已编译好的hadoop2.7.5(支持snappy)的安装包:
服务器环境为腾讯云-Centos6.8,安装hadoop单机模式,root用户下安装
注:hostname千万不要包含下划线 单机配置localhost
1. 配置主机名
腾讯云不建议修改hostname,因腾讯云服务器默认hostname带有下划线则使用localhost。
2. 配置主机名和ip映射关系 hosts
vim /etc/hosts
#注释127.0.0.1 hostname
ip hostname

3. 关闭防火墙
service iptables stop
chkconfig iptables off4. 配置SSH免密码登录
使用 ssh-keygen 命令生成公钥和私钥,这里要注意的是可以对私钥进行加密保护以增强安全性。
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
上传到服务器
scp -r ~/.ssh/id_dsa.pub $hostname:/root/
目标机器将上传的公钥添加到自己的信任列表
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
5. 安装依赖库
yum -y install svn ncurses-devel gcc*
yum -y install lzo-devel zlib-devel autoconf automake libtool cmake openssl-devel6. 配置maven环境
7. 安装protocolbuf
7.1 下载安装包
下载地址: https://github.com/google/protobuf/releases/tag/v2.5.0
wget https://github.com/google/protobuf/releases/download/v2.5.0/protobuf-2.5.0.tar.gz7.2 解压
tar -zxvf protobuf-2.5.0.tar.gz
cd protobuf-2.5.07.3 安装
(1)./configure --prefix=/usr/local/protobuf
(2)make
(3)make check
(4)make install
2-4步用一个命令代替 make && make check && make install
7.4 设置环境变量
vim /etc/profile
#protoc setting
export PROTOC_HOME=/usr/local/protobuf
export PATH=$PATH:$PROTOC_HOME/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$PROTOC_HOME/lib
#刷新环境变量
source /etc/profile
7.5. 软链接
ln -s /usr/local/protobuf/bin/protoc /usr/bin/protoc
输入 protoc --version 有下面输出结果则安装并配置正确

8. 安装findbugs
8.1 下载安装包
下载地址:https://sourceforge.net/projects/findbugs/files/findbugs/
wget https://jaist.dl.sourceforge.net/project/findbugs/findbugs/1.3.9/findbugs-1.3.9.tar.gz
8.2 解压缩
tar -zxvf findbugs-1.3.9.tar.gz -C /usr/local/
8.3 配置环境变量
vim /etc/profile
#findbugs settings
export FINDBUGS_HOME=/usr/local/findbugs-1.3.9
export PATH=$PATH:$FINDBUGS_HOME/bin
#刷新环境变量
source /etc/profile
输入findbugs -version,有下面输出结果则安装并配置正确。

9. 安装 ant
yum -y install ant
ant -version
10. 编译安装snappy
# 用root用户执行以下命令
10.1 下载安装包
wget http://pkgs.fedoraproject.org/repo/pkgs/snappy/snappy-1.1.1.tar.gz/8887e3b7253b22a31f5486bca3cbc1c2/snappy-1.1.1.tar.gz10.2 解压
tar -zxvf snappy-1.1.1.tar.gz10.3 安装
cd snappy-1.1.1/
./configure
make && make install
# 查看snappy库文件
ls -lh /usr/local/lib |grep snappy

