这篇博文主要是延续前文系列的总结记录,这里主要是总结汇总日常主流的图像识别模型相关知识内容。
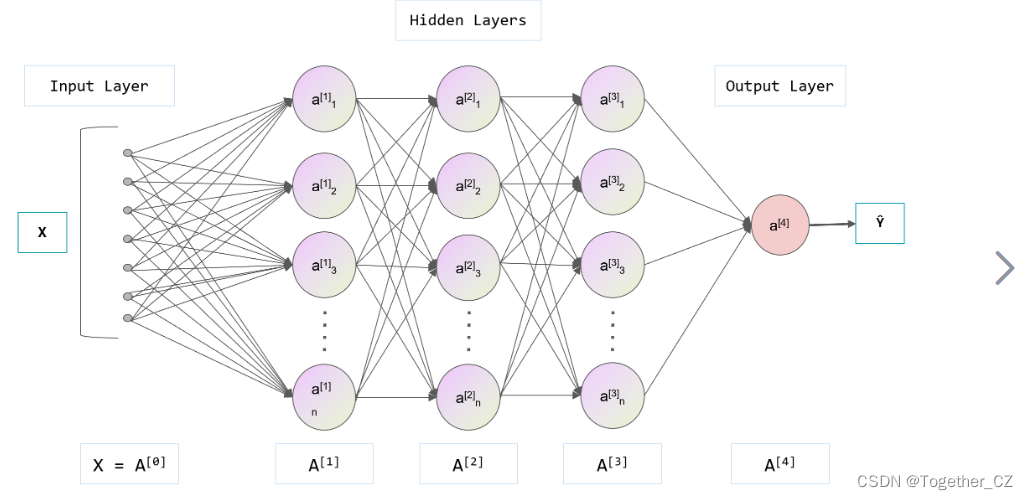
下面对上述列出的卷积神经网络模型进行逐个详细介绍、算法原理分析以及优缺点总结:
(1)LeNet-5
算法原理:
LeNet-5是最早应用于手写数字识别的卷积神经网络。它由两个卷积层、池化层和三个全连接层构成。每个卷积层后面跟着一个池化层,最后通过全连接层进行分类。
优点:
简单且易于理解,为后来的深度学习奠定了基础。
缺点:
较浅且参数量相对较小,可能在处理更复杂的任务时表现不佳。
Demo代码实现如下所示:
import tensorflow as tf
from tensorflow.keras import layers, models
# 定义LeNet网络模型
def LeNet():
model = models.Sequential()
# 第一层卷积层
model.add(layers.Conv2D(6, kernel_size=(5, 5), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
# 第二层卷积层
model.add(layers.Conv2D(16, kernel_size=(5, 5), activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
# 全连接层
model.add(layers.Flatten())
model.add(layers.Dense(120, activation='relu'))
model.add(layers.Dense(84, activation='relu'))
# 输出层
model.add(layers.Dense(10, activation='softmax'))
return model
# 加载MNIST数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = x_train.reshape(-1, 28, 28, 1) / 255.0
x_test = x_test.reshape(-1, 28, 28, 1) / 255.0
y_train = tf.keras.utils.to_categorical(y_train, num_classes=10)
y_test = tf.keras.utils.to_categorical(y_test, num_classes=10)
# 构建LeNet模型
model = LeNet()
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, batch_size=128, epochs=10, verbose=1)
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', test_loss)
print('Test accuracy:', test_acc)
(2)AlexNet
算法原理:
AlexNet是2012年ImageNet挑战赛冠军的模型。它由8个卷积层和3个全连接层组成,并引入了ReLU激活函数和Dropout正则化技术。
优点:
引入ReLU函数提高了非线性建模能力,Dropout可以减少过拟合问题。
缺点:
模型相对较大,需要较多的计算资源和训练时间。
Demo代码实现如下所示:
import tensorflow as tf
from tensorflow.keras import layers, models
# 定义AlexNet网络模型
def AlexNet():
model = models.Sequential()
# 第一层卷积层
model.add(layers.Conv2D(96, kernel_size=(3, 3), strides=(1, 1), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 第二层卷积层
model.add(layers.Conv2D(256, kernel_size=(5, 5), strides=(1, 1), activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 第三层卷积层
model.add(layers.Conv2D(384, kernel_size=(3, 3), strides=(1, 1), activation='relu'))
# 第四层卷积层
model.add(layers.Conv2D(384, kernel_size=(3, 3), strides=(1, 1), activation='relu'))
# 第五层卷积层
model.add(layers.Conv2D(256, kernel_size=(3, 3), strides=(1, 1), activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 全连接层
model.add(layers.Flatten())
model.add(layers.Dense(4096, activation='relu'))
model.add(layers.Dense(4096, activation='relu'))
# 输出层
model.add(layers.Dense(10, activation='softmax'))
return model
# 加载MNIST数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = x_train.reshape(-1, 28, 28, 1) / 255.0
x_test = x_test.reshape(-1, 28, 28, 1) / 255.0
y_train = tf.keras.utils.to_categorical(y_train, num_classes=10)
y_test = tf.keras.utils.to_categorical(y_test, num_classes=10)
# 构建AlexNet模型
model = AlexNet()
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, batch_size=128, epochs=10, verbose=1)
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', test_loss)
print('Test accuracy:', test_acc)
(3)VGG
算法原理:
VGGNet由牛津大学的VGG组提出。它采用了小尺寸的卷积核和堆叠的卷积层来构建深层网络。VGGNet有16或19个卷积层。
优点:
简单统一的结构,易于复现和理解,表现出色。
缺点:
参数量较大,训练和推断时间较长。
Demo代码实现如下所示:
import tensorflow as tf
from tensorflow.keras import layers, models
# 定义VGG16网络模型
def VGG16():
model = models.Sequential()
# 第一层卷积块
model.add(layers.Conv2D(64, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu', input_shape=(28, 28, 1)))
model.add(layers.Conv2D(64, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 第二层卷积块
model.add(layers.Conv2D(128, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.Conv2D(128, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 第三层卷积块
model.add(layers.Conv2D(256, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.Conv2D(256, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.Conv2D(256, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 第四层卷积块
model.add(layers.Conv2D(512, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.Conv2D(512, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.Conv2D(512, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 第五层卷积块
model.add(layers.Conv2D(512, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.Conv2D(512, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.Conv2D(512, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 全连接层
