数据源
我们的文本是形如这样的,每个数字都有很多txt文件,TXT里面是01数字,表示手写数字的灰度图。

现在我们要用knn算法实现数字识别。
数据处理
每个txt文件都是32*32的0,1矩阵,如果要使用knn,那么还得考虑行列关系,如果能把它拉开,只有一行,就可以不必考虑数字是第几行了,会更加方便。
#手写数字识别
#将32*32矩阵转化为1*1024
def img2vector(filename):
returnVect=zeros((1,1024)) #构建1*1024的0矩阵
fr=open(filename)#打开文件
for i in range(32):
lineStr=fr.readline() #读取第i行
for j in range(32):
returnVect[0,32*i+j]=int(lineStr[j]) #returnVect第0行,32*i+j列被赋值为文本中第i行第j列的数
return returnVect构建手写数字识别系统
#手写数字识别系统
def handwritingClassTest():
hwLabels=[]
trainingFileList=listdir('trainingDigits') #listdir返回指定文件夹里的文件名列表
m=len(trainingFileList) #trainingDigits文件夹下的文件数量
trainingMat=zeros((m,1024)) #构建m*1024矩阵
for i in range(m):
fileNameStr=trainingFileList[i] #第i个训练文件
fileStr=fileNameStr.split('.')[0] #用.对文件名进行切片,并且返回第一个
classNumStr=int(fileStr.split('_')[0])#用_进行切片,返回第一个,并且转化为int,经过这两步操作后得到训练集的真实标签
hwLabels.append(classNumStr) #依次添加到标签列表
trainingMat[i,:]=img2vector('trainingDigits/%s' % fileNameStr) #训练集第i行为第i个文件转化为1*1024后的结果
#测试集
testFileList=listdir('testDigits')
errorCount=0.0
mTest=len(testFileList)
for i in range(mTest):
fileNameStr=testFileList[i]
fileStr=fileNameStr.split('.')[0]
classNumStr=int(fileStr.split('_')[0])
vectorUnderTest=img2vector('testDigits/%s' % fileNameStr)
classifierResult=classify0(vectorUnderTest,\
trainingMat,hwLabels,3) #使用KNN算法
print("the classifier came back with :%d,the real answer is :%d"\
%(classifierResult,classNumStr))
if(classifierResult!=classNumStr):errorCount+=1.0
print("\nthe total number of errors is :%d" %errorCount)
print("\nthe total error rate is :%f"% (errorCount/(float)(mTest)))真的可以说是amazing了。
运行结果
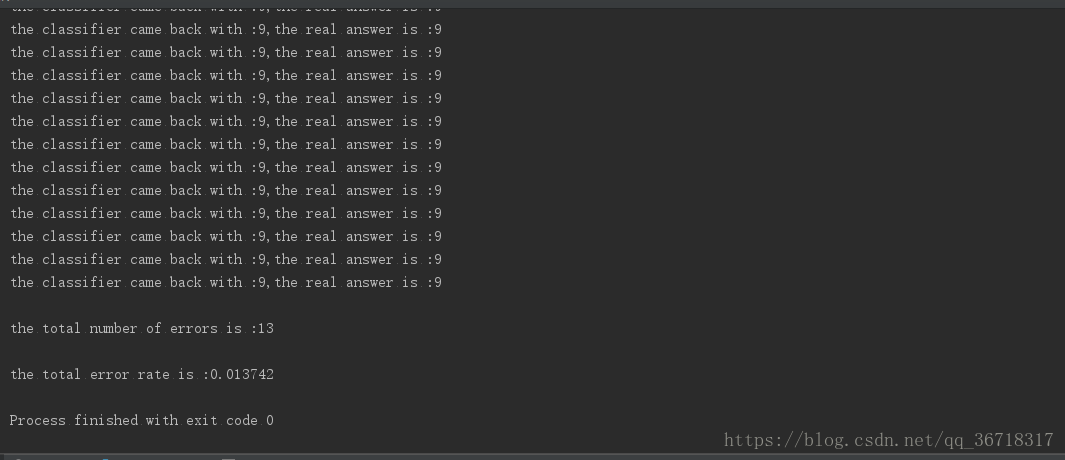
不过这个算法的空间复杂度和时间复杂度应该很高了。。。