11. 编译Hadoop
11.1 下载源码包
wget http://archive.apache.org/dist/hadoop/common/hadoop-2.7.5/hadoop-2.7.5-src.tar.gz11.2 解压
tar -zxvf hadoop-2.7.5-src.tar.gz
cd hadoop-2.7.5-src/
mvn clean package -DskipTests -Pdist,native -Dtar -Dsnappy.lib=/usr/local/lib -Dbundle.snappy
执行成功后,hadoop-dist/target/hadoop-2.7.5.tar.gz即为新生成的二进制安装包。
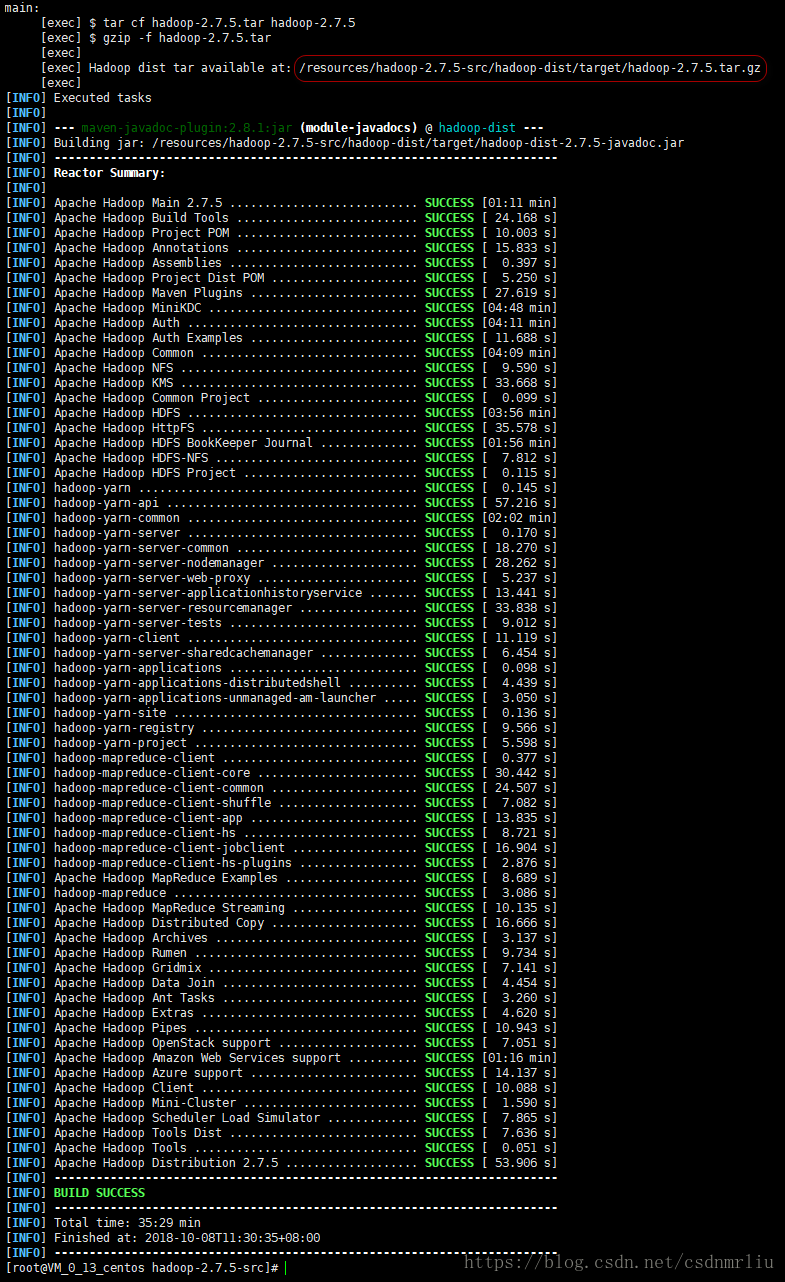
12. 编译hadoop-snappy(可选,在安装hadoop后支持snappy库时进行这一步)
已编译好的包下载链接:https://pan.baidu.com/s/1-8vTwkIVOrXeL8xOp1O6nA 密码:5slj
12.1 下载源码包
git clone https://github.com/electrum/hadoop-snappy.git12.2 编译
mvn package -Dsnappy.prefix=/usr/local