model.add(layers.Flatten())
model.add(layers.Dense(4096, activation='relu'))
model.add(layers.Dense(4096, activation='relu'))
# 输出层
model.add(layers.Dense(10, activation='softmax'))
return model
# 定义VGG19网络模型
def VGG19():
model = models.Sequential()
# 第一层卷积块
model.add(layers.Conv2D(64, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu', input_shape=(28, 28, 1)))
model.add(layers.Conv2D(64, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 第二层卷积块
model.add(layers.Conv2D(128, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.Conv2D(128, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 第三层卷积块
model.add(layers.Conv2D(256, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.Conv2D(256, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.Conv2D(256, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.Conv2D(256, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 第四层卷积块
model.add(layers.Conv2D(512, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.Conv2D(512, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.Conv2D(512, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.Conv2D(512, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 第五层卷积块
model.add(layers.Conv2D(512, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.Conv2D(512, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.Conv2D(512, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.Conv2D(512, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 全连接层
model.add(layers.Flatten())
model.add(layers.Dense(4096, activation='relu'))
model.add(layers.Dense(4096, activation='relu'))
# 输出层
model.add(layers.Dense(10, activation='softmax'))
return model
# 加载MNIST数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = x_train.reshape(-1, 28, 28, 1) / 255.0
x_test = x_test.reshape(-1, 28, 28, 1) / 255.0
y_train = tf.keras.utils.to_categorical(y_train, num_classes=10)
y_test = tf.keras.utils.to_categorical(y_test, num_classes=10)
# 构建VGG16模型
model = VGG16()
model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])
#训练模型
model.fit(x_train, y_train, batch_size=128, epochs=10, verbose=1)
#评估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', test_loss)
print('Test accuracy:', test_acc)
(4)ResNet
算法原理:
ResNet由MicrosoftResearch提出,通过引入残差连接解决了深层网络的梯度消失问题。它具有非常深的结构,从ResNet-18到ResNet-152等多个变体。
优点:
深层网络能够更好地捕捉图像特征,残差连接有助于模型训练和收敛。
缺点:
模型更深复杂,可能需要更多的计算资源。
Demo代码实现如下所示:
import tensorflow as tf
from tensorflow.keras import layers, models
# 定义ResNet网络模型
def ResNet():
input_tensor = layers.Input(shape=(28, 28, 1))
# 第一层
x = layers.Conv2D(64, (3, 3), padding='same', activation='relu')(input_tensor)
x = layers.BatchNormalization()(x)
# 4个残差块
for _ in range(4):
residual = x
x = layers.Conv2D(64, (3, 3), padding='same', activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.Conv2D(64, (3, 3), padding='same')(x)
x = layers.BatchNormalization()(x)
x = layers.add([x, residual])
x = layers.Activation('relu')(x)
# 全局平均池化层
x = layers.GlobalAveragePooling2D()(x)
# 输出层
output_tensor = layers.Dense(10, activation='softmax')(x)
model = models.Model(inputs=input_tensor, outputs=output_tensor)
return model
# 加载MNIST数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = x_train.reshape(-1, 28, 28, 1) / 255.0
x_test = x_test.reshape(-1, 28, 28, 1) / 255.0
y_train = tf.keras.utils.to_categorical(y_train, num_classes=10)
y_test = tf.keras.utils.to_categorical(y_test, num_classes=10)
# 构建ResNet模型
model = ResNet()
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, batch_size=128, epochs=10, verbose=1)
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', test_loss)
print('Test accuracy:', test_acc)
(5)DenseNet
算法原理:
DenseNet提出了密集连接(Dense Connection)的概念,在每个层中将前面所有层的特征图连接到当前层。这种连接方式使得每个层都可以直接获得之前层的特征信息。
优点:
密集连接有利于信息的流动和梯度传播,减轻了梯度消失问题;参数共享有助于减少模型参数量。
缺点:
参数量相对较大,训练时间较长。
Demo代码实现如下所示:
import tensorflow as tf
from tensorflow.keras import layers, models
# 定义DenseNet网络模型
def DenseNet():
input_tensor = layers.Input(shape=(28, 28, 1))
# 首先进行一个普通的卷积层
x = layers.Conv2D(64, (7, 7), padding='same', activation='relu')(input_tensor)
x = layers.MaxPooling2D(pool_size=(3, 3), strides=(2, 2), padding='same')(x)
# 定义Dense Block(结合多个卷积层)
def dense_block(x, blocks):
