使用centos6.5虚拟机安装ip:192.168.0.31
创建目录
/opt --父目录
/opt/modules --存放软件的安装目录
/opt/softwares --存放软件包(tar,zip,bin)
/opt/tools --存储工具目录(eclipse等)
/opt/data --存储测试数据
/home/hadoop --存储工具盒测数据目录
Apache Hadoop 单机模式安装
卸载旧的jdk:
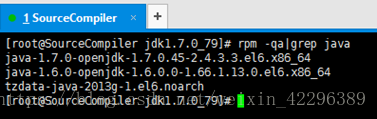
# rpm -qa|grep java
一般将获得如下信息:
tzdata-java-2013g-1.el6.noarch
java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64
java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.x86_64
<3>卸载OPENJDK
rpm -e --nodeps tzdata-java-2013g-1.el6.noarch
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64
rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.x86_64
1)首先安装jdk
tar -zxvf jdk-8u73-linux-x64.tar.gz
mv jdk1.8.0_73 /opt/modules/
vi /etc/profile
#java
export JAVA_HOME=/opt/modules/jdk1.8.0_73
export JRE_HOME=/opt/modules/jdk1.8.0_73/jre
export CLASSPATH=$JAVA_HOME/lib
export PATH=:$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
source /etc/profile
java -version
2)配置SSH无密码登录
注:ssh 用户名@主机名 ,如果直接ssh 主机名,它会以你那台机器的当前用户登录,所以另一台机器要有同样的用户。从一台Linux主机登录到另一台Linux主机上(或发送一条指令到另外的机器上执行),如果集群有很多台机器,你挨个输密码肯定不行,所以要配置SSH无密码登录。
# 创建新用户hadoop
useradd -m hadoop -s /bin/bash
# 设置密码
passwd hadoop
#安装openssh-server
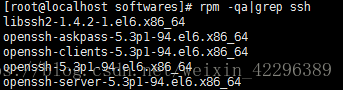
这样则不需要安装,否则:
yum install openssh-clients
yum install openssh-serve
切换hadoop用户cd回车到自己的home执行:
ssh-keygen -t rsa #多次回车生成秘钥
cd .ssh #进到隐藏目录ll
cp id_rsa.pub authorized_keys
chmod 600 ./authorized_keys #修改秘钥权限
#检测是否配置成功
ssh localhost
3)安装Hadoop2.7.5
su root
tar -zxvf hadoop-2.7.5.tar.gz
mv hadoop-2.7.5 /opt/modules/
chown -R hadoop:hadoop /opt/modules/jdk1.8.0_161/
chown -R hadoop:hadoop /opt/modules/hadoop-2.7.5/
配置环境变量vi /etc/profile
#hadoop
export HADOOP_HOME=/opt/Hadoop/hadoop-2.7.5
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$HADOOP_HOME/bin
source /etc/profile
测试:
修改/opt/modules/hadoop-2.7.5/etc/hadoop下的hadoop-env.sh
export JAVA_HOME=${JAVA_HOME}#将这个改成JDK路径,如下
export JAVA_HOME=/opt/modules/jdk1.8.0_161
export HADOOP_CONF_DIR=/opt/modules/hadoop-2.7.5/etc/hadoop
source ./hadoop-env.sh
伪分布式安装:
修改/opt/modules/hadoop-2.7.5/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/tmp</value>
</property>
</configuration>
修改hdfs-site.xml(去掉注释)
<configuration>
<property><!--设置副本数1,不写默认是3份-->
<name>dfs.replication</name>
<value>1</value>
</property>
<property><!--权限检查关闭-->
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
拷贝mapred-site.xml.template一份,修改为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
加入
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.tracker</name>
<value>hdfs://192.168.0.31:9001</value>
<final>true</final>
</property>
</configuration>
修改yarn-site.xml
<configuration><property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.0.31:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.0.31:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.0.31:8031</value>
</property>
</configuration>
格式化hdfs
hdfs namenode -format
切换hadoop用户
启动hdfs
start-dfs.sh
启动yarn
start-yarn.sh
查看是否成功启动

访问http://192.168.0.31:8042
三种启停方式:
第一种 Sbin目录下:
./start-all.sh
./stop-all.sh
第二种
./start-dfs.sh ./start-yarn.sh
./stop-dfs.sh ./stop-yarn.sh
注意tmp 和log的权限可能导致hadoop用户不能启动5个守护进程
第三种 开启
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
hadoop-daemon.sh start secondarynamenode
hadoop-daemon.sh start jobtracker
hadoop-daemon.sh start tasktracker
停止:
hadoop-daemon.sh stop jobtracker
hadoop-daemon.sh stop tasktracker
hadoop-daemon.sh stop namenode
hadoop-daemon.sh stop datanode
hadoop-daemon.sh stop secondarynamenode
Log分为两种:
1)以log结尾的日志
通过log4j日志记录格式进行记录的日志,采用的日常滚动文件后缀策略来命名。内容比较全。
2)以out结尾的日志
记录标准输出和标准错误的日志,内容比较少。一般不怎么看。默认情况,系统保留最新的5个日志文件。
日志文件的存储位置在 hadoop-env.sh中HADOOP_LOG_DIR配置
