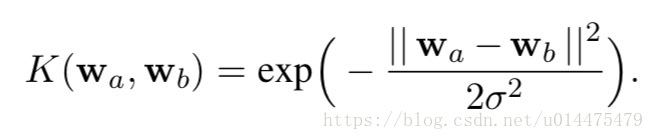原文链接
本文发表于自然语言处理领域顶级会议 ACL 2018
摘要
通用的词语embedding是在大规模语料下训练出来的具有通用性的特点,但在特定领域表现欠佳,而特定领域的词语embedding仅在特定领域能够使用,欠缺通用性。本文提出了一种兼具通用性和领域性的词语embedding方式,实验效果不错。
模型
设矩阵
的每一列都是特定领域的词语的embedding向量,令
为
中词语
的embedding,其中
是该领域词语的集合,
是词向量的维度。类似的,我们设
为通用词语向量组成的矩阵。设
, 令
为
中词语
的embedding。令
和
分别为
和
的映射矩阵,我们进行如下映射:
这样我们就可以通过去使 与 相关度最大,从而列式计算出 和 来,本文把这种操作称之为CCA,公式如下所示:
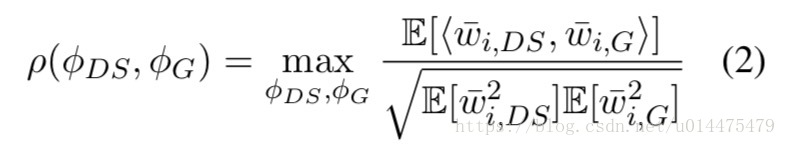
其中 为 和 的相关度, 为 中所有单词的期望。
第
个维度的CCA可以被递归地求出来:假设我们已经求出来了前
个维度,那么第
个维度可以通过求解使相关函数最大的变量来得出(约束条件为第
个维度与前
个维度不相关),设
和
为
和
中向量的映射的集合,其中
单词的最终embedding表示由
得出,其中
和
通过解如下优化问题得出:
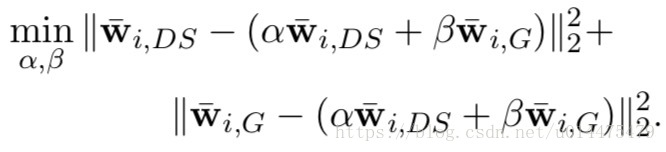
解得
,于是我们得出:
由于 和 ,这是一个线性的关系,这样一来公式(2)就可能就无法求得最佳的 和 ,因为 和 以及 和 可能不是一个简单的线性关系。
为了避免这种情况,本文使用核函数将最初的输入数据映射到高维空间之后再采用CCA方法求解,本文采用的核函数为: