约会网站的配对效果案例简介
某人在约会网站上寻找适合自己的对象,约会网站会推荐不同的人选,经过一番总结,发现这些人大致可以分为三类:不喜欢的人、魅力一般的人、极具魅力的人
但是,约会网址推荐的人选仍然不能归入到恰当的类别中。这时就希望有个分类软件可以更好地帮助她将推荐的对象划分到确切的分类中,于是收集了一些网站未曾记录的数据信息,她认为这些数据更有助于推荐对象的归类。
数据导入
数据文件:链接:https://pan.baidu.com/s/1_IRyRSC62sFWV_IoM0wWlg 密码:5ndu
这些数据存放在文本文件datingTestSet2.txt中,每个样本数据占一行,总共1000行。数据特征包括:
- 每年获得的飞行常客里程数
- 玩视频游戏所耗时间百分比
- 每周消费的冰淇淋公升数
在将以上数据输入到分类器之前,我们需要将待处理的数据的格式改变为分类器可以接受的格式。
代码:
# 将文本记录转换为Numpy
def file2matrix(filename):
fr = open(filename) # 打开文件
arrayOLines = fr.readlines()
numberOfLines = len(arrayOLines) # 得到文件行数
returnMat = zeros((numberOfLines, 3)) # 创建0填充的Numpy矩阵
classLabelVector = [] # 创建空列表
index = 0
for line in arrayOLines: # 循环处理文件中的每行数据
line = line.strip() # 使用strip函数,截取掉所有的回车字符
listFromLine = line.split('\t') # 将上一步得到的整行数据分割成一个元素列表
returnMat[index, :] = listFromLine[0:3] # 选取前3个元素,形成特征矩阵
classLabelVector.append(int(listFromLine[-1])) # 索引值-1选取列表中的最后一列,将其存储到classLabelVector中(必须明确告知存储元素值为整型)
index += 1
return returnMat, classLabelVector
# 测试
datingDataMat, datingLabels = file2matrix('data/datingTestSet2.txt') # 注意自己文件相对路径
print(datingDataMat)
print(datingLabels[0:20])运行结果1:

数据可视化
import matplotlib
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(111)
# ax.scatter(datingDataMat[:, 1], datingDataMat[:, 2], 15.0 * array(datingLabels), 15.0 * array(datingLabels))
# plt.show() # 图1
# ax.scatter(datingDataMat[:, 0], datingDataMat[:, 1], 15.0 * array(datingLabels), 15.0 * array(datingLabels))
# plt.show() # 图2运行结果2:
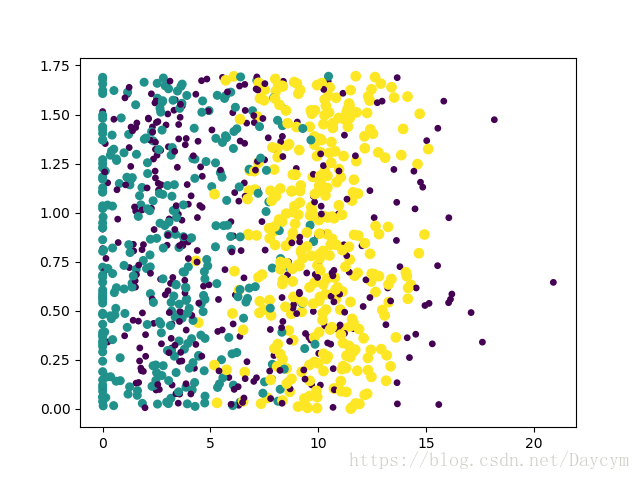
图1:有样本分类标签的约会数据散点图,采用第二、三列属性来表示数据,虽然能够比较容易的区分数据从属类别,但很难根据这张图得出结论性信息
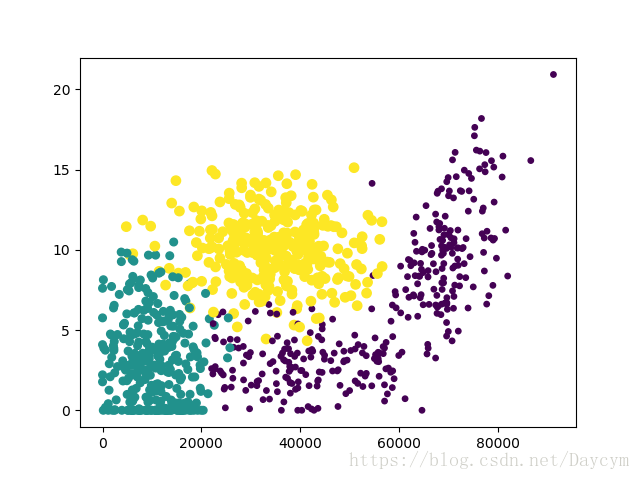
图2:有样本分类标签的约会数据散点图,采用第一、二列属性来表示数据,每年赢得的飞行常客里程数与玩视频游戏所占百分比,更容易区分数据点的从属。
数据归一化
随机选取两个数据计算距离:
