这几天因为学习需要搭建了一个由3个节点组成的hadoop和spark分布式集群,做记录如下(已生成目录,可按需查看)。
集群搭建环境及安装软件版本
- centos6
- jdk1.8.0_161
- hadoop2.7.5
- Spark2.3.0
- Scala-2.11.8
- Anaconda2-5.1.0
- IDEA-2018.1
搭建分布式集群的几个主要步骤:
- 下载好搭建分布式集群的软件
- 修改集群各个虚机名称
- 网络配置:修改集群各个虚机hosts文件
- 配置SSH:使得节点间可以互相免密登录
- 安装jdk:在集群的各个虚机上安装jdk并配置相应jdk环境变量
- 安装hadoop:先在主节点上安装hadoop,修改完配置文件后再将主节点的hadoop文件映射至从节点并配置好各节点相应环境变量
- 安装spark:先在主节点上安装spark,修改完配置文件conf后再将主节点的spark文件映射至从节点并配置好各节点相应环境变量
- 安装scala:在集群的各个虚机上安装scala并配置相应scala环境变量
- 安装Anaconda2:在集群的各个虚机上安装Anaconda2并配置相应Anaconda2环境变量
- 安装IDEA-2018.1.1.tar.gz:在主节点上安装IDEA
- 因为是初次安装,所以采取了在各个节点安装jdk、hadoop、spark、scala、Anaconda2和配置相应环境变量的较繁琐安装方式,但实际上步骤5-9完全可以只在主机上进行然后再将安装好的jdk、hadoop、spark、scala、Anaconda2打包映射到各个从节点,并用主节点的环境变量文件profile.txt替换其他节点的方式安装。
一、修改集群各个虚机的名称
因为拿到手的虚机虚机名不符合自己的开发需求需要更改,加之虚拟机名会影响分布式集群环境变量的配置,所以把修改集群虚机名放在搭建分布式平台的第一步。期望修改后的虚机名为:主节点:Master,从节点1:slave1, 从节点2:slave2。修改的步骤如下(以主节点为例):
- 打开在虚机根路径下的/etc/sysconfig的network 文件,打开方式可为在指令行输入
文件打开后将第二行文件修改为HOSTNAME=Master,修后侯如下所示:vim /etc/sysconfig/network - 其他节点的虚机名按照步骤1修改。
- 将个节点的虚机的network文件修改后,用指令重启集群,重启指令为 shutdown -r now ,重启后新的虚机名开始起效。(这一步的重启也可以等到第二步的网络配置完成后)
注:如果你的虚机集群是远程登录的也可以直接用指令重启,不需要集群物理机管理者授权,重启后过一段时间便可以重新连接到集群。 - 重启虚机后登陆centos系统,打开终端进入shell命令提示符状态,显示如下内容表示修改成功:
注:我的集群centos版本和配置相互一致,且都是以root账户登录。[root@Master ~]#

二、网络配置
修改集群中个节点的hosts文件,使得节点间可以相互ping通,为配置SSH做准备。修改步骤和内容如下:
- 打开Master节点的hosts文件,指令如下:
[root@Master ~]# vim /etc/hosts - 在Master节点的hosts文件中增加slave1、slave2的IP和主机映射关系,修改后如下所示:
- 参照Master节将slave1、slave2的hosts文件修改成Master节点的hosts文件一样。
- 重启虚拟机群
- 在Master节点测试是否能ping 通slave1、slave2,测试指令如下:
