KNN概述
k-近邻算法就是通过计算不同特征值之间的距离来进行分类的算法。假设我们现在有一个样本集,每个样本都有几个特征用来描述这个样本,以及一个它所属分类的标签。当我们拿到一个没有标签的样本时,该如何判断它属于哪个样本呢?我们将这个样本与每一个已知标签的样本做比较,找到相似度最大的k个样本,记录它们的标签。最后,我们统计这些标签中每个类出现的次数,这个时候我们就有很大把握认为未知样本属于出现次数最多的类。
举一个电影分类的例子,要区分一部电影是动作片还是爱情片(没有爱情动作片这个选项!),我们可以根据影片中亲吻或者打斗场景出现的次数来划分。我们有如下数据集:
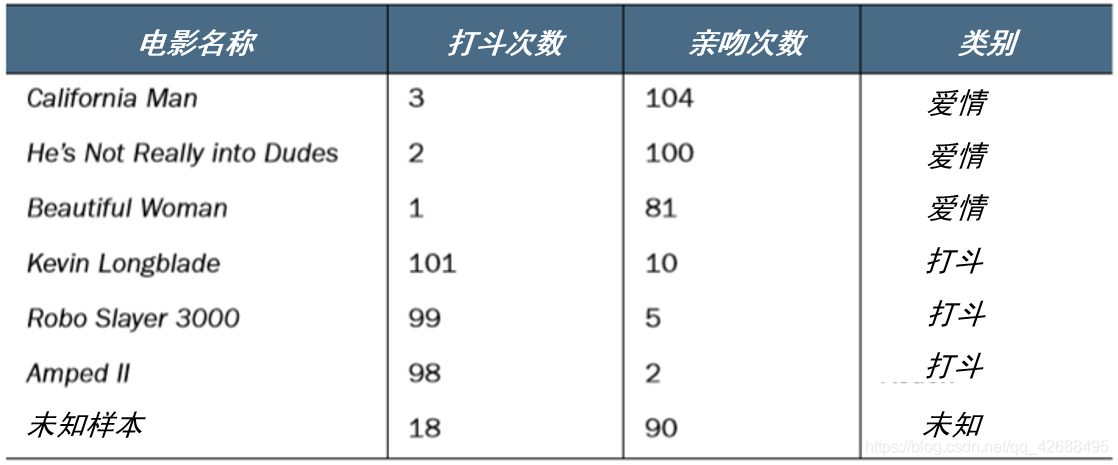
在坐标系中标出这些样本

我们计算一下未知样本到各个样本的距离,可以发现,未知样本距离与标签为爱情片的电影距离较近,于是我们可以认为未知样本属于爱情片。
好了,知道了KNN的相关概念,我们用经典的手写识别系统来进行KNN算法实战
一、导入样本
样本数据格式为32x32的二进制图像

首先将样本转换成1x1024的向量
def img2vector(filename):
vector = zeros((1, 1024))
f = open(filename)
for i in range(32):
s = f.readline()
for j in range(32):
vector[0, 32 * i + j] = int(s[j])
return vector
添加knn分类算法
def knn(testSet, trainSet, label, k):
m = trainSet.shape[0]
# 求欧式距离
diffMat = tile(testSet, (m, 1)) - trainSet
sqDiffMat = diffMat ** 2
# 计算每一行的和,即计算未知样本和每一个已知样本的偏差的平方和
sqDistance = sqDiffMat.sum(axis=1)
# 开根号
distances = sqDistance ** 0.5
# 将距离从小到大排列,并记录索引
sortedDistIndex = distances.argsort()
# 创建一个字典,用来统计投票结果
countDict = {}
# 记录距离最近的前k个样本,并进行投票
for i in range(k):
votelabel = label[sortedDistIndex[i]]
countDict[votelabel] = countDict.get(votelabel, 0) + 1
sortedCount = sorted(countDict.items(), key=operator.itemgetter(1), reverse=True)
return sortedCount[0][0]
添加测试代码
def test():
label = []
# 获取目录文件
filelist = listdir("trainingDigits")
m = len(filelist)
trainMat = zeros((m, 1024))
for i in range(m):
filename = filelist[i]
# 从文件名获取样本标签
s = filename.split(".")[0]
nums = s.split("_")[0]
label.append(nums)
trainMat[i, :] = img2vector("trainingDigits/" + filename)
filelist = listdir("testDigits")
errorCount = 0.0
m = len(filelist)
for i in range(m):
filename = filelist[i]
s = filename.split(".")[0]
testlabel = s.split("_")[0]
testset = img2vector("testDigits/" + filename)
result = knn(testset, trainMat, label, 3)
print("truelabel:" + testlabel + " result:" + result + " " + str(result == testlabel))
if result != testlabel:
errorCount = errorCount + 1
print("number of errors: " + str(errorCount))
print("error rate: " + str(errorCount / m * 100) + "%")
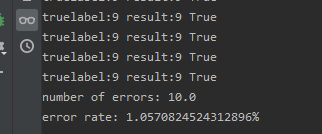
运行test(),运行结果如下
样本集以及机器学习实战这本书的pdf都在这里,提取码8v0a