一、优先级队列
我们前面讲过,队列最大的特性就是先进先出。不过,在优先级队列中,数据的出队顺序不是先进先出,而是按照优先级来,优先级最高的,最先出队。
一个堆就可以看做一个优先级队列。很多时候,它们只是概念上的区分而已。往优先级队列中插入一个元素,就相当与往堆中插入一个元素,从优先级队列中取出优先级最高的元素,就相当于取出堆顶元素。
1.合并有序小文件
假设我们有100个文件,每个文件的大小是100M,每个文件中存储的都是有序的字符串。我们希望将这些100个小文件合并成以一个有序的大文件。这里就会用到优先级队列。
思路就跟我们之前合并数组的操作一样,我们从这100个文件中,各取第一个字符串,放入数组中,然后比较大小,把最小的那个字符串放入合并后的大文件中,并从数组中删除。
假设,这个最小的字符串来自于13.txt这个小文件,我们就再从这个小文件取下一个字符串,并且放到数组中,重新比较大小,并且选择最小的放入合并后的大文件,并且将它从数组中删除。依次类推,直到所有文件中的数据都放入到大文件为止。
如果我们单单使用数组这种结构,那每一次都需要循环遍历整个数组,才能取出最小字符(或者维护一个有序的数组,然后每次都把下一个字符串插入到合适的位置,时间复杂度是O(n))。那么,这个时候就可以使用优先级队列,也就是堆。我们把取出来的字符串维护一个小堆顶,堆顶的元素就是优先级队列的队首元素,就是最小的字符串。我们将这个字符串放入大文件中,并将其从堆中删除,然后再下一个小文件取出下一个字符串,放入到堆中,循环这个过程就行。
这里使用堆这种数据结构,插入和删除操作的时间复杂度是O(logn),就变得比较高效。
2.高性能定时器
假设我们有一个定时器,定时器中维护了很多的定时任务,每个任务都设定了一个要触发执行的时间点。定时器每过一个很小的单位时间(比如1秒),就扫描一遍任务,看是否有任务到达设定的执行时间。如果到达了,就拿出来执行。

对于这个需求,我们的第一感觉就是可以把任务按照时间排序,把最早的放在首位,然后与当前的时间点相减得到一个时间间隔T,这样定时器就可以设定在T秒之后,再来执行任务。但是如果这个时候,你有新的任务要加入,我们要找到这个数据在数组中合适的位置,就需要遍历这数组。时间复杂度是O(n)。如果我们使用堆来实现就不一样了,我们维护一个最小堆顶,然后取第一个元素与当前时间点相减,得到T。这个时候,如果有新加入的任务,那么插入一个数据的时间复杂度是O(logn),就比当当使用数组要快了。