for _ in range(blocks):
residual = x
x = layers.BatchNormalization()(x)
x = layers.Activation('relu')(x)
x = layers.Conv2D(32, (3, 3), padding='same')(x)
x = layers.concatenate([x, residual])
return x
# 第一个Dense Block
x = dense_block(x, blocks=6)
# 进行过渡层(减少特征图的尺寸)
x = layers.BatchNormalization()(x)
x = layers.Activation('relu')(x)
x = layers.Conv2D(64, (1, 1), padding='same')(x)
x = layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2))(x)
# 第二个Dense Block
x = dense_block(x, blocks=12)
# 进行过渡层
x = layers.BatchNormalization()(x)
x = layers.Activation('relu')(x)
x = layers.Conv2D(128, (1, 1), padding='same')(x)
x = layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2))(x)
# 第三个Dense Block
x = dense_block(x, blocks=24)
# 进行过渡层
x = layers.BatchNormalization()(x)
x = layers.Activation('relu')(x)
x = layers.Conv2D(256, (1, 1), padding='same')(x)
x = layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2))(x)
# 第四个Dense Block
x = dense_block(x, blocks=16)
# 全局平均池化层
x = layers.BatchNormalization()(x)
x = layers.Activation('relu')(x)
x = layers.GlobalAveragePooling2D()(x)
# 输出层
output_tensor = layers.Dense(10, activation='softmax')(x)
model = models.Model(inputs=input_tensor, outputs=output_tensor)
return model
# 加载MNIST数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = x_train.reshape(-1, 28, 28, 1) / 255.0
x_test = x_test.reshape(-1, 28, 28, 1) / 255.0
y_train = tf.keras.utils.to_categorical(y_train, num_classes=10)
y_test = tf.keras.utils.to_categorical(y_test, num_classes=10)
# 构建DenseNet模型
model = DenseNet()
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, batch_size=128, epochs=10, verbose=1)
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', test_loss)
print('Test accuracy:', test_acc)
(6)MobileNetv1
算法原理:
MobileNetv1使用深度可分离卷积(Depthwise Separable Convolution)来减少计算量。它将标准的卷积分解为逐通道的深度卷积和1×1的逐点卷积。
优点:
参数量大幅减少,速度更快,适合于移动设备等资源受限的场景。
缺点:
准确性相对较低,适用于对速度要求较高而不需要极高准确性的任务。
Demo代码实现如下所示:
import tensorflow as tf
from tensorflow.keras import layers, models
# 定义MobileNetv1网络模型
def MobileNetv1():
input_tensor = layers.Input(shape=(28, 28, 1))
x = layers.Conv2D(32, (3, 3), strides=(2, 2), padding='same', activation='relu')(input_tensor)
x = layers.BatchNormalization()(x)
x = layers.DepthwiseConv2D((3, 3), padding='same', activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.Conv2D(64, (1, 1), padding='same', activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.DepthwiseConv2D((3, 3), strides=(2, 2), padding='same', activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.Conv2D(128, (1, 1), padding='same', activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.DepthwiseConv2D((3, 3), padding='same', activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.Conv2D(128, (1, 1), padding='same', activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.DepthwiseConv2D((3, 3), strides=(2, 2), padding='same', activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.Conv2D(256, (1, 1), padding='same', activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.DepthwiseConv2D((3, 3), padding='same', activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.Conv2D(256, (1, 1), padding='same', activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.GlobalAveragePooling2D()(x)
output_tensor = layers.Dense(10, activation='softmax')(x)
model = models.Model(inputs=input_tensor, outputs=output_tensor)
return model
# 加载MNIST数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = x_train.reshape(-1, 28, 28, 1) / 255.0
x_test = x_test.reshape(-1, 28, 28, 1) / 255.0
y_train = tf.keras.utils.to_categorical(y_train, num_classes=10)
y_test = tf.keras.utils.to_categorical(y_test, num_classes=10)
# 构建MobileNetv1模型
model = MobileNetv1()
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, batch_size=128, epochs=10, verbose=1)
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', test_loss)
print('Test accuracy:', test_acc)
(7)MobileNetv2
算法原理:
MobileNetv2在MobileNetv1的基础上进行了改进,引入了倒残差结构和线性瓶颈。倒残差结构允许网络在低维度上进行特征变换,并通过线性瓶颈减少计算量。
优点:
进一步减少了参数量和计算量,相较于MobileNetv1有更好的速度和准确性平衡。
缺点:
准确性仍然相对较低,相比于其他模型可能在某些任务上表现不佳。
Demo代码实现如下所示:
import tensorflow as tf
from tensorflow.keras import layers, models
