如何理解队列?
先进者先出,这就是典型的“队列”。
另外,同栈类似,队列也支持两个操作,入队和出队。
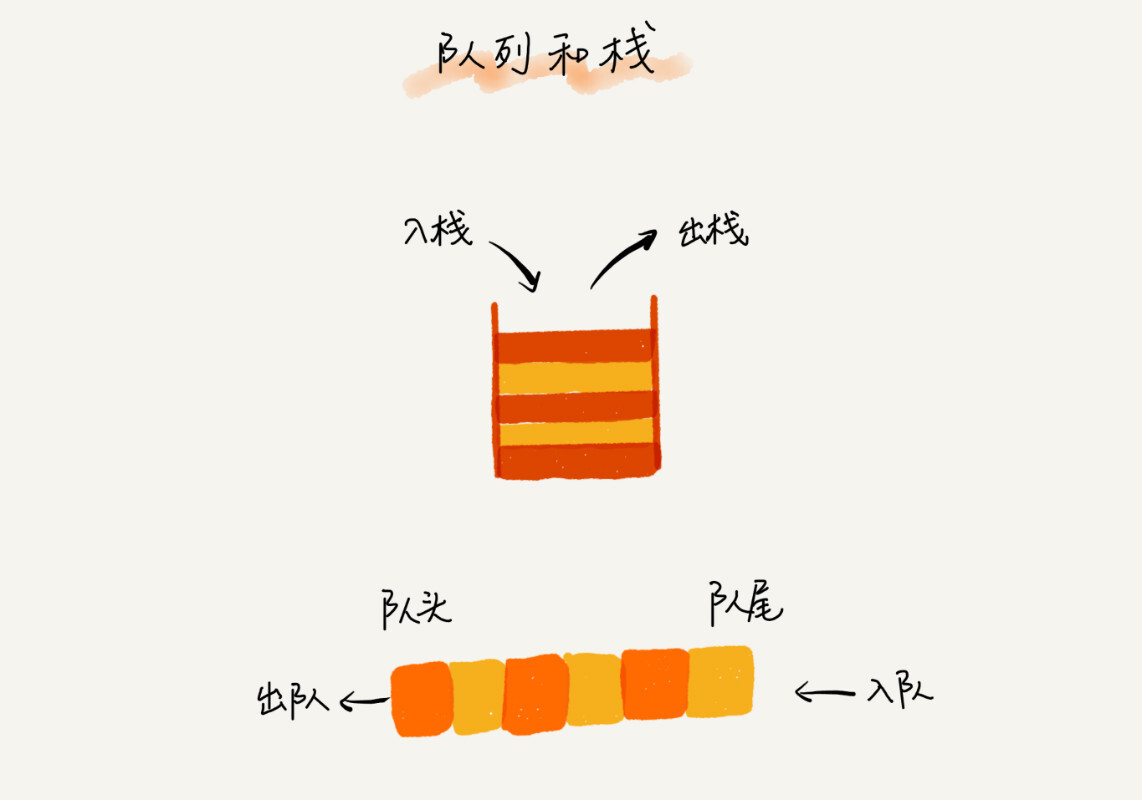
如何实现顺序队列?
我们可以使用数组来实现队列,也可以使用链表来实现队列。对于队列的数组实现,与栈不同,栈只需要一个栈顶指针,队列需要两个指针,一个头指针,一个尾指针。
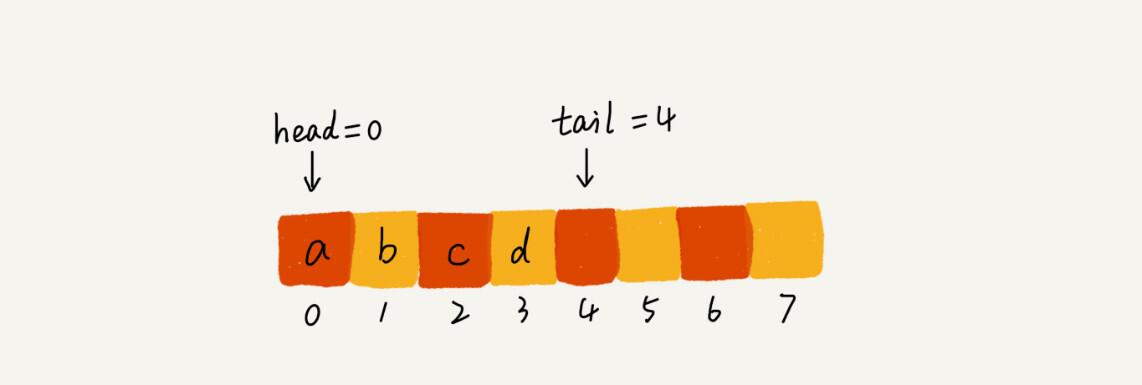