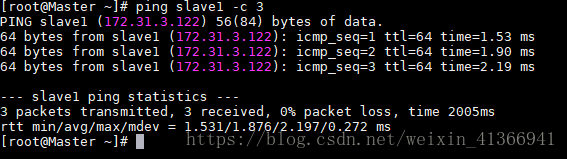
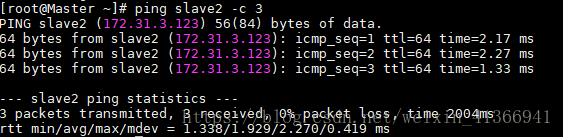
ping通slave1后如下示:ping slave1 -c 3
ping slave2 -c 3
ping通slave2后如下示: - 其他节点的ping测试参考Master节点

三、配置SSH
使得集群间可以实现免密登录,从而使得集群中的Hadoop名称节点(Namenode)可以启动集群中所有机器的Hadoop守护进程。
3.3 SSH的免密配置:
- centos默认安装了SSH的服务端,在进行SSH的免密配置之前先需要在集群的各个虚机上先安装好SSH的客户端。SSH客户端的安装指令为:
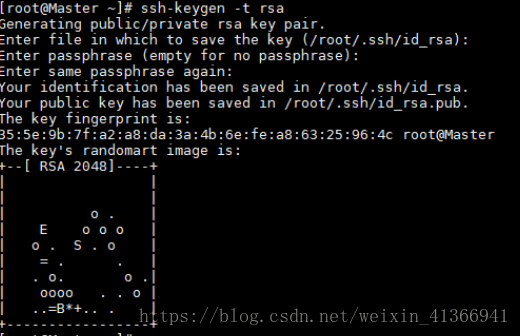
# yum install openssh-server - 生成私钥和公钥:在三个节点中使用如下命令生成私钥和公钥
执行后输出如下图示:# ssh-keygen -t ras #执行该命令后,遇到提示信息,一直按Enter键就可以
命令执行完毕后,可以在~/.ssh路径下看到两个文件:id-rsa和id_rsa.pub,其中,以.pub结尾的是公钥。把公钥命名为authorized_keys_master.pub,使用的命令如下:
同样地将他其他两个节点的公钥名命名为authorized_keys_slave1.pub、authorized_keys_slave2.pub。# cd ~/.ssh # mv id_rsa.pub authorized_keys_master.pub - 合并公钥信息:把两个节点(slave1和slave2)的公钥使用scp指令映射Master节点的~/.ssh目录。
使用cat指令把3个节点的公钥信息保存到authorized_keys文件,指令如下:
# scp authorized_keys_slave1.pub root@Master:~./ssh #在节点slave1上执行# scp authorized_keys_slave2.pub root@Master:~/.ssh #在节点slave2上执行
合并完成后,查看文件的内容下所示:$ cat authorized_keys_master.pub >>authorized_keys $ cat authorized_keys_slave1.pub >>authorized_keys $ cat authorized_keys_slave2.pub >>authorized_keys

完成合并后再使用scp命令把authorized_keys 密码文件发送到slave1和slave2节点,命令如下:
# scp authorized_keys root@slave1:~./ssh # scp authorized_keys root@slave2:~/.ssh
传输完毕后,需要在3台节点使用如下设置authorized_keys 的读写权限:
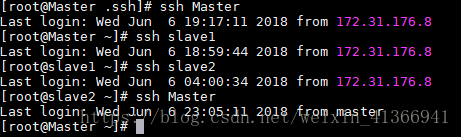
# cd ~/.ssh # chmod 400 authorized_keys 4. 验证免密登录:在各节点中使用ssh命名,验证他们之间是否可以免密登录:
$ssh Master $ssh slave1 $ssh slave2 配置成功免密登录效果如下:
四、安装jdk
hadoop和scala都是基于jvm虚拟机运行,因此我们需要给各个节点的虚机安装上jdk并为其配置好相应环境变量,此处以主节点安装为例,其他节点与主节点安装及配置方式一致。