# 定义MobileNetv2网络模型
def MobileNetv2():
input_tensor = layers.Input(shape=(28, 28, 1))
x = layers.Conv2D(32, (3, 3), strides=(2, 2), padding='same', activation='relu')(input_tensor)
x = layers.BatchNormalization()(x)
x = inverted_residual_block(x, 16, (3, 3), t=1, strides=1, n=1)
x = inverted_residual_block(x, 24, (3, 3), t=6, strides=2, n=2)
x = inverted_residual_block(x, 32, (3, 3), t=6, strides=2, n=3)
x = inverted_residual_block(x, 64, (3, 3), t=6, strides=2, n=4)
x = inverted_residual_block(x, 96, (3, 3), t=6, strides=1, n=3)
x = inverted_residual_block(x, 160, (3, 3), t=6, strides=2, n=3)
x = inverted_residual_block(x, 320, (3, 3), t=6, strides=1, n=1)
x = layers.Conv2D(1280, (1, 1), padding='same', activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.GlobalAveragePooling2D()(x)
output_tensor = layers.Dense(10, activation='softmax')(x)
model = models.Model(inputs=input_tensor, outputs=output_tensor)
return model
# 定义inverted residual block
def inverted_residual_block(x, filters, kernel_size, t, strides, n):
for i in range(n):
if i == 0:
# 第一个卷积层需要使用扩展因子t
residual = x
x = layers.Conv2D(filters * t, (1, 1), padding='same', activation='relu')(x)
x = layers.DepthwiseConv2D(kernel_size, strides=strides, padding='same', activation='relu')(x)
x = layers.Conv2D(filters, (1, 1), padding='same')(x)
x = layers.BatchNormalization()(x)
x = layers.add([x, residual])
else:
residual = x
x = layers.Conv2D(filters, (1, 1), padding='same', activation='relu')(x)
x = layers.DepthwiseConv2D(kernel_size, strides=1, padding='same', activation='relu')(x)
x = layers.Conv2D(filters, (1, 1), padding='same')(x)
x = layers.BatchNormalization()(x)
x = layers.add([x, residual])
return x
# 加载MNIST数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = x_train.reshape(-1, 28, 28, 1) / 255.0
x_test = x_test.reshape(-1, 28, 28, 1) / 255.0
y_train = tf.keras.utils.to_categorical(y_train, num_classes=10)
y_test = tf.keras.utils.to_categorical(y_test, num_classes=10)
# 构建MobileNetv2模型
model = MobileNetv2()
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, batch_size=128, epochs=10, verbose=1)
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', test_loss)
print('Test accuracy:', test_acc)
(8)MobileNetv3
算法原理:
MobileNetv3是MobileNet系列中的最新版本,采用了多种技术改进。它引入了自适应宽度和激活函数选择机制,并通过轻量化卷积块和全局平均池化提高了效率。
优点:
进一步提升了速度和准确性的平衡,具有更高的参数效率和推断速度。
缺点:
相较于一些复杂模型,准确性可能仍然有所牺牲。
Demo代码实现如下所示:
import tensorflow as tf
from tensorflow.keras import layers, models
# 定义MobileNetv3网络模型
def MobileNetv3():
input_tensor = layers.Input(shape=(28, 28, 1))
x = layers.Conv2D(16, (3, 3), strides=(2, 2), padding='same', activation='relu')(input_tensor)
x = layers.BatchNormalization()(x)
x = inverted_residual_block(x, 16, (3, 3), expand_ratio=1, strides=1, se_ratio=0.25)
x = inverted_residual_block(x, 24, (3, 3), expand_ratio=4, strides=2, se_ratio=0.25)
x = inverted_residual_block(x, 40, (3, 3), expand_ratio=4, strides=2, se_ratio=0.25)
x = inverted_residual_block(x, 80, (3, 3), expand_ratio=4, strides=2, se_ratio=0.25)
x = layers.Conv2D(320, (1, 1), padding='same', activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.GlobalAveragePooling2D()(x)
output_tensor = layers.Dense(10, activation='softmax')(x)
model = models.Model(inputs=input_tensor, outputs=output_tensor)
return model
# 定义inverted residual block
def inverted_residual_block(x, filters, kernel_size, expand_ratio, strides, se_ratio):
input_tensor = x
input_channels = x.shape[-1]
# expansion phase
if expand_ratio != 1:
expanded_channels = input_channels * expand_ratio
x = layers.Conv2D(expanded_channels, (1, 1), padding='same', activation='relu')(x)
x = layers.BatchNormalization()(x)
# depthwise convolution
x = layers.DepthwiseConv2D(kernel_size, strides=strides, padding='same', activation='relu')(x)
x = layers.BatchNormalization()(x)
# squeeze and excitation phase
num_squeeze_filters = max(1, int(input_channels * se_ratio))
x_squeeze = layers.GlobalAveragePooling2D()(x)
x_squeeze = layers.Reshape((1, 1, input_channels))(x_squeeze)
x_squeeze = layers.Conv2D(num_squeeze_filters, (1, 1), activation='relu')(x_squeeze)
x_squeeze = layers.Conv2D(expanded_channels, (1, 1), activation='sigmoid')(x_squeeze)
