本案例使用的框架为CrawlSpider框架,与传统Spider框架相比能够快速的实现页面跳转的功能,且本案例描述了随机替换User-Agent的“反反”爬虫思想,值得读者细心研究。
- 使用
scrapy genspider –t crawl cf “circ.gov.cn”创建爬虫
1.项目框架展示
2.项目爬取网页展示
3.cf.py文件
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
import re
#scrapy genspider -t crawl cf circ.gov.cn
class CfSpider(CrawlSpider):
name = 'cf'
allowed_domains = ['circ.gov.cn']
start_urls = ['http://circ.gov.cn/web/site0/tab5240/module14430/page1.htm']
#定义提取url地址规则(循环执行)---(不需要补充完整的url地址,会自动补充)
rules = (#连接提取器 follow-当前url地址的响应是否重新经过rules来提取url地址(不写时只执行一次,不断提取下一页时一定要写)
Rule(LinkExtractor(allow=r'/web/site0/tab5240/info\d+\.htm'), callback='parse_item'),#提取详情页
# Rule(LinkExtractor(allow=r'/web/site0/tab5240/module14430/page\d+\.htm'), follow=True),#跳转下一页-匹配第一个,一直到无法匹配到下一些URL地址
)
#parse函数有特殊功能,不能定义
def parse_item(self, response):
item = {}
item["title"] = re.findall("<!--TitleStart-->(.*?)<!--TitleEnd-->", response.body.decode())[0]
item["publish_date"] = re.findall("发布时间:(20\d{2}-\d{2}-\d{2})", response.body.decode())[0]
print(item)
4.middlewares.py文件(实现随机设置User-Agent)
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
import random
class RandomUserAgentMiddlewares:#下载中间件,每次请求都会用他
def process_request(self, request, spider):
ua = random.choice(spider.settings.get("USER_AGENTS_LIST"))
print("执行到这里")
request.headers["User-Agent"] = ua
class CheckUserAgent:#检查请求头的user—agent是否不同
def process_response(self, request, response, spider):
# print(dir(response.request))
print(request.headers["User-Agent"])
return response
5.settings.py文件
# -*- coding: utf-8 -*-
# Scrapy settings for circ project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'circ'
SPIDER_MODULES = ['circ.spiders']
NEWSPIDER_MODULE = 'circ.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
LOG_LEVEL = "WARNING"
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'circ.middlewares.CircSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'circ.middlewares.RandomUserAgentMiddlewares': 543,
'circ.middlewares.CheckUserAgent':544
}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# 'circ.pipelines.CircPipeline': 300,
#}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
USER_AGENTS_LIST = [ "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)", "Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)", "Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)", "Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0", "Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5" ]
- ROBOTSTXT_OBEY设置为False
- LOG_LEVEL = “WARNING”
- 不要忘记打开下载中间件(每次请求都会先经过下载中间件)DOWNLOADER_MIDDLEWARES
- 准备一个有多个User-Agent的列表USER_AGENTS_LIST
6.结果展示
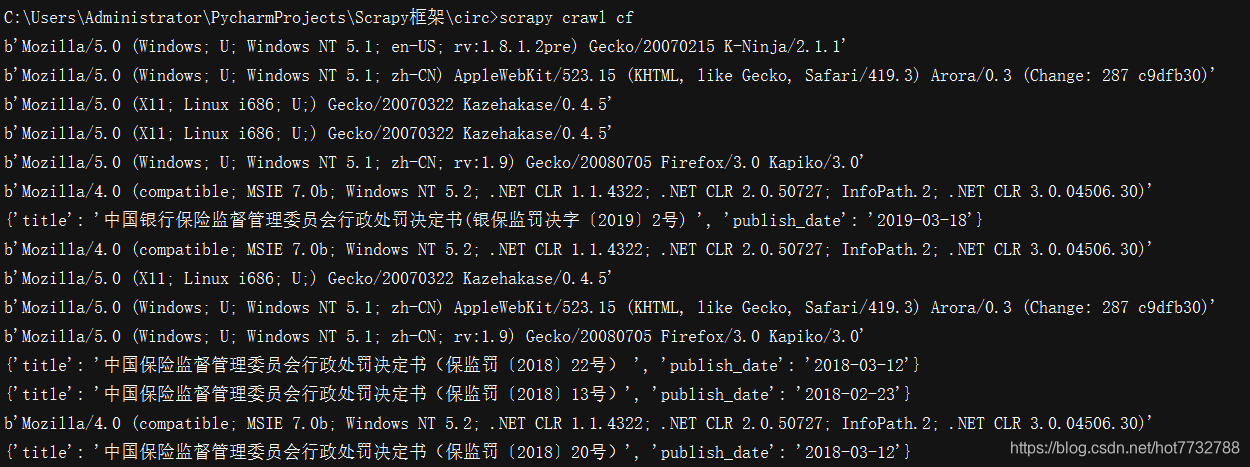
- 输出了相应的爬取内容和当前User-Agent的设置值。