- 在/opt路径下新建一个文件夹app并将集群软件(包括hadoop、spark等)全部在/opt/app路径下,指令如下:
# mkdir /opt/app - 将jdk解压到app路径
# cd /opt/app tar -zxvf ./jdk-8u161-linux-x64.tar.gz 打开profile文件,添加jdk环境变量
在文件中添加环境变量如下:# vim /etc/profile
export JAVA_HOME=/opt/app/jdk1.8.0_161 export PATH=$JAVA_HOME/bin:$PATH 用指令使得jdk的环境变量生效
# suorce /etc/proflle
五、安装hadoop
- 在主节点中的/opt/app路径下将hadoop安装包解压,并将解压后的文件夹重命名为hadoop
# cd /opt/app
# tar -zxvf ./hadoop-2.7.5.tar.gz
# mv hadoop2.7.5 hadoop - 修改hadoop路径下的/etc/hadoop下的core-site.xml、hdfs-site.xml、mapreduce-site.xml、yarn-site.xml、slaves五个文件
1)修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/app/hadoop/tmp</value> #临时文件路径
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration><configuration>
<property>
<name>dfs.replication</name>
<value>2</value> #备份数为2
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///opt/app/hadoop/tmp/dfs/namenode</value> #名称节点路径
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file://opt/app/hadoop/tmp/dfs/datanode</value> #数字节点路径
</property>
<property>
<name>dfs.http.address</name>
<value>Master:50070</value> #设为主节点主机名:Master
</property>
</configuration><configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration><configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>6144</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/opt/app/hadoop/tmp/localdir</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/opt/app/hadoop/tmp/logdir</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>10</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://Master:19888/jobhistory/logs</value>
</property>
