机器学习实战2.3. k-近邻算法例子-识别手写数字
搜索微信公众号:‘AI-ming3526’或者’计算机视觉这件小事’ 获取更多机器学习干货
csdn:https://blog.csdn.net/baidu_31657889/
github:https://github.com/xiaoming3526/ai-ming3526
本文参考地址:[apachecn/AiLearning]
项目案例2: 识别手写数字
完整代码地址: https://github.com/xiaoming3526/ai-ming3526/blob/master/blog/src/py2.x/ml/2.KNN/KNN_demo02.py
1 实战背景
对于需要识别的数字已经使用图形处理软件,处理成具有相同的色彩和大小:宽高是32像素x32像素。尽管采用本文格式存储图像不能有效地利用内存空间,但是为了方便理解,我们将图片转换为文本格式,数字的文本格式如图所示。

与此同时,这些文本格式存储的数字的文件命名也很有特点,格式为:数字的值_该数字的样本序号,如图所示
对于这样已经整理好的文本,我们可以直接使用Python处理,进行数字预测。数据集分为训练集和测试集,使用上小结的方法,自己设计k-近邻算法分类器,可以实现分类。
2 开发流程
收集数据:提供文本文件。 准备数据:编写函数 img2vector(), 将图像格式转换为分类器使用的向量格式 数据下载见上面
分析数据:在Python 命令提示符中检查数据,确保它符合要求 训练算法:此步骤不适用于 KNN
测试算法:编写函数使用提供的部分数据集作为测试样本,测试样本与非测试样本的区别在于测试样本是已经完成分类的数据,如果预测分类与实际类别不同,则标记为一个错误
使用算法:本例没有完成此步骤,若你感兴趣可以构建完整的应用程序,从图像中提取数字,并完成数字识别,美国的邮件分拣系统就是一个实际运行的类似系统
准备数据: 编写函数 img2vector(), 将图像文本数据转换为分类器使用的向量
将图像文本数据转换为向量
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
分析数据:在 Python 命令提示符中检查数据,确保它符合要求
在 Python 命令行中输入下列命令测试 img2vector 函数,然后与文本编辑器打开的文件进行比较:
>>> testVector = kNN.img2vector('testDigits/0_13.txt')
>>> testVector[0,0:32]
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
>>> testVector[0,32:64]
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
训练算法:此步骤不适用于 KNN
因为测试数据每一次都要与全量的训练数据进行比较,所以这个过程是没有必要的。
测试算法:编写函数使用提供的部分数据集作为测试样本,如果预测分类与实际类别不同,则标记为一个错误
def handwritingClassTest():
# 1. 导入训练数据
hwLabels = []
trainingFileList = listdir('data/2.KNN/trainingDigits') # load the training set
m = len(trainingFileList)
trainingMat = zeros((m, 1024))
# hwLabels存储0~9对应的index位置, trainingMat存放的每个位置对应的图片向量
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] # take off .txt
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
# 将 32*32的矩阵->1*1024的矩阵
trainingMat[i, :] = img2vector('data/2.KNN/trainingDigits/%s' % fileNameStr)
# 2. 导入测试数据
testFileList = listdir('data/2.KNN/testDigits') # iterate through the test set
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0] # take off .txt
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('data/2.KNN/testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0
print "\nthe total number of errors is: %d" % errorCount
print "\nthe total error rate is: %f" % (errorCount / float(mTest))
使用算法:本例没有完成此步骤,若你感兴趣可以构建完整的应用程序,从图像中提取数字,并完成数字识别,美国的邮件分拣系统就是一个实际运行的类似系统。
结果展示
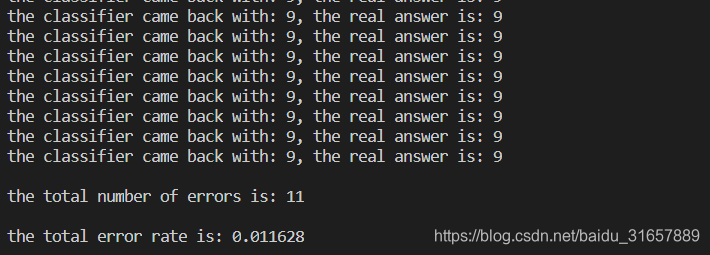
可以看出总共识别出错的个数为11
错误率:0.011628效果还是很不错的