看了好多资料,都扯犊子,总结如下:
首先考虑一个问题:对于正交属性空间中的样本点,如何用一个超平面(直线的高维推广)对所有样本进行恰当的表达?
可以想到,若存在这样的超平面,那么它大概具有这样的性质:
1两大依据
最大可分性:样本点在这个超平面上的投影能尽可能的分开
希望将这 m个数据的维度从 n维降到 n` 维,希望这 m 个 n` 维的数据集尽可能的代表原始数据集。
最近重构性:样本点到这个超平面的距离足够近
2..基变换
一般来说,欲获得原始数据新的表示空间,最简单的是对原始数据进行线性变换(基变换):
其中 Y是样本在新空间的表达, P 是基向量, X是原始样本。我们可知选择不同的基可以对一组数据给出不同的表示,同时当基的数量少于原始样本本身的维数则可达到降维的效果,矩阵表示如下:
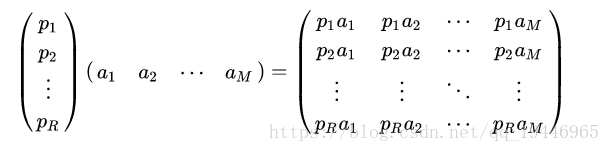
3.方差
我们将所有的点分别向两条直线做投影,基于前面PCA最大可分思想,我们要找的方向是降维后损失最小,可以理解为投影后的数据尽可能的分开,那么这种分散程度可以用数学上的方差来表示,方差越大数据越分散。
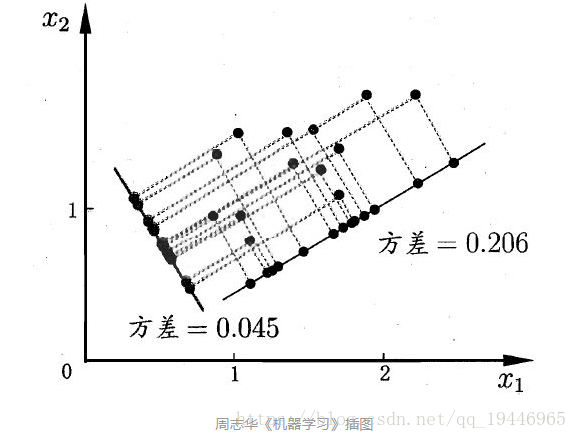
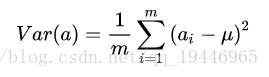
已经知道了以下几点:
- 对原始样本进行(线性变换)基变换可以对原始样本给出不同的表示
- 基的维度小于数据的维度可以起到降维的效果
- 对基变换后新的样本求其方差,选取使其方差最大的基
4.协方差
希望两个字段尽可能表示更多的信息,使其不存在相关性。数学上用协方差表示其相关性:

当等于0时,表示两个字段完全独立,这也是我们的优化目标。
5.协方差矩阵
我们想达到的目标与字段内方差及字段间协方差有密切关系,假如只有 a、 b两个字段,那么我们将它们按行组成矩阵 X ,表示如下:
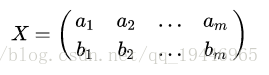
然后我们用 X 乘以 X的转置,并乘上系数 1/m :
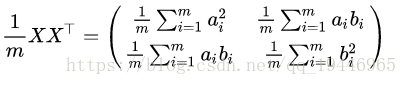
协方差矩阵是一个对称的矩阵,而且对角线是各个维度的方差,而其它元素是 a和b 的协方差,然后会发现两者被统一到了一个矩阵的。
6.协方差矩阵对角化
设原始数据矩阵 X 对应的协方差矩阵为 C ,而 P 是一组基按行组成的矩阵,设
,则 Y为 X 对 P 做基变换后的数据。设 Y 的协方差矩阵为 D ,我们推导一下 D 与 C 的关系:
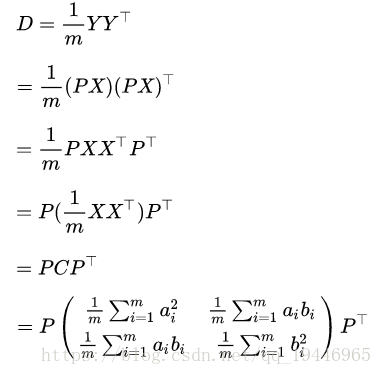
可见,我们要找的 P 不是别的,而是能让原始协方差矩阵对角化的 P 。换句话说,优化目标变成了寻找一个矩阵 P ,满足PCPT
是一个对角矩阵,并且对角元素按从大到小依次排列,那么 P 的前 K 行就是要寻找的基,用 P的前 K 行组成的矩阵乘以X就使得 X 从 N维降到了K 维并满足上述优化条件。
我们希望的是投影后的方差最大化,于是我们的优化目标可以写为:
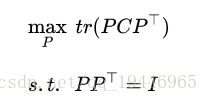
利用拉格朗日函数可以得到:
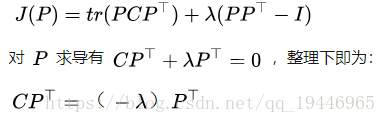
于是,只需对协方差矩阵 C进行特征分解,对求得的特征值进行排序,再对
取前 K列组成的矩阵乘以原始数据矩阵X,就得到了我们需要的降维后的数据矩阵Y。
7.PCA算法流程
输入: n 维样本集X=(x1,x2,..,xm) ,要降维到的维数 n`
输出:降维后的样本集 Y
1.对所有的样本进行中心化
2.计算样本的协方差矩阵
3.求出协方差矩阵的特征值及对应的特征向量
4.将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P
5.Y=PX即为降维到k维后的数据
注意:
有时候,我们不指定降维后的 n` 的值,而是换种方式,指定一个降维到的主成分比重阈值 t 。这个阈值t在 (0,1] 之间。
8.PCA优缺点
PCA算法的主要优点有:
- 仅仅需要以方差衡量信息量,不受数据集以外的因素影响。
- 各主成分之间正交,可消除原始数据成分间的相互影响的因素。
- 计算方法简单,主要运算是特征值分解,易于实现。
PCA算法的主要缺点有:
- 主成分各个特征维度的含义具有一定的模糊性,不如原始样本特征的解释性强。
- 方差小的非主成分也可能含有对样本差异的重要信息,因降维丢弃可能对后续数据处理有影响。
原文地址: https://zhuanlan.zhihu.com/p/32412043

奇异值分解(SVD)原理 - CSDN博客 :https://blog.csdn.net/qq_19446965/article/details/82078313