</configuration>
Master
slave1
slave2- 配置环境变量
export HADOOP_HOME=/opt/app/hadoop export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH - 用指令使得环境变量生效
# source /etc/profile - 将主节点上的/opt/app/hadoop文件夹映射到各个节点上。
# cd /opt/app # tar -zcf ./hadoop.master.tar.gz ./hadoop 将/opt/app/hadoop 文件夹压缩并命名为hadoop.master.tar.gz # scp ./hadoop.master.tar.gz slave1:/opt/app # scp ./hadoop.master.tar.gz slave2:/opt/app - 在各个节点上的/opt/app路径的hadoop.master.tar.gz 解压所在路径(以slave1为例)
各节点的环境变量配置参照主节点# cd /opt/app # tar -zxvf ./hadoop/master.tar.gz # chown -R root /opt/app/hadoop #给解压后的hadoop文件夹以可读写权限 - hadoop成功安装测试
在各节点上输入下面的指令若出现hadoop版本信息则安装hadoop成功
# hadoop version - 启动hadoop集群
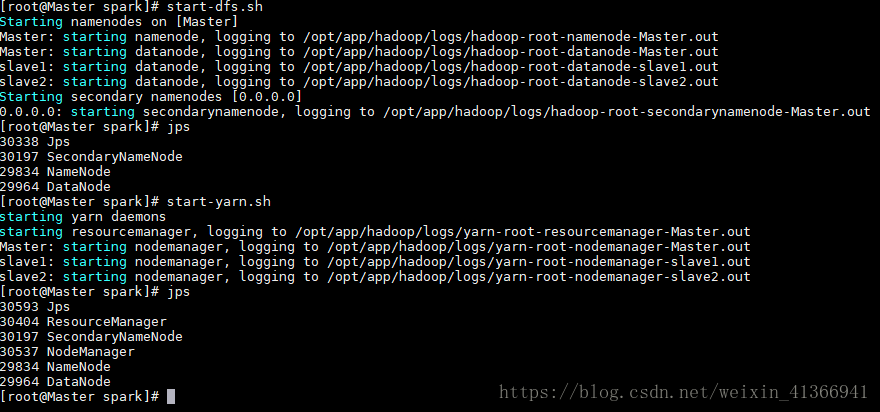
在主节点上执行下列指令
成功启动时下示:# hdfs dfs namenode -format #首次启动需要格式化主节点上的名称节点 # start-dfs.sh # start-yarn.sh
Master节点:
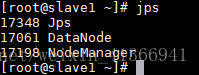
slave1节点:
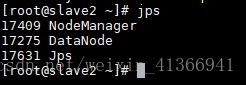
slave2节点: - hadoop集群安装后启动遇到的异常
异常1:启动hadoop集群失败,如下图示
异常原因:主节点的hosts文件里的从节点2 IP地址输入错误

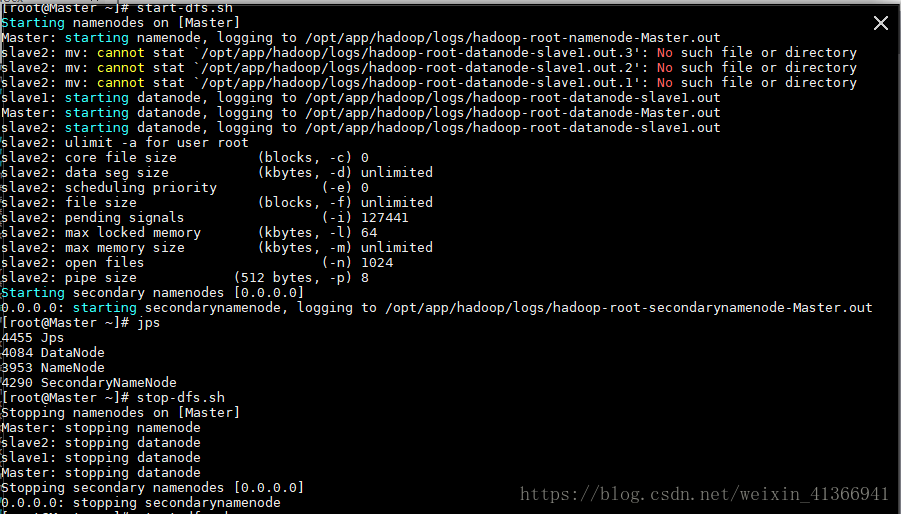

因为当时显示是slave2节点异常,结果一直在slave2节点上查找错误,找了许久没有找到,近乎绝望之际才发现是主节点上的hosts文件配置错误。在这里谨记,集群配置牵一发而动全身,出现错误时记得把各个节点的上的可能相关异常源都审查一遍。异常2:访问hdfs失败,异常如下所示
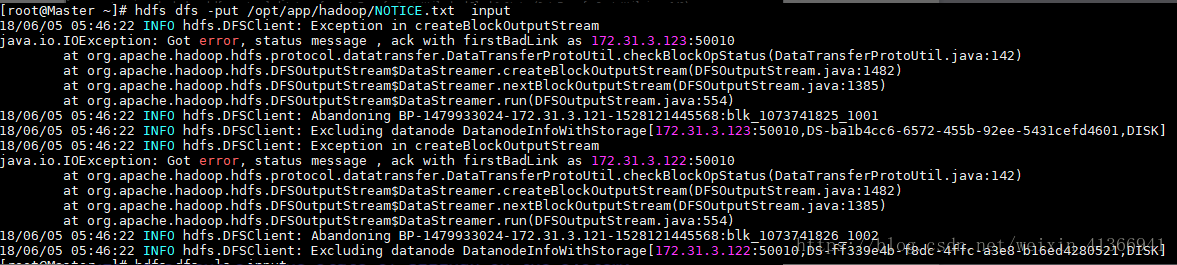
异常原因:未关闭集群防火墙(不知为何看师兄的集群未关闭集群也能正常访问hdfs,这里表示困惑)
解决方案:修改/集群etc/selinux/config文件如下

重启集群后,在各节点指令终端输入如下指令,如果显示"iptables: Firewall is not running"则表示关闭防火墙成功
| service iptables status |
六、安装scala
scala是spark的底层语言,用scala开发spark应用是最为高效的。虽然spark自带scala,但是却不便于我们在IDA工具上进行开发应用,所以这里为spark集群需要安装好scala。- 将scala解压到app路径
-
# cd /opt/app
# tar -zxvf ./scala-2.11.8.tgz
打开profile文件,添加scala环境变量
# vim /etc/profile
- 在文件中添加环境变量如下:
-
export SCALA_HOME=/opt/app/scala-2.11.8 export PATH=$SCALA_HOME/bin:$PATH 用指令使得scala的环境变量生效
# suorce /etc/proflle
- 其他节点scala安装参照主节点
七、安装Spark
- 在主节点中的/opt/app路径下将spark安装包解压,并将解压文件夹重命名为spark,解压及重命名指令如下
| # cd /opt/app # tar -zxvf ./spark-2.3.0-bin-hadoop2.7.tgz # mv spark-2.3.0-bin-hadoop2.7.tgz spark |
- 修改解压后spark/conf路径下的slaves、spark-env.sh及spark-deflauts.conf文件
- 配置conf/slaves
该配置文件用于设置集群中运行Worker节点信息,需要注意的是Master节点不仅运行master进程,也运行worker进程。slaves文件配置如下:Master #主节点名 slave1 #从节点1名 slave2 #从节点2名 - 配置conf/spark-env.sh
该配置文件用于设置spark运行环境,默认的spark/conf目录中没有spark-env.sh文件,需要通过复制或者修改spark-env.sh.template进行创建。使用的命令如下:
然后在打开的spark-env.sh文件中加入如下内容,设置Master为主节点,# cd /app/opt/spark/conf # cp spark-env.sh.template spark-env.sh # vim spark-env.shexport JAVA_HOME=/opt/app/jdk1.8.0_161 export SCALA_HOME=/opt/app/scala-2.11.8 export SPARK_MASTER_IP=Master export HADOOP_CONF_DIR=/opt/app/hadoop/etc/hadoop - 配置conf/spark-deflauts.conf文件
spark.yarn.historyServer.address=Master:18080 spark.history.ui.port=18080 #HistoryServer的web端口 spark.eventLog.enabled=true #是否记录Spark事件,用于应用程序在完成后重构webUI spark.eventLog.dir=hdfs://Master:9000/tmp/spark/events #保存日志相关信息的路径,可以是hdfs://开头的HDFS路径, #也可以是file://开头的本地路径,都需要提前创建 spark.history.fs.logDirectory=hdfs://Master:9000/tmp/spark/event - 配置/etv/profile
打开环境变量配置文件
加入spark环境变量配置如下# vim /etv/profileexport SPARK_HOME=/opt/app/spark export PATH=$SPARK_HOME/bin:SPARK_HOME/sbin:PATH 执行环境变量生效指令
# source /etc/profile分发Spark目录至分节点上
# cd /opt/app # scp ./spark root@slave1:/opt/app/spark # scp ./spark root@slave2:/opt/app/spark
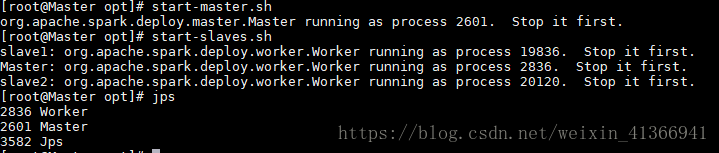
- 启动Spark
在主节点输入如下指令:
启动成功后jps后可看到# start-master.sh # start-slaves.sh
Master节点:
slave1节点:
slave1节点: - 使用spark-shell运行一个spark程序实例
首先启动spark-shell,在任意路径输入如下指令
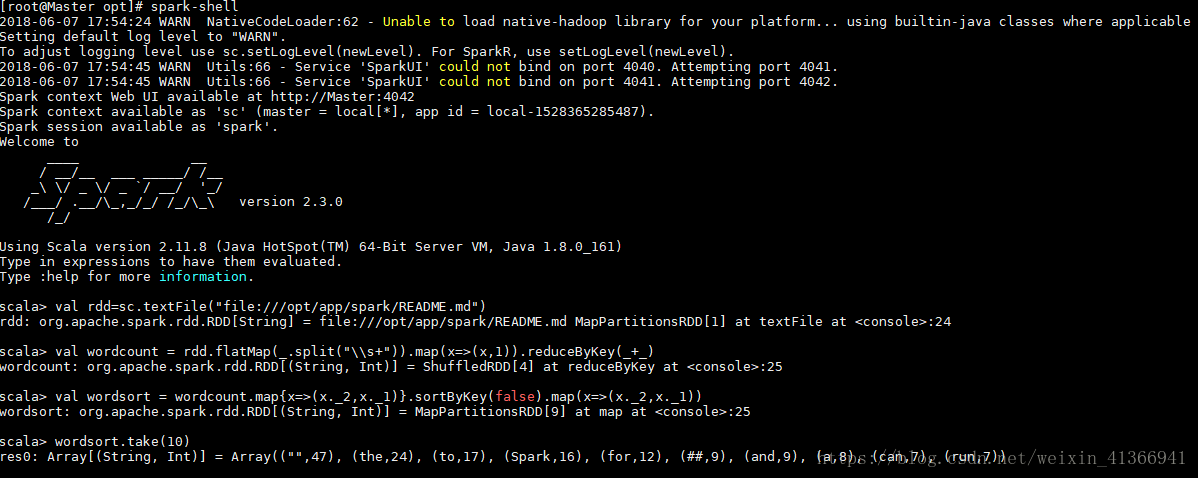
在spark-shell上运行一个简单的wordcount程序# spark-shell
结果如下:scals-> val rdd=sc.textFile("file:///opt/app/spark/README.md") scala-> val wordcount = rdd.flatMap(_.split("\\s+")).map(x=>(x,1)).reduceByKey(_+_) scala-> val wordsort = wordcount.map{x=>(x._2,x._1)}.sortByKey(false).map(x=>(x._2,x._1)) scala-> wordsort.take(10)
启动异常
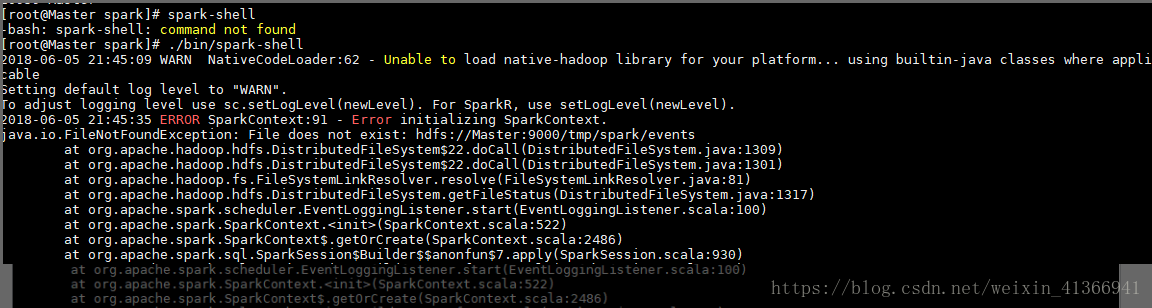
启动spark-shell出现"ERROR SparkContext :Error initializing SparkContext."
报出:"java.io.FileNotFoundExceptio:File does not exist :hdfs:Master:9000/tmp/spark/events"异常说明没有在hdfs上创建tmp/spark/events路径,创建后重新启动spark-shell再运行上面程序时则可正常运行。
异常警示如下:
八、安装Anaconda
在每个节点进行下列操作- 执行安装指令,指令如下:
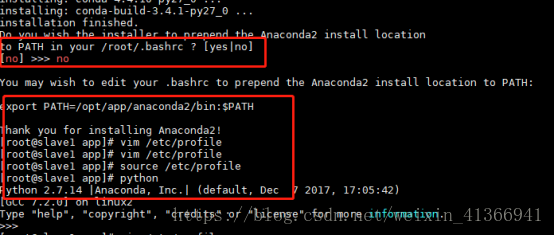
安装时,第一个询问回复yes,第二个询问为Anaconda路径,这里我们不选择默认路径改为[root/anaconda2]>>/opt/app/anaconda,第三个询问为是否将Anaconda路径配置在本地环境变量./root/.bashrc,由于我们是把环境变量统一配置在/etc/profile中,所有也选择nocd /opt/app bash ./Anaconda2-5.1.0-Linux-x86-64.sh
具体安装流程如下:
- 配置环境变量
打开环境变量文件
添加如下语句vim /etc/profileexport ANACONDA2_HOME=/opt/app/anaconda2 export PATH=$ANACONDA2_HOME/bin:$PATH
执行环境变量生效指令
source /etc/profile九、安装IDEA
- 代码调试基本在主节点进行,故只需在主节点安装IDEA即可,安装指令如下
cd /opt/app
basd ./IDEA-2018.1.1.tar.gz- 配置环境变量
打开环境变量文件
在环境变量文件中加入如下语句:# vim /etc/profileexport IDEA_HOME=/opt/app/IDEA export PATH=$IDEA_HOME/bin:$PATH - 打开idea指令
任意环境输入:# idea.sh
至此,一个可应用于实际开发的hadoop,spark分布式平台搭建成功。