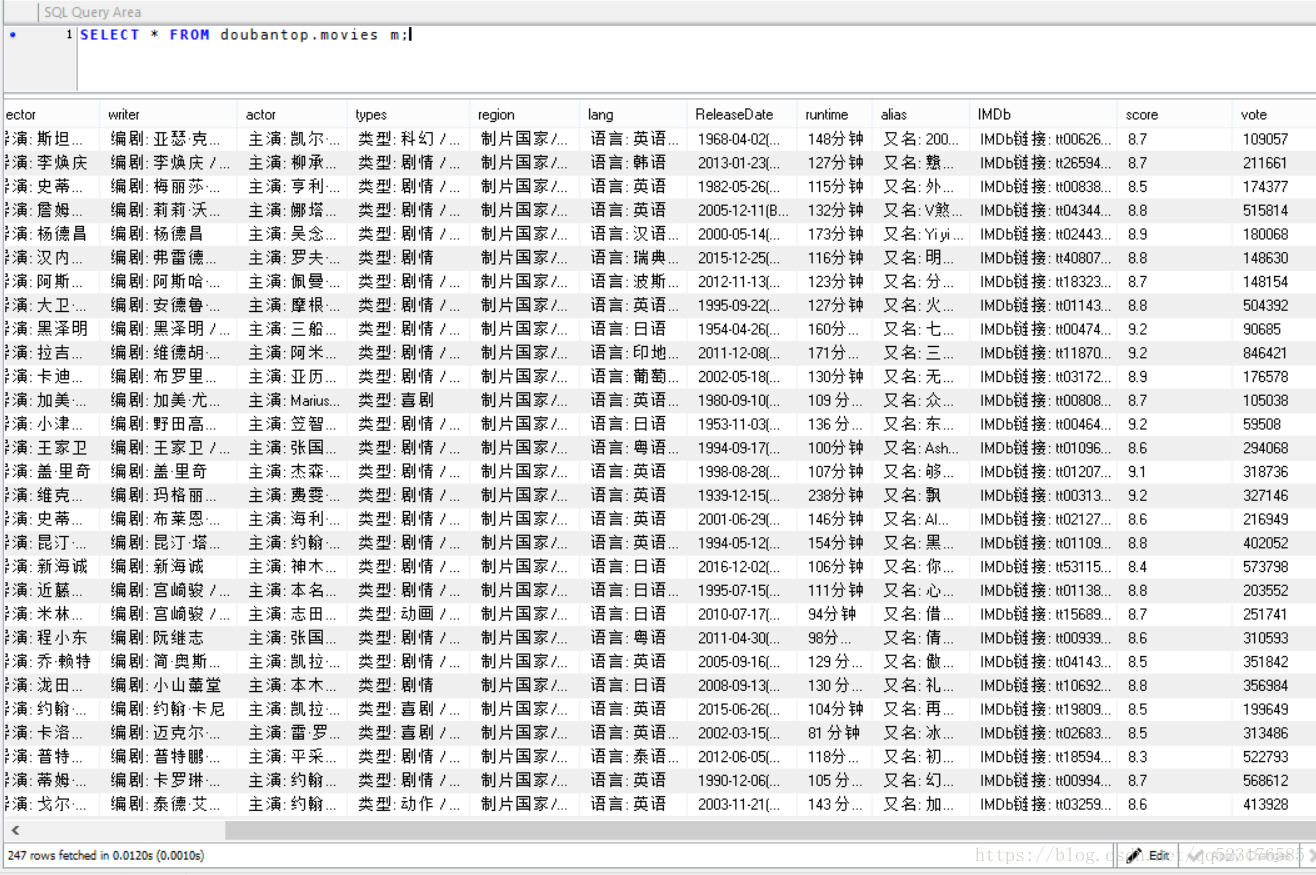
yield item8.运行结果
MySql数据如下图:
MongoDB数据如下图: