集群规划
hadoop HA集群的搭建依赖zookeeper,所以选取三台当作zookeeper集群,这次准备了4台主机,分别是hadoopm,hadoopsm,slave1,slave2,其中hadoopm和hadoopsm做namenode的主备切换,slave1,slave2做resourcemanager的主备切换
| hadoop'm | hadoop's'm | slave1 | slave2 | |
| namenode | √ | √ | ||
| datanode | √ | √ | √ | √ |
| resourcemanager | √ | √ | ||
| nodemanager | √ | √ | √ | √ |
| zookeeper | √ | √ | √ | |
| journalnode | √ | √ | √ | |
| zkfc | √ | √ |
1.下载 hadoop-2.7.5.tar.gz 安装包
2.通过CRT软件上传到hadoopm号机器
3.解压软件到目录下/usr/local
tar -zxvf hadoop-2.7.5-centos-6.7.tar.gz -C /usr/local
4.修改hadoop-env.sh 配置文件
先查看jdk安装路径
echo $JAVA_HOME
vim hadoop-env.sh 修改为:

5.修改core-site.xml 配置文件
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://BBDcluster</value>
<description></description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<!--value>file:/home/hadoop/data/hdfs/tmp</value-->
<value>/home/hadoop/data/hdfs/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop-m:2181,hadoop-sm:2181,slave1:2181</value>
</property>
<!-- hadoop链接zookeeper的超时时长设置 -->
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>1000</value>
<description>ms</description>
</property>
</configuration>
6.修改hdfs-site.xml配置文件
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/data/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/data/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>BBDcluster</value>
</property>
<property>
<name>dfs.ha.namenodes.BBDcluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.BBDcluster.nn1</name>
<value>hadoop-m:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.BBDcluster.nn2</name>
<value>hadoop-sm:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.BBDcluster.nn1</name>
<value>hadoop-m:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.BBDcluster.nn2</name>
<value>hadoop-sm:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop-m:8485;hadoop-sm:8485;slave1:8485/BBDcluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/data/hdfs/journalnode</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.BBDcluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.ms</name>
<value>60000</value>
</property>
</configuration>
7.修改mapred-site配置文件
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-m:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-m:19888</value>
</property>
</configuration>
8.修改yarn-site.xml 配置文件
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>slave1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave2</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 制定resourcemanager的状态信息存储在zookeeper集群上 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 指定当前机器master188作为rm1 -->
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop-m:2181,hadoop-sm:2181,slave1:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
</configuration>
9.修改slaves文件
hadoop-m
hadoop-sm
slave1
slave2
10.分发安装包
scp -r hadoop-2.7.5/ hadoop-sm:$PWD
scp -r hadoop-2.7.5/ slave1:$PWD
scp -r hadoop-2.7.5/ slave2:$PWD
11.配置环境变量
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_161
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib/dt.jar:${JRE_HOME}/lib/rt.jar
export HADOOP_HOME=/usr/local/hadoop-2.7.5
export ZOOKEEPER_HOME=/usr/local/zookeeper-3.4.10
export PATH=$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:${JAVA_HOME}/bin:$PATH
12.务必按照下面的步骤一步一步来
1、启动zookeeper
zkServer.sh start
jps查看QuorumPeerMain进程是否开启
查看是否成功选举
zkServer.sh status

2、在你配置的各个journalnode节点启动该进程(这里我们是hadoopm,hadoopsm,slave1)
hadoop-daemon.sh start journalnode
jps查看JournalNode进程是否开启
为了方便观察建议先删除zookeeper下的节点 rmr /xxxxx
3、格式化namenode
先选取一个namenode(hadoopm)节点进行格式化
选哪个都行,案例选择hadoopm
hadoop namenode -format
4、要把在hadoopm节点上生成的元数据 给复制到 hadoopsm上
[hadoop@hadoop-m data]$scp -r hadoopdata/ hadoop03:$PWD
出现如下所示即为成功
VERSION 100% 206 0.2KB/s 00:00
fsimage_0000000000000000000 100% 322 0.3KB/s 00:00
fsimage_0000000000000000000.md5 100% 62 0.1KB/s 00:00
seen_txid 100% 2 0.0KB/s 00:00
5、格式化zkfc
只能在nameonde节点进行(案例在hadoopm节点格式化)
[hadoop@hadoopm data]$hdfs zkfc -formatZK
出现下图即为成功