x_se = layers.multiply([x, x_squeeze])
# projection phase
x = layers.Conv2D(filters, (1, 1), padding='same')(x_se)
x = layers.BatchNormalization()(x)
# residual connection
if strides == 1 and input_channels == filters:
x = layers.add([x, input_tensor])
return x
# 加载MNIST数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = x_train.reshape(-1, 28, 28, 1) / 255.0
x_test = x_test.reshape(-1, 28, 28, 1) / 255.0
y_train = tf.keras.utils.to_categorical(y_train, num_classes=10)
y_test = tf.keras.utils.to_categorical(y_test, num_classes=10)
# 构建MobileNetv3模型
model = MobileNetv3()
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, batch_size=128, epochs=10, verbose=1)
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', test_loss)
print('Test accuracy:', test_acc)
(9)GoogleNet/Inception
算法原理:
GoogleNet(也称为Inception-v1)采用了多个尺度的卷积核并行进行特征提取。它通过Inception模块将不同尺度的卷积结果进行串联,以获得丰富的特征表达。
优点:
多尺度卷积和并行结构有助于提高特征提取能力和模型性能。
缺点:
参数量较大,网络较深,可能需要更多计算资源。
Demo代码实现如下所示:
import tensorflow as tf
from tensorflow.keras import layers, models
# 定义GoogleNet网络模型
def GoogleNet():
input_tensor = layers.Input(shape=(28, 28, 1))
# 第一个Inception模块
x = inception_module(input_tensor, filters=[64, 96, 128, 16, 32, 32])
# 第二个Inception模块
x = inception_module(x, filters=[128, 128, 192, 32, 96, 64])
x = layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2))(x)
# 第三个Inception模块
x = inception_module(x, filters=[192, 96, 208, 16, 48, 64])
# 第四个Inception模块
x = inception_module(x, filters=[160, 112, 224, 24, 64, 64])
# 第五个Inception模块
x = inception_module(x, filters=[128, 128, 256, 24, 64, 64])
# 第六个Inception模块
x = inception_module(x, filters=[112, 144, 288, 32, 64, 64])
# 第七个Inception模块
x = inception_module(x, filters=[256, 160, 320, 32, 128, 128])
x = layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2))(x)
# 第八个Inception模块
x = inception_module(x, filters=[256, 160, 320, 32, 128, 128])
# 第九个Inception模块
x = inception_module(x, filters=[384, 192, 384, 48, 128, 128])
x = layers.GlobalAveragePooling2D()(x)
output_tensor = layers.Dense(10, activation='softmax')(x)
model = models.Model(inputs=input_tensor, outputs=output_tensor)
return model
# 定义Inception模块
def inception_module(x, filters):
branch1x1 = layers.Conv2D(filters[0], (1, 1), padding='same', activation='relu')(x)
branch3x3 = layers.Conv2D(filters[1], (1, 1), padding='same', activation='relu')(x)
branch3x3 = layers.Conv2D(filters[2], (3, 3), padding='same', activation='relu')(branch3x3)
branch5x5 = layers.Conv2D(filters[3], (1, 1), padding='same', activation='relu')(x)
branch5x5 = layers.Conv2D(filters[4], (5, 5), padding='same', activation='relu')(branch5x5)
branch_pool = layers.MaxPooling2D(pool_size=(3, 3), strides=(1, 1), padding='same')(x)
branch_pool = layers.Conv2D(filters[5], (1, 1), padding='same', activation='relu')(branch_pool)
output = layers.concatenate([branch1x1, branch3x3, branch5x5, branch_pool], axis=-1)
return output
# 加载MNIST数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = x_train.reshape(-1, 28, 28, 1) / 255.0
x_test = x_test.reshape(-1, 28, 28, 1) / 255.0
y_train = tf.keras.utils.to_categorical(y_train, num_classes=10)
y_test = tf.keras.utils.to_categorical(y_test, num_classes=10)
# 构建GoogleNet模型
model = GoogleNet()
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, batch_size=128, epochs=10, verbose=1)
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', test_loss)
print('Test accuracy:', test_acc)(10)ZFNet
算法原理:
ZFNet是在AlexNet的基础上进行改进的模型,主要调整了卷积核大小和网络结构。它采用更小的卷积核,并增加了一些卷积和全连接层。
优点:
具有较好的图像分类性能,能够更好地捕捉图像特征。
缺点:
模型较大,训练时间相对较长。
Demo代码实现如下所示:
import tensorflow as tf
from tensorflow.keras import layers, models
# 定义ZFNet网络模型
def ZFNet():
input_tensor = layers.Input(shape=(28, 28, 1))
x = layers.Conv2D(96, (7, 7), strides=(2, 2), padding='same', activation='relu')(input_tensor)
x = layers.MaxPooling2D(pool_size=(3, 3), strides=(2, 2))(x)
x = layers.BatchNormalization()(x)
x = layers.Conv2D(256, (5, 5), strides=(2, 2), padding='same', activation='relu')(x)
x = layers.MaxPooling2D(pool_size=(3, 3), strides=(2, 2))(x)
x = layers.BatchNormalization()(x)
x = layers.Conv2D(384, (3, 3), strides=(1, 1), padding='same', activation='relu')(x)