二、利用堆求 TopK
我们把这种求top k 的问题抽象成两类。一类是针对静态数据集合,另一类是针对动态数据集合。
针对静态数据,如何在一个包含n个数据的数组中,查找前K大数据呢?我们可以维护一个大小为K的小顶堆顺序遍历数组,从数组中国取出数据与堆顶元素比较。如果比堆顶元素大,我们就把堆顶元素删除,并且将这个元素插入到堆中;如果比堆顶元素小,则不做处理。等数组遍历完成,堆中的数据就是前K大数据了。
遍历数组要O(n)的时间复杂度,每一次堆化的操作需要O(logK)的时间复杂度,所以最坏情况下,n个元素都入堆一次,所以时间复杂度就是O(nlogK)。
针对动态数据,如果每次询问前K大数据,我们都基于当前的数据重新计算的话,那每一次都是O(nlogK),显然不合理。实际上,我们可以一直维护一个K大小的小顶堆,当有数据被添加到集合中时,我们就拿它与堆顶的元素对比。如果比堆顶元素大,我们就把堆顶元素删除,并且将这个元素插入到堆中;如果比堆顶元素小,就不做处理。这样就不用每次都计算一次了。
三、利用堆求中位数
对于一组静态数据,中位数是固定的,我们可以先排序,第n/2个数据就是中位数。每次询问中位数的时候,我们直接返回这个固定的值就好了。所以,尽管排序的代价比较大,但是边际成本会很小。但是,如果我们面对的是动态数据的集合,中位数在不停地变动,如果再用先排序的方法,每次查询中位数的时候,都排序,那效率就很低了。
借助堆这种数据结构,我们不用排序,就可以非常高效地实现求中位数操作。
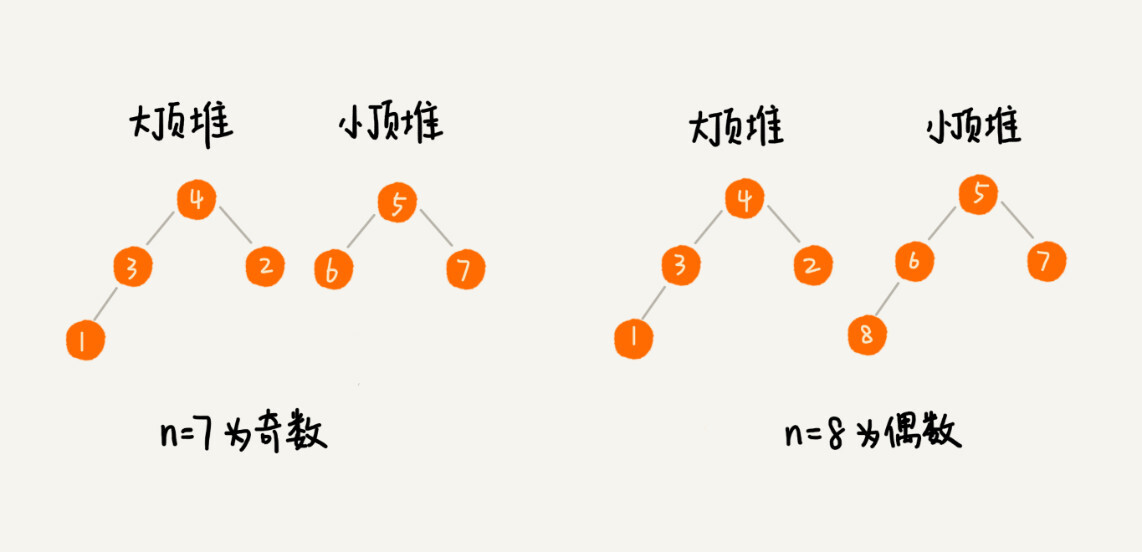
我们需要维护两个堆,一个大顶堆,一个小顶堆。大顶堆中存储前半部分数据,小顶堆中存储后半部分数据,且小顶堆中的数据都大于大顶堆中的数据。
也就是说,如果有n个数据,我们从小到大排序,前n/2个数据储存在大顶堆中,后n/2个数据储存在小顶堆中。这样,大顶堆中的堆顶元素就是我们要找的中位数。如果n是奇数,情况是类似的,大顶堆就储存n/2+1个数据,小顶堆就存储n/2个数据。
