版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/apollo_miracle/article/details/88799526
学习目标
- 应用PCA实现特征的降维
- 应用:用户与物品类别之间主成分分析
1 什么是主成分分析(PCA)
-
定义:高维数据转化为低维数据的过程,在此过程中可能会舍弃原有数据、创造新的变量
-
作用:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息。
- 应用:回归分析或者聚类分析当中
那么更好的理解这个过程呢?我们来看一张图

1.1 计算案例理解(了解,无需记忆)
假设对于给定5个点,数据如下
(-1,-2)
(-1, 0)
( 0, 0)
( 2, 1)
( 0, 1)
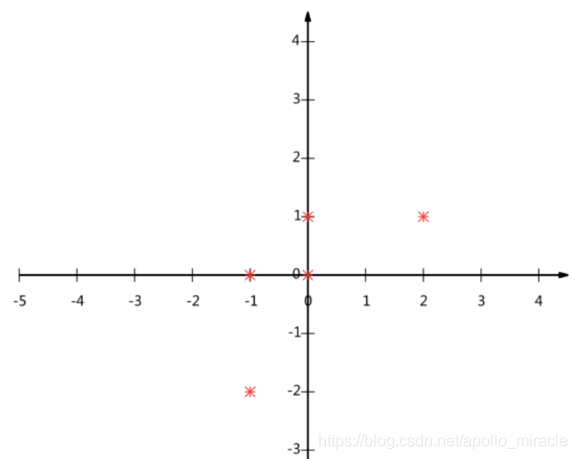
要求:将这个二维的数据简化成一维? 并且损失少量的信息
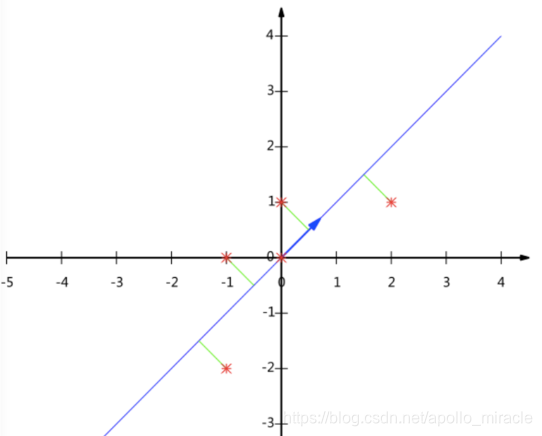
这个过程如何计算的呢?找到一个合适的直线,通过一个矩阵运算得出主成分分析的结果(不需要理解)

1.2 API
- sklearn.decomposition.PCA(n_components=None)
- 将数据分解为较低维数空间
- n_components:
- 小数:表示保留百分之多少的信息
- 整数:减少到多少特征
- PCA.fit_transform(X) X:numpy array格式的数据[n_samples,n_features]
- 返回值:转换后指定维度的array
1.3 数据计算
先拿个简单的数据计算一下
扫描二维码关注公众号,回复:
5768428 查看本文章

[[2,8,4,5],
[6,3,0,8],
[5,4,9,1]]
def pca():
"""
主成分分析进行降维
:return:
"""
# 信息保留70%
pca = PCA(n_components=0.7)
data = pca.fit_transform([[2,8,4,5],[6,3,0,8],[5,4,9,1]])
print(data)
return None
2 案例:探究用户对物品类别的喜好细分降维
数据如下:
-
order_products__prior.csv:订单与商品信息
- 字段:order_id, product_id, add_to_cart_order, reordered
-
products.csv:商品信息
- 字段:product_id, product_name, aisle_id, department_id
- orders.csv:用户的订单信息
- 字段:order_id,user_id,eval_set,order_number,….
- aisles.csv:商品所属具体物品类别
- 字段: aisle_id, aisle
2.1 需求

2.2 分析
- 合并表,使得user_id与aisle在一张表当中
- 进行交叉表变换
- 进行降维
2.3 完整代码
# 去读四张表的数据
prior = pd.read_csv("./data/instacart/order_products__prior.csv")
products = pd.read_csv("./data/instacart/products.csv")
orders = pd.read_csv("./data/instacart/orders.csv")
aisles = pd.read_csv("./data/instacart/aisles.csv")
# 合并四张表
mt = pd.merge(prior, products, on=['product_id', 'product_id'])
mt1 = pd.merge(mt, orders, on=['order_id', 'order_id'])
mt2 = pd.merge(mt1, aisles, on=['aisle_id', 'aisle_id'])
# pd.crosstab 统计用户与物品之间的次数关系(统计次数)
cross = pd.crosstab(mt2['user_id'], mt2['aisle'])
# PCA进行主成分分析
pc = PCA(n_components=0.95)
data = pc.fit_transform(cross)