x = layers.Conv2D(384, (3, 3), strides=(1, 1), padding='same', activation='relu')(x)
x = layers.Conv2D(256, (3, 3), strides=(1, 1), padding='same', activation='relu')(x)
x = layers.Flatten()(x)
x = layers.Dense(4096, activation='relu')(x)
x = layers.Dropout(0.5)(x)
x = layers.Dense(4096, activation='relu')(x)
x = layers.Dropout(0.5)(x)
output_tensor = layers.Dense(10, activation='softmax')(x)
model = models.Model(inputs=input_tensor, outputs=output_tensor)
return model
# 加载MNIST数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = x_train.reshape(-1, 28, 28, 1) / 255.0
x_test = x_test.reshape(-1, 28, 28, 1) / 255.0
y_train = tf.keras.utils.to_categorical(y_train, num_classes=10)
y_test = tf.keras.utils.to_categorical(y_test, num_classes=10)
# 构建ZFNet模型
model = ZFNet()
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, batch_size=128, epochs=10, verbose=1)
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', test_loss)
print('Test accuracy:', test_acc)
(11)Inceptionv2
算法原理:
Inceptionv2采用了各种改进措施来优化Inception-v1的结构。主要的改进包括:
加入BN(Batch Normalization)层:在每个卷积操作后加入BN层,通过对输入数据进行归一化处理,有助于加速网络收敛并减少过拟合。使用1×1卷积降低计算量:引入1×1卷积核,用于减少通道数。这样可以降低模型中的计算量和参数数量,同时保持良好的特征表达能力。使用瓶颈结构(Bottleneck Structure):为了减少模型中的计算负荷,Inceptionv2使用瓶颈结构,即先使用1×1卷积核进行降维,然后再应用3×3或5×5的卷积操作,最后再使用1×1卷积核进行升维。使用多尺度卷积:引入了多个不同尺度的卷积核,并将它们在同一层进行并行操作。这样可以提高网络的特征提取能力,从而更好地捕捉图像中的多尺度特征。
优点:
改进的结构使得Inceptionv2在计算效率上有所提升。通过加入BN层、使用1×1卷积核和瓶颈结构,减少了模型中的计算量和参数数量,提高了整体的效率。
多尺度卷积和并行操作有助于提高特征提取能力,并能够更好地捕捉图像中的多尺度信息。
加入BN层可以加速网络收敛过程,并且有助于缓解梯度消失问题,提高模型的训练稳定性。
Inceptionv2依然具有较高的准确性,在图像分类等任务上表现出色。
缺点:
相比于Inception-v1,Inceptionv2的网络结构更为复杂,导致模型的计算资源需求增加,可能需要更多的计算资源和训练时间。
在一些资源受限的环境下,Inceptionv2的复杂结构可能不太适合部署。
综上所述,Inceptionv2通过加入BN层、使用1×1卷积核和瓶颈结构等改进,提高了计算效率和特征提取能力,同时保持了较高的准确性。然而,由于其复杂的网络结构,可能需要更多的计算资源来训练和使用。因此,在选择模型时需要综合考虑任务需求、计算资源和性能要求。
Demo代码实现如下所示:
import tensorflow as tf
from tensorflow.keras import layers, models
# 定义Inceptionv2网络模型
def Inceptionv2():
input_tensor = layers.Input(shape=(28, 28, 1))
# 第一个Inception模块
x = inception_module(input_tensor, filters=[64, 96, 128, 16, 32, 32])
# 第二个Inception模块
x = inception_module(x, filters=[128, 128, 192, 32, 96, 64])
x = layers.MaxPooling2D(pool_size=(3, 3), strides=(2, 2))(x)
# 第三个Inception模块
x = inception_module(x, filters=[192, 96, 208, 16, 48, 64])
# 第四个Inception模块
x = inception_module(x, filters=[160, 112, 224, 24, 64, 64])
# 第五个Inception模块
x = inception_module(x, filters=[128, 128, 256, 24, 64, 64])
# 第六个Inception模块
x = inception_module(x, filters=[112, 144, 288, 32, 64, 64])
# 第七个Inception模块
x = inception_module(x, filters=[256, 160, 320, 32, 128, 128])
x = layers.MaxPooling2D(pool_size=(3, 3), strides=(2, 2))(x)
# 第八个Inception模块
x = inception_module(x, filters=[256, 160, 320, 32, 128, 128])
# 第九个Inception模块
x = inception_module(x, filters=[384, 192, 384, 48, 128, 128])
x = layers.GlobalAveragePooling2D()(x)
output_tensor = layers.Dense(10, activation='softmax')(x)
model = models.Model(inputs=input_tensor, outputs=output_tensor)
return model
# 定义Inception模块
def inception_module(x, filters):
branch1x1 = layers.Conv2D(filters[0], (1, 1), padding='same', activation='relu')(x)
branch3x3 = layers.Conv2D(filters[1], (1, 1), padding='same', activation='relu')(x)
branch3x3 = layers.Conv2D(filters[2], (3, 3), padding='same', activation='relu')(branch3x3)
branch5x5 = layers.Conv2D(filters[3], (1, 1), padding='same', activation='relu')(x)
branch5x5 = layers.Conv2D(filters[4], (5, 5), padding='same', activation='relu')(branch5x5)
branch_pool = layers.MaxPooling2D(pool_size=(3, 3), strides=(1, 1), padding='same')(x)
branch_pool = layers.Conv2D(filters[5], (1, 1), padding='same', activation='relu')(branch_pool)
output = layers.concatenate([branch1x1, branch3x3, branch5x5, branch_pool], axis=-1)
return output
# 加载MNIST数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = x_train.reshape(-1, 28, 28, 1) / 255.0
x_test = x_test.reshape(-1, 28, 28, 1) / 255.0
y_train = tf.keras.utils.to_categorical(y_train, num_classes=10)
y_test = tf.keras.utils.to_categorical(y_test, num_classes=10)
# 构建Inceptionv2模型
model = Inceptionv2()
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, batch_size=128, epochs=10, verbose=1)
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', test_loss)