那么如果数据是动态的,当新添加一个数据的时候,如果新加入的数据小于等于大顶堆的堆顶元素,我们就将这个新数据插入到大顶堆,如果新加入的数据大于小顶堆的堆顶元素,我们就将这个新数据插入到小顶堆。
这个时候就有可能出现,两个堆中的数据个数不符合前面约定的情况:如果n是偶数,两个堆中的数据个数都是n/2;如果n是奇数,大顶堆有n/2+1 个数据,小顶堆有n/2个数据。这个时候,我们可以从一个堆中不停地将堆顶元素移动到另一个堆,通过这样的调整,来让两个堆中的数据满足上面的约定。
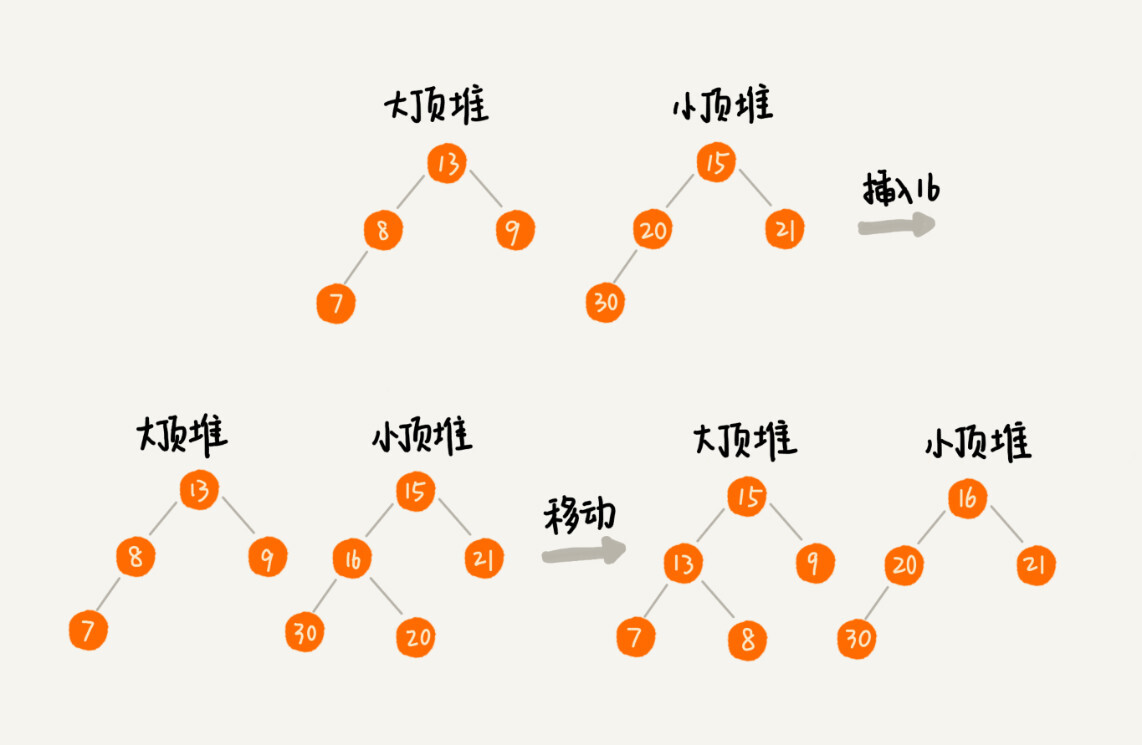
这样,动态数据的插入,求中位数,只涉及堆化的操作,因此时间复杂度是O(logn)。
实际上,推广一下,利用两个堆不仅可以求出中位数,还可以快速取出其他百分位的数据,原理是类似的。假设我们要求99%的时间,我们可以维护两个堆,一个大顶堆,一个小顶堆。假设当前总数据的个数是n,大顶堆中保存n*99%个数据,小顶堆中保存n*1%个数据。大顶堆堆顶的数据就是我们要找的99%的数据。插入数据之后跟前面的中位数是类似的。
思考题
假设我们有一个包含10亿个搜索关键词的日志文件,如何快速获取到Top10最热门的搜索关键词?
如果不考虑内存空间,并且是单机,那么我们可以遍历这10亿个文件以关键词为key,以及搜索次数为value建立散列表。当扫描一个关键词的时候,到散列表查询,如果存在,则次数加1,如果不存在,就插入这个数据。然后,我们维护一个大小为10的小顶堆,遍历散列表,如果数据比堆顶元素大,就删除堆顶元素,将这个数据插入到堆中。直到遍历完散列表。
如果我们现在考虑内存空间,假设单机机器的内存只有1GB,那么假设10亿关键词中不重复的有1亿条,如果每个搜索词平均为50个字节,那这个散列表存储所需要的空间也要5GB,这样就不行了。那么我们怎么办呢?
其实我们可以采用分而治之的思想,我们对这10亿个文件进行分片。具体是这样的:我们创建10个空文件,00,01,02...,我们遍历这10亿个关键词文件,并且通过哈希算法对其求哈希值,最后同10取模,得到的就是这个搜索关键次应该被分到的文件编号。
我们把这10亿个文件分片之后,分别对这10个文件建立散列表,然后维护一个大小为10的堆,最后得到的是10个大小为10的堆。
最后对这10个堆再求一个大小为10的堆,这样就求出10亿文件中Top10的关键词。