我们很容易发现,上面计算距离的公式中差值最大的属性对计算结果的影响最大,也就是说,每年获取的飞行常客里程数对于计算结果的影像将远远大于其他两个特征,显然,这并没有什么依据,参生这种情况的就是里程数的数值远大于其他特征值,因此我们需要对数据进行预处理——数据归一化
归一化公式:
此公式可将任意取值范围的特征值转化为0到1内的值。
代码:
归一化特征值
def autoNorm(dataSet):
minVals = dataSet.min(0) # 最小值 参数0是的函数可以从列中选取最小值
maxVals = dataSet.max(0) # 最大值
ranges = maxVals - minVals # 取值范围
normDateSet = zeros(shape(dataSet)) # 创建与dataSet同型的0填充矩阵
m = dataSet.shape[0] # 每列数据个数
normDateSet = dataSet - tile(minVals, (m, 1)) # 每列原来的数据减去没列最小值
normDateSet = normDateSet / tile(ranges, (m, 1)) # 除以取值范围
return normDateSet, ranges, minVals
# 测试
normMat, ranges, minVals = autoNorm(datingDataMat)
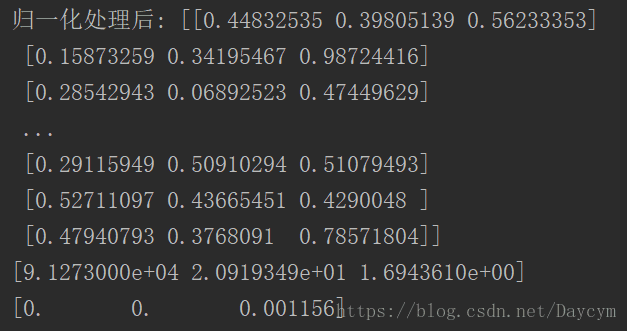
print("归一化处理后:", normMat)
print(ranges)
print(minVals)运行结果3:
约会网站的测试代码
# 分类器针对约会网站的测试代码
def datingClassTest():
hoRatio = 0.10
datingDataMat, datingLabels = file2matrix('data/datingTestSet2.txt') # 读取数据
normMat, ranges, minVals = autoNorm(datingDataMat) # 归一化处理
m = normMat.shape[0]
numTestVecs = int(m * hoRatio) # 用于测试的数据
errorCount = 0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 3) # 分类函数
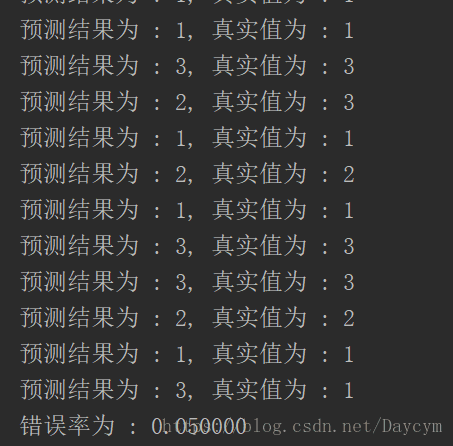
print("预测结果为 : %d, 真实值为 : %d" % (classifierResult, datingLabels[i]))
if (classifierResult != datingLabels[i]):
errorCount += 1
print("错误率为 : %f" % (errorCount / float(numTestVecs)))
# 测试
datingClassTest()运行结果4(只截取了部分):
约会网站预测代码
代码:
# 约会网站预测函数
def classifyPerson():
resultList = ['不喜欢的人', '魅力一般的人', '极具魅力的人']
percentTats = float(input("玩视频游戏所耗时间百分比:"))
ffMiles = float(input("每年获得的飞行常客里程数:"))
iceCream = float(input("每年消费冰淇淋公升数:"))
datingDataMat, datingLabels = file2matrix("data/datingTestSet2.txt")
normMat, ranges, minVals = autoNorm(datingDataMat)
inArr = array([ffMiles, percentTats, iceCream])
classifierResult = classify0((inArr - minVals) / ranges, normMat, datingLabels, 3)