到此为止。hadoop集群的初始化就OK 了
以上的初始化在成功了之后,就坚决不能再做了。!!!!!
13.启动集群:
启动Hadoop HA 集群之前,一定要确保zk集群启动正常
启动HDFS : start-dfs.sh 不管在哪个节点都OK(这里我们在hadoopm启动)
如果zkfc启动不起来:执行 hadoop-daemon.sh start zkfc
启动YARN集群: start-yarn.sh 最好在YARN的主节点上执行(这里我们在slave1启动),另外一个resourcemanager必须手动启动(在slave2启动)
yarn-daemon.sh start resourcemanager
slave2成功启动后为下图所示

启动历史服务器(在hadoopm机器):mr-jobhistory-daemon.sh start historyserver
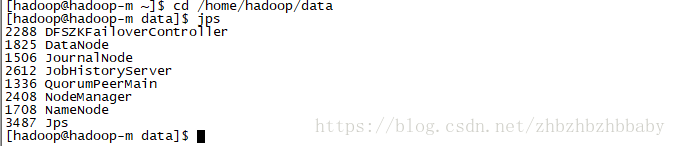
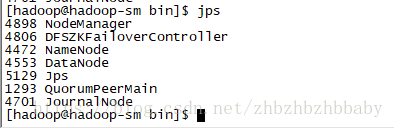

14.检查web是否正常
http://hadoop02:50070
http://hadoop03:50070
http://hadoop04:8088
http://hadoop05:8088 ---->注意观察是否迅速变为http://hadoop04:8088,即为成功
http://hadoop02:19888
15.测试是否真的为高可用模式集群
1)轻量级测试:
先查看hadoopm的状态为active

先jps查看一下namenode进程,然后干掉
kill-9 1708

此时再去看hadoopsm的状态已经切换为active了
图

然后我们在用守护进程脚本的单个命令,来启动hadoopm的namenode
hadoop-daemon.sh start namenode
此时hadoopm已经变成standby了。

2)重量级测试:
在hadoopm号机器(此时为standby状态)准备输入下面命令,
[hadoop@hadoopm ~]$ hadoop fs -put hadoop-2.7.5.tar.gz /
同时在hadoopsm号机器准备好下面的命令,不要提交
jps先查看hadoopsm的namenode进程
然后 准备 kill掉
然后执行第一条命令在hadoopm机器上传大文件(预计要10秒,我们会在5秒的时候杀死hadoopsm机器)
此时会在hadoopm机器报错。并且在..14 more 之后停顿一会,出现下面的状态
图
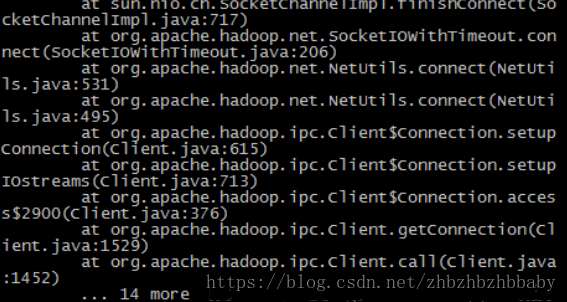
此时hadoop02为active状态。

接下来我们查看文件
看样子大小是对的。然后我们下载下来进行仔细校对
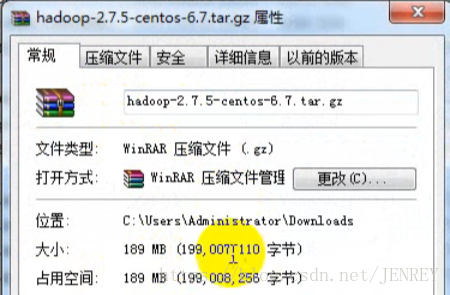

发现一模一样。
Hadoop HA 集群重装:
1、直接删掉所有的数据存储目录
journaldata hadoopdata
2、直接删掉zk中所有跟hadoop相关的信息
如果删不掉也没事, 再次初始化的时候会提醒 yes or no
yes
增加配置:(企业一定要改)修改hadoop-env.sh文件

namenode堆内存参数:

JVM垃圾回收器:
