主要对2014年那篇基础论文:Two-stream convolutional networks for aciton recognition 进行代码复现,在这过程中遇到了不少的问题,在此记录一下,也希望能给别人提供一些帮助。
1.InvalidArgumentError (see above for traceback): indices[100] = [100,101] is out of bounds: need 0 <= index < [101,101]
用法:使用稀疏编码将UCF101数据集中的视频的标签转换为one_hot标签。
报错语句:onehot_labels = tf.sparse_to_dense(concated, tf.stack([batch_size, 101]), 1.0, 0.0)
报错原因:尚不清楚
解决办法:concated中表示的是将索引和标签表示的向量按行进行拼接,而ucf101中给出的类别标签是从1开始,将labels中标签的起止位置从1-101,转换为从0-100。
- out of memory
用法:使用cv2对视频逐帧进行光流的计算,使用pycharm开发,在计算大约230个视频后报内存溢出的错误。
报错语句:cv2.calcOpticalFlow()
报错原因:内存溢出,对视频进行计算时产生了一些局部变量存储在内存中没有释放而导致内存溢出。
解决办法:将ucf101中的13320个视频进行分组,使用嵌套的for循环,外层循环进行组数的迭代,内层循环对每组的视频进行迭代,每计算完一组视频的光流,将图像存储后使用gc.collect()清除缓存,并使用try,catch语句,一旦光流计算部分出错,捕获错误并进行gc.collect()
3.光流计算的代码没有报错,但计算后的结果的图像显示为全黑色。
用法:使用cv2模块中的calcOpticalFlow计算光流
报错原因:无报错
解决办法:在获得计算结果并将其分成x和y两个方向进行存储时,指定flow的编码格式,dtype=np.uint8(详细内容看下面问题5)
4.TypeError: a bytes-like object is required, not ‘str’
用法:使用csv模块创建一个csv文件,用于存储ucf101中的类别数字,类别名和onehot后的类别标签,第一行想将表头内容写进去。
报错原因:传入的是一个字符串而不是二进制类型。
解决办法:将表头字符串转换为二进制类型,并且,在python3.x中,写入csv数据的文件打开方式要写为‘w’,而python2.x中写为‘wb’。具体内容请参考这里
- 计算后的光流矩阵转换为图像进行存储,在程序运行时可以看到图像的内容,但将图像存储到文件夹后保存的仅为全黑的图像,并且存储的全部光流值为0。
用法:使用cv2模块中的calcOpticalFlow计算光流,将返回的每一个点的位移值的矩阵保存为图像。
报错原因:无报错,但imshow()的是正常的图像,而保存的是全黑的图像,也就是说位移值保存为0.
解决办法:根据前面的问题3,猜测可能是指定的保存的矩阵的数据类型超出精度,打印测试后发现像素点位移的最小值的精度在1e-10,而问题三中的解决方式将图像转化为了二值图像,所以在解决问题时对矩阵进行归一化,采用的归一化方法较为简单,即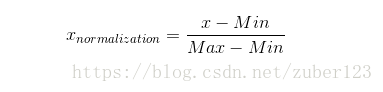
未完。。。