print("你对这个人的印象是:", resultList[classifierResult - 1])
# 测试
classifyPerson()运行结果5:

手写数字识别系统案例
此系统只能识别0到9,需要识别的数字已经使用图形处理软件,处理成具有相同的色彩和大小:宽度是32像素*32像素的黑白图像,尽管采用文本格式存储图像不能有效地利用内存空间,这里还是将图像转化为文本格式。
数据准备
在上个案例文件夹中两个子目录:目录trainingDigits中包含2000个例子,目录testDigits中包含大约900个测试数据。
首先将图像格式处理为一个向量
代码:
# 将图像格式转化为向量 32*32 --> 1*1024
def img2vector(filename):
returnVect = zeros((1, 1024)) # 创建1*1024的0填充向量矩阵
fr = open(filename) # 打开文件
for i in range(32): # 读取文件的前32行,前32列
lineStr = fr.readline()
for j in range(32):
returnVect[0, 32 * i + j] = int(lineStr[j])
return returnVect # 返回每个图像的向量
testVector = img2vector('data/testDigits/0_13.txt')
print(testVector[0, 0:31])
print(testVector[0, 32:63])运行结果6:
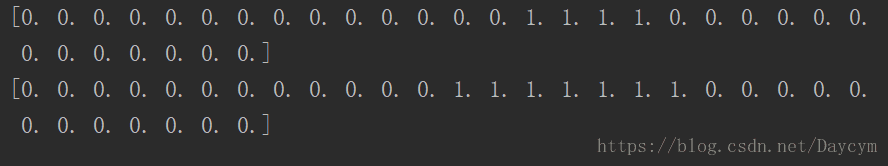
使用k-近邻算法识别手写数字代码
# 手写数字识别系统的测试代码
def handwritingClassTest():
hwLabels = []
trainingFileList = os.listdir('data/trainingDigits') # 获取目录内容 python3需要引入import os
m = len(trainingFileList)# 计算目录中的文件数
trainingMat = zeros((m, 1024)) # 创建一个m行1024列的训练矩阵,每行数据存储一个图像
for i in range(m): # 从文件名中解析出分类数字,文件名命名是按照规则命名的
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr) # 存储到hwLabels向量中
trainingMat[i, :] = img2vector('data/trainingDigits/%s' % fileNameStr) # 调用函数,载入图像
testFileList = os.listdir('data/testDigits') # 测试数据集
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('data/testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3) # 使用classify0函数测试该目录下的每一个文件
print("预测结果为:%d,真实值为:%d" % (classifierResult, classNumStr))
if (classifierResult != classNumStr):
errorCount += 1.0
print("预测错误的总数为:%d" % errorCount)
print("手写数字识别系统的错误率为:%f" % (errorCount / float(mTest)))
# 测试手写数字识别系统
handwritingClassTest()运行结果7:(只截取了结果)

总结
-近邻算法的一般流程:收集数据、准备数据、分析数据、测试算法、使用算法
在准备数据时,我们需要对数据进行一些预处理,使其能够让分类器能够接受。此外,在使用算法前,我们需要对分类器的好坏进行评价,一般使用错误率。
参考书籍《统计学习方法》、《机器学习实战》