读论文Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank
原地址:https://blog.csdn.net/qq_31456593/article/details/89397144
本文介绍了递归神经张量网络。当在新的树库上进行训练时,该模型在几个指标上胜过所有先前的方法。 它将单句正/负分类的现有技术从80%提高到85.4%。 预测所有短语的细粒度情绪标签的准确率达到80.7%,比特征基线提高了9.7%。 最后,它是唯一能够准确捕捉否定的影响及其在各种树级别上对正面和负面短语的影响范围的模型。
斯坦福情感树库是第一个具有完全标记的解析树的语料库,可以对语言中的情感成分进行全面分析。
递归神经网络的张量采取任何长度的输入短语。 它们通过单词向量和解析树表示短语,然后使用相同的基于张量的合成函数计算树中较高节点的向量。
Recursive Neural Network模型使用与递归自动编码器(Socher等,2011b)和递归自动关联存储器(Pollack,1990)相同的组合性函数。 与前一个模型的唯一区别是我们修复树结构并忽略重建损失。 在最初的实验中,我们发现,随着额外的训练数据量,每个节点的构造损失不是获得高性能所必需的。
mv-rnn的一个问题是参数的数目变得非常大,并且取决于词汇表的大小。

与先前的RNN模型(等价与当V被设置为0时RNTN的特殊情况)相比的主要优点是张量可以直接关联输入向量。 直观地,我们可以将张量的每个切片解释为捕获特定类型的组合物
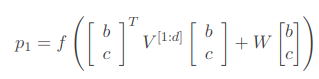
其中V∈ℝ2d×2d×d是一个三阶的张量(Tensor)。 xTVx的计算方式是把张量的每一个分片(张量的一个分片维度是ℝ2d×2d) V[i],i∈[1,2,…,d]对xx计算xTV[i]x,最后输出一个ℝd的向量。 然后加上一个W(1)x,然后通过一个非线性变换。通过二次变换实际上两个向量之间 进行了乘法类型的交互,而且不需要像MV-RNN一样对每个词保持一个矩阵,参数空间小了很多。
