https://arxiv.org/pdf/1904.09925.pdf
https://github.com/tensorflow/tpu/tree/master/models/official/retinanet
https://github.com/leaderj1001/Attention-Augmented-Conv2d pytorch版
https://github.com/gan3sh500/attention-augmented-conv tensorflow版
卷积操作具有显着的弱点,因为它仅在本地邻域上操作,因此缺少全局信息。Self-attention已经成为捕获长程相互作用,但主要应用于序列建模和生成建模任务。在本文中,我们考虑将Self-attention用于判别性视觉任务作为卷积的替代。我们引入了一种新颖的二维相对自我关注机制,证明在将卷积替换为图像分类的独立计算原语方面具有竞争力。我们在对照实验中发现,当结合卷积和自我关注时,获得了最好的结果。因此,我们建议通过将卷积特征映射与通过自我关注产生的一组特征映射相结合来增强卷积算子的自我关注机制。
Introduction
卷积层的设计主要是通过有限的感知区域与权重共享进行等效翻译。
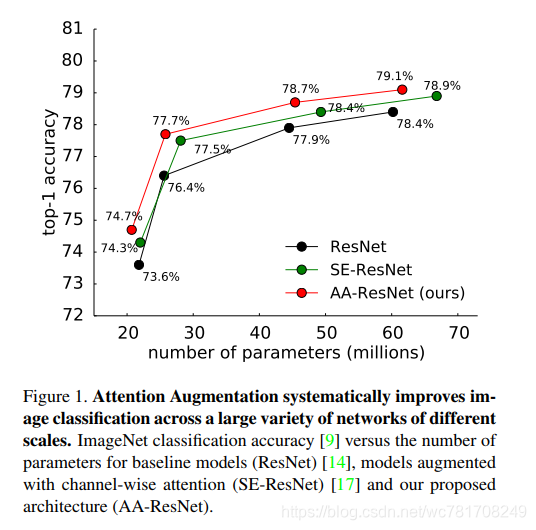
我们的自我关注配方证明了完全替代卷积的竞争力,但是我们在对照实验中发现,当将两者结合时获得最佳结果。
Convolutional networks
现代计算机视觉建立在图像分类任务(如CIFAR-10 [22]和mageNet [9])上学习的强大图像特征上。这些数据集已被用作基准,用于描述更广泛的任务中更好的图像特征和网络架构[21]。例如,改进“骨架”网络通常会导致对象检测[19]和图像分割[6]的改进。这些观察结果激发了新架构的研究和设计,这些架构通常来自跨空间尺度和跳过连接的卷积运算的组合。
Attention mechanisms in networks
作为用于建模序列的计算模块,Attention已被广泛采用,因为其能够捕获长距离交互。自我关注的Transformer架构在机器翻译中实现了最先进的结果。与卷积合作使用self-attention是最近自然语言处理领域工作所共有的主题。

Attention Augmented Convolution
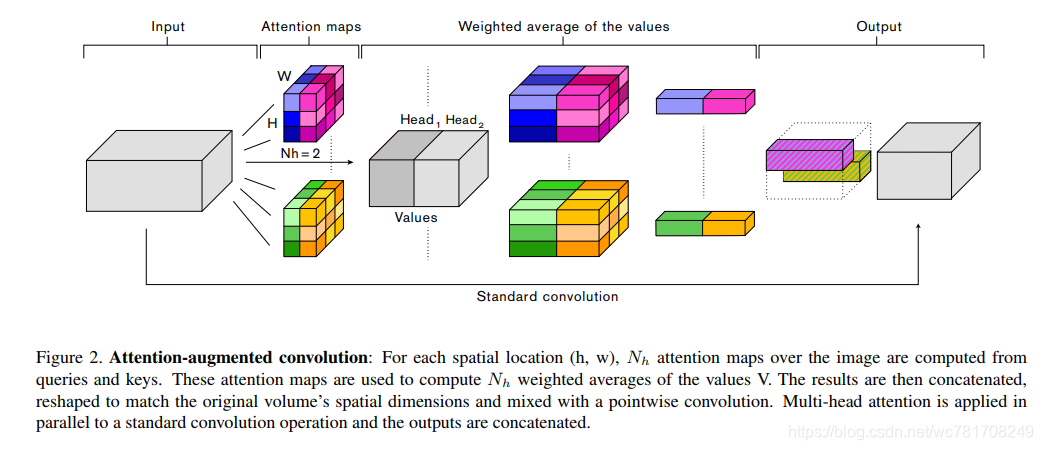
多个先前提出的关于图像的注意机制[17,16,30,44]表明卷积算子受其局部性和对全局背景缺乏理解的限制。这些方法通过重新校准卷积特征映射来捕获远程依赖性。特别是,Squeeze-and-Excitation(SE)[17]和GatherExcite(GE)[16]执行通道重新加权,而BAM [30]和CBAM [44]独立地重新加权通道和空间位置。与这些方法相反,我们1)使用可以共同参与空间和特征子空间的注意机制(每个头对应于特征子空间)和2)引入额外的特征映射而不是精炼它们。 图2总结了我们提出的增强卷积。
在我们所有的实验中,增强卷积之后是批量标准化层[20],它可以学习缩放卷积特征图和注意特征图的贡献。
我们应用每个residual block一次的增强卷积,类似于其他视觉注意机制[17,16,30,44],并在整个架构中应用内存允许(更多细节见第4节)。
为了减少增强网络的内存占用量,我们通常采用较小的批量大小,有时还需要在应用它的最大空间维度的层中自我注意输入。通过应用3x3平均池化与步幅 2进行下采样,同时通过双线性插值获得以下上采样(concatenation所需)。