print('Test accuracy:', test_acc)
(12)Inceptionv3
算法原理:
Inceptionv3在Inceptionv2的基础上引入了多种改进措施,主要包括:
加入辅助分类器:在中间层添加了辅助分类器,用于在训练过程中引入额外的监督信号,有助于网络收敛和减轻梯度消失问题。
使用更小的卷积核:通过使用更小的3×3卷积核替代原先的5×5卷积核,减少了计算量和参数数量。分解卷积操作:将大尺寸卷积分解为连续的两个3×3卷积操作,以增加非线性建模能力。
全局平均池化:在最后的特征图上采用全局平均池化来降低特征图的空间维度,减少了参数数量。
引入批量归一化(Batch Normalization):在网络中各个卷积层后都加入了批量归一化操作,加速网络收敛并减少过拟合。
优点:
Inceptionv3在准确性上有所提升。通过使用更小的卷积核、分解卷积操作和引入全局平均池化,增加了非线性建模能力,并降低了特征图的维度,从而提高了分类性能。
引入辅助分类器有助于网络收敛,通过额外的监督信号可以减轻梯度消失问题,提高模型的训练稳定性。
使用批量归一化操作可以加速网络收敛,并且有助于缓解过拟合问题。
Inceptionv3相比于之前的版本仍然具有较高的计算效率,同时在保持性能的同时减少了参数量。
缺点:
Inceptionv3的网络结构相对复杂,可能需要更多的计算资源和训练时间来训练和使用。
在一些资源受限的情况下,Inceptionv3可能不太适合部署在计算能力较弱的设备上。
Demo代码实现如下所示:
import tensorflow as tf
from tensorflow.keras import layers, models
# 定义Inceptionv3网络模型
def Inceptionv3():
input_tensor = layers.Input(shape=(28, 28, 1))
x = layers.Conv2D(32, (3, 3), strides=(2, 2), padding='valid', activation='relu')(input_tensor)
x = layers.BatchNormalization()(x)
x = layers.Conv2D(32, (3, 3), strides=(1, 1), padding='valid', activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.Conv2D(64, (3, 3), strides=(1, 1), padding='same', activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.MaxPooling2D(pool_size=(3, 3), strides=(2, 2))(x)
x = layers.Conv2D(80, (1, 1), strides=(1, 1), padding='valid', activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.Conv2D(192, (3, 3), strides=(1, 1), padding='valid', activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.MaxPooling2D(pool_size=(3, 3), strides=(2, 2))(x)
# Inception模块
x = inception_module(x, [64, 96, 128, 16, 32, 32])
x = inception_module(x, [128, 128, 192, 32, 96, 64])
x = layers.MaxPooling2D(pool_size=(3, 3), strides=(2, 2))(x)
# Inception模块
x = inception_module(x, [192, 96, 208, 16, 48, 64])
x = inception_module(x, [160, 112, 224, 24, 64, 64])
x = inception_module(x, [128, 128, 256, 24, 64, 64])
x = inception_module(x, [112, 144, 288, 32, 64, 64])
x = inception_module(x, [256, 160, 320, 32, 128, 128])
x = layers.MaxPooling2D(pool_size=(3, 3), strides=(2, 2))(x)
# Inception模块
x = inception_module(x, [256, 160, 320, 32, 128, 128])
x = inception_module(x, [384, 192, 384, 48, 128, 128])
x = layers.GlobalAveragePooling2D()(x)
output_tensor = layers.Dense(10, activation='softmax')(x)
model = models.Model(inputs=input_tensor, outputs=output_tensor)
return model
# 定义Inception模块
def inception_module(x, filters):
branch1x1 = layers.Conv2D(filters[0], (1, 1), strides=(1, 1), padding='same', activation='relu')(x)
branch3x3 = layers.Conv2D(filters[1], (1, 1), strides=(1, 1), padding='same', activation='relu')(x)
branch3x3 = layers.Conv2D(filters[2], (3, 3), strides=(1, 1), padding='same', activation='relu')(branch3x3)
branch5x5 = layers.Conv2D(filters[3], (1, 1), strides=(1, 1), padding='same', activation='relu')(x)
branch5x5 = layers.Conv2D(filters[4], (5, 5), strides=(1, 1), padding='same', activation='relu')(branch5x5)
branch_pool = layers.MaxPooling2D(pool_size=(3, 3), strides=(1, 1), padding='same')(x)
branch_pool =layers.Conv2D(filters[5], (1, 1), strides=(1, 1), padding='same', activation='relu')(branch_pool)
output = layers.concatenate([branch1x1, branch3x3, branch5x5, branch_pool], axis=-1)
return output
# 加载MNIST数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = x_train.reshape(-1, 28, 28, 1) / 255.0
x_test = x_test.reshape(-1, 28, 28, 1) / 255.0
y_train = tf.keras.utils.to_categorical(y_train, num_classes=10)
y_test = tf.keras.utils.to_categorical(y_test, num_classes=10)
# 构建Inceptionv3模型
model = Inceptionv3()
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, batch_size=128, epochs=10, verbose=1)
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', test_loss)
print('Test accuracy:', test_acc)
(13)Xception
Xception(Extreme Inception)是一种卷积神经网络模型,它是Google在2016年提出的,由于其卓越的性能和创新的架构而引起了广泛关注。Xception模型基于Inception架构的思想,并进行了进一步的改进,主要用于图像分类和目标检测任务。
算法原理:
Xception的算法原理可以分为两个部分:深度可分离卷积和Inception模块。
深度可分离卷积:
Xception中采用了一种被称为深度可分离卷积的新型卷积操作。传统卷积操作将通道间的特征信息和空间信息同时处理,导致计算量较大。而深度可分离卷积则将通道间的特征信息和空间信息分开处理,包括深度卷积和逐点卷积两个阶段。
深度卷积(Depthwise Convolution):对输入的每个通道独立应用卷积核,得到相同数量的特征图。这样实现了对通道间特征信息的处理。
逐点卷积(Pointwise Convolution):应用1x1卷积核对深度卷积阶段输出的特征图进行卷积操作,实现融合各通道的空间信息。