13. 安装Hadoop
13.1 解压缩编译好的hadoop包
tar -zxvf hadoop-2.7.5-snappy.tar.gz -C /usr/local/13.2 将编译好的hadoop-snappy动态库复制到$HADOOP_HOME/lib/native/ 目录下
(若不是源码编译hadoop支持snappy时,执行这一步操作)
cp /resources/hadoop-snappy/target/hadoop-snappy-0.0.1-SNAPSHOT-tar/hadoop-snappy-0.0.1-SNAPSHOT/lib/native/Linux-amd64-64/* /usr/local/hadoop-2.7.5/lib/native/13.3 配置环境变量
vim /etc/profile
#追加下面配置
#hadoop stand-alone settings
export HADOOP_HOME=/usr/local/hadoop-2.7.5
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
export PATH=$PATH:$HADOOP_HOME/bin
#刷新环境变量
source /etc/profile13.4 配置hadoop(配置文件在$HADOOP_HOME/etc/hadoop目录下)
13.4.1 hadoop-env.sh
#配置JAVA_HOME
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/local/jdk1.8.0_131
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native/
export HADOOP_LOG_DIR=/data/hadoop/logs/standalone
export YARN_LOG_DIR=$HADOOP_LOG_DIR
export HADOOP_MAPRED_LOG_DIR=$HADOOP_LOG_DIR13.4.2 core-site.xml
<!-- 用来指定hdfs的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!-- 用来指定Hadoop运行时产生文件的存放目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec
</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>localhost</value>
</property>
13.4.3 hdfs-site.xml
<!-- 指定HDFS保存数据副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- namenode上存储hdfs名字空间元数据 -->
<property>
<name>dfs.name.dir</name>
<value>/data/hadoop/namenode</value>
</property>
<!-- datanode上数据块的物理存储位置 -->
<property>
<name>dfs.data.dir</name>
<value>/data/hadoop/datanode</value>
</property>
<!-- 用于免密登录 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- 默认为true,namenode连接datanode时,会进行host解析查询 -->
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>localhost</value>
<description>localhost对应DataNode所在服务器主机名,可配置多个,用逗号隔开</description>
</property>13.4.4 mapred-site.xml
mv mapred-site.xml.template mapred-site.xml替换配置文件中的hostname, vi mapred-site.xml
:1,$s/mace/$hostname/g <property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
<!-- 告诉hadoop以后MR运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>localhost:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>localhost:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>${yarn.app.mapreduce.am.staging-dir}/history/done</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate</value>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/tmp/hadoop-yarn/staging</value>
</property>
13.4.5 slaves
配置hostname,单机为一个(localhost),集群为多行

13.4.6 yarn-site.xml
<!-- NodeManager获取数据的方式是shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志信息保存在文件系统上的最长时间(一周) 秒为单位-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 应用程序完成之后 NodeManager 的 DeletionService 删除应用程序的本地化文件和日志目录之前的时间(秒数)。要诊断 YARN 应用程序问题,请将此属性的值设为足够大(例如,设为 600 秒,即 10 分钟)以允许检查这些目录 -->
<property>
<name>yarn.nodemanager.delete.debug-delay-sec</name>
<value>604800</value>
</property>
<!-- 日志聚合目录 -->
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/var/log/hadoop-yarn/apps</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/hadoop/logs/yar/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/hadoop/logs/yar/log</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://localhost:19888/jobhistory/logs</value>
</property>
<!-- 是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true。 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
13.4.7 yarn-env.sh
vim yarn-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_172
13.4 格式化namenode
cd /usr/local/hadoop-2.7.5
./bin/hdfs namenode -format
13.5 验证是否安装成功
hadoop version
hadoop checknative -a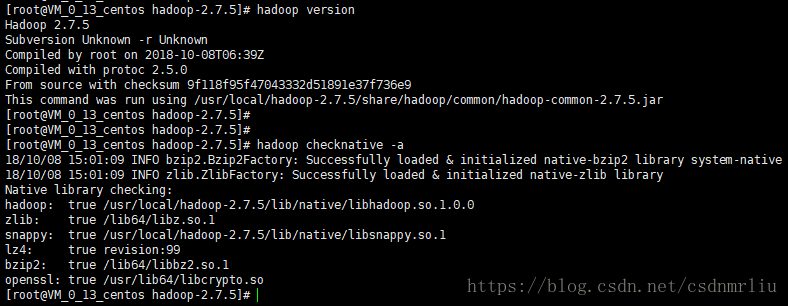
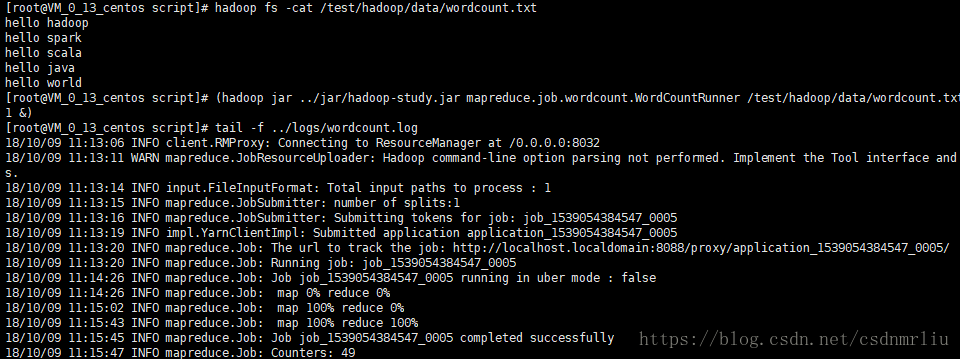
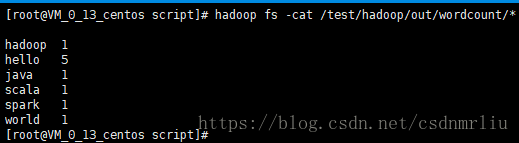
14. 启动与停止HDFS服务
#进入hadoop安装目录
cd $HADOOP_HOME
#启动
./sbin/start-dfs.sh
#停止
./sbin/stop-dfs.sh
15. 启动与停止yarn服务
#进入hadoop安装目录
cd $HADOOP_HOME
#启动
./sbin/start-yarn.sh
#停止
./sbin/stop-yarn.sh
16. 启动与停止jobhistory服务
#进入hadoop安装目录
cd $HADOOP_HOME
#启动
./sbin/mr-jobhistory-daemon.sh start historyserver
#停止
./sbin/mr-jobhistory-daemon.sh stop historyserver