通过深度可分离卷积,Xception模型减少了计算量,并且更加高效地利用了特征信息。
Inception模块:
Xception模型基于Inception模块构建网络架构。Inception模块是一种多分支结构,通过在不同大小的卷积核上进行卷积操作,并将结果在通道维度上连接起来,从而捕捉多尺度的特征。
Xception模型使用了扩张卷积(Dilated Convolution)的思想,即在Inception模块中引入了空洞卷积(Atrous Convolution)。空洞卷积可以扩大感受野,进一步提取全局和局部的上下文信息,使网络更具代表性。
优点:
较低的参数量和计算复杂度:深度可分离卷积能够显著减少参数数量和计算量,提高模型的训练速度和推理速度。
更好的特征表示能力:通过深度可分离卷积和Inception模块的设计,Xception能够更好地捕捉图像中的特征信息,提高了模型的表达能力。
高准确率:在许多图像分类和目标检测任务中,Xception模型展现出了较高的准确率,超过了一些传统的模型。
更好的表达能力:Xception模型通过深度可分离卷积和Inception模块的组合方式,能够更好地捕捉图像中的局部和全局特征信息,提高了模型的表达能力。
缺点:
对训练数据量和计算资源的要求较高:由于Xception模型相对较深且复杂,需要更大规模的训练数据和较好的计算资源来训练,并且需要更长的时间才能收敛。
对输入图像分辨率的依赖:Xception模型中使用了小尺寸的卷积核,对于低分辨率图像可能存在信息损失,因此对输入图像的分辨率有一定要求。
Demo代码实现如下所示:
import numpy as np
from keras.layers import Input, Conv2D, SeparableConv2D, GlobalAveragePooling2D, Dense
from keras.models import Model
from keras.datasets import mnist
from keras.utils import to_categorical
# 加载MNIST数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = np.expand_dims(x_train, axis=-1).astype('float32') / 255.0
x_test = np.expand_dims(x_test, axis=-1).astype('float32') / 255.0
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# 构建Xception模型
input_shape = (28, 28, 1)
inputs = Input(shape=input_shape)
x = Conv2D(32, (3, 3), strides=(2, 2), padding='same', activation='relu')(inputs)
x = Conv2D(64, (3, 3), padding='same', activation='relu')(x)
residual = Conv2D(128, (1, 1), strides=(2, 2), padding='same')(x)
x = SeparableConv2D(128, (3, 3), padding='same', activation='relu')(x)
x = SeparableConv2D(128, (3, 3), padding='same', activation='relu')(x)
x = GlobalAveragePooling2D()(x)
x = Dense(128, activation='relu')(x)
x = Dense(10, activation='softmax')(x)
outputs = x + residual
model = Model(inputs=inputs, outputs=outputs)
model.summary()
# 编译和训练模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=64, epochs=10, validation_data=(x_test, y_test))
(14)CapsuleNet
胶囊网络(Capsule Network)是一种由Hinton等人在2017年提出的新型神经网络架构。它的设计灵感来自于对人类视觉系统中神经元工作原理的观察和理解。与传统的卷积神经网络(CNN)相比,胶囊网络更加注重实体的姿态和空间关系。
胶囊网络原理:
胶囊网络通过引入"胶囊"这个概念来替代传统神经元。胶囊是由向量组成的实体,其中包含了实体的属性信息,并且可以表示实体的姿态和空间关系。每个胶囊都学习如何检测一个特定的实体或特征,而不仅仅是简单地识别像素。
胶囊网络的核心组件是胶囊层(Capsule Layer)。在胶囊层中,每个胶囊通过动态路由算法进行通信,并且将信息传递给下一层的胶囊。动态路由算法允许胶囊之间根据其相关性分配权重,从而获得更准确的姿态和空间关系。
胶囊网络的输出是由一组胶囊表示的,每个胶囊代表一个不同的类别或实体。最终的分类结果通过计算胶囊之间的长度来确定,长度表示了实体存在的概率。
优点:
对姿态和空间关系敏感:胶囊网络可以捕捉到实体的姿态和空间关系,而不仅仅是像素级别的特征。这使得胶囊网络在处理具有变化姿态的物体或图像时更加有效和准确。
鲁棒性强:胶囊网络具有良好的鲁棒性,能够对输入数据的一定程度的变形和扭曲保持稳定的识别能力。这使得胶囊网络在处理噪声干扰或模糊图像时表现优秀。
可解释性强:胶囊网络的胶囊表示可以提供更具可解释性的结果。由于每个胶囊代表一个类别或实体,并且携带相关属性,因此可以更容易理解网络的判断依据。
缺点:
计算复杂度高:相较于传统的卷积神经网络,胶囊网络的计算复杂度更高,需要更多的计算资源和时间来训练和推断。
网络设计和调优难度大:胶囊网络的架构和参数设计相对复杂,需要更多的实践和调优来获得最佳性能。此外,缺乏大规模数据集和标签约束也是一个挑战。
虽然胶囊网络具有许多优点,但目前仍然存在一些技术和应用上的局限性。未来随着研究的进展,胶囊网络可能会越来越被广泛应用于不同领域的图像识别和分析任务中。
Demo代码实现如下所示:
import numpy as np
import tensorflow as tf
from keras import backend as K
from keras.layers import Conv2D, Dense, Flatten, Reshape, Layer, Input
from keras.models import Model
from keras.utils import to_categorical
from keras_contrib.layers import Capsule
# 定义胶囊网络模型
def CapsuleNet(input_shape, n_class):
x = Input(shape=input_shape)
# 第一层卷积
conv1 = Conv2D(filters=64, kernel_size=(3, 3), strides=(1, 1), padding='valid', activation='relu')(x)
# 第二层胶囊层
primary_caps = Capsule(n_capsule=8, dim_capsule=16, routings=3, kernel_size=(3, 3), strides=(1, 1))(conv1)
# 全连接层
digit_caps = Capsule(n_capsule=n_class, dim_capsule=16, routings=3)(primary_caps)
# 输出层
out_caps = Length()(digit_caps)
model = Model(inputs=x, outputs=out_caps)
return model
# 定义长度计算层
class Length(Layer):
def call(self, inputs, **kwargs):
return K.sqrt(K.sum(K.square(inputs), axis=-1))
def compute_output_shape(self, input_shape):
return input_shape[:-1]
# 加载MNIST数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = x_train.reshape(-1, 28, 28, 1) / 255.0
x_test = x_test.reshape(-1, 28, 28, 1) / 255.0
y_train = to_categorical(y_train, num_classes=10)
y_test = to_categorical(y_test, num_classes=10)
# 构建胶囊网络模型
model = CapsuleNet(input_shape=(28, 28, 1), n_class=10)
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, batch_size=128, epochs=10, verbose=1)
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', test_loss)
print('Test accuracy:', test_acc)