hadoop dfsadmin -report
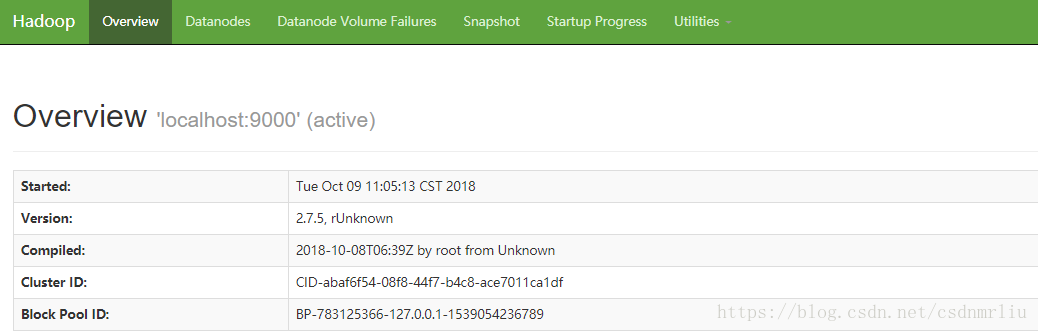
17. UI界面
yarn http://ip:8088/cluster/cluster
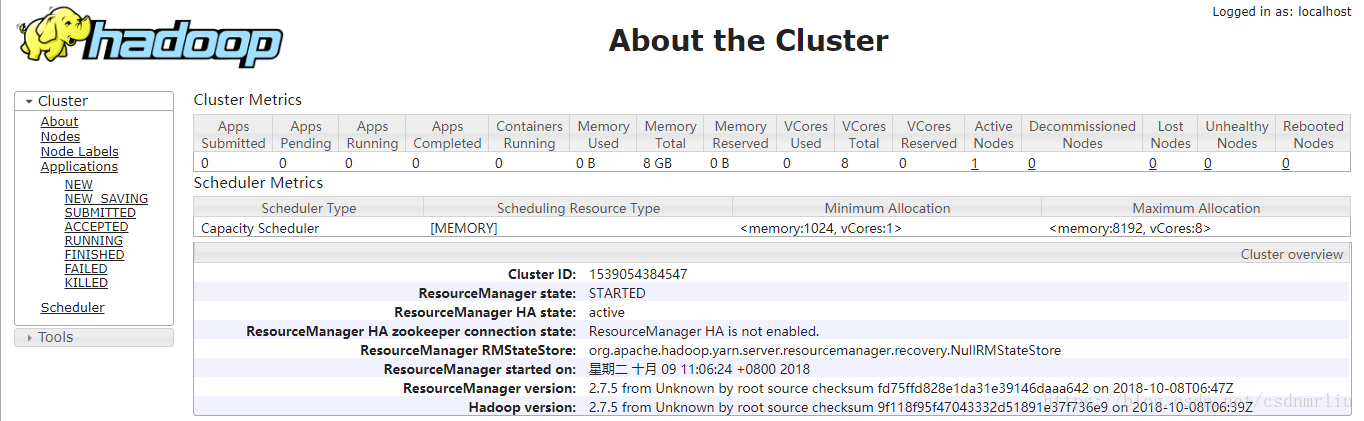
namenode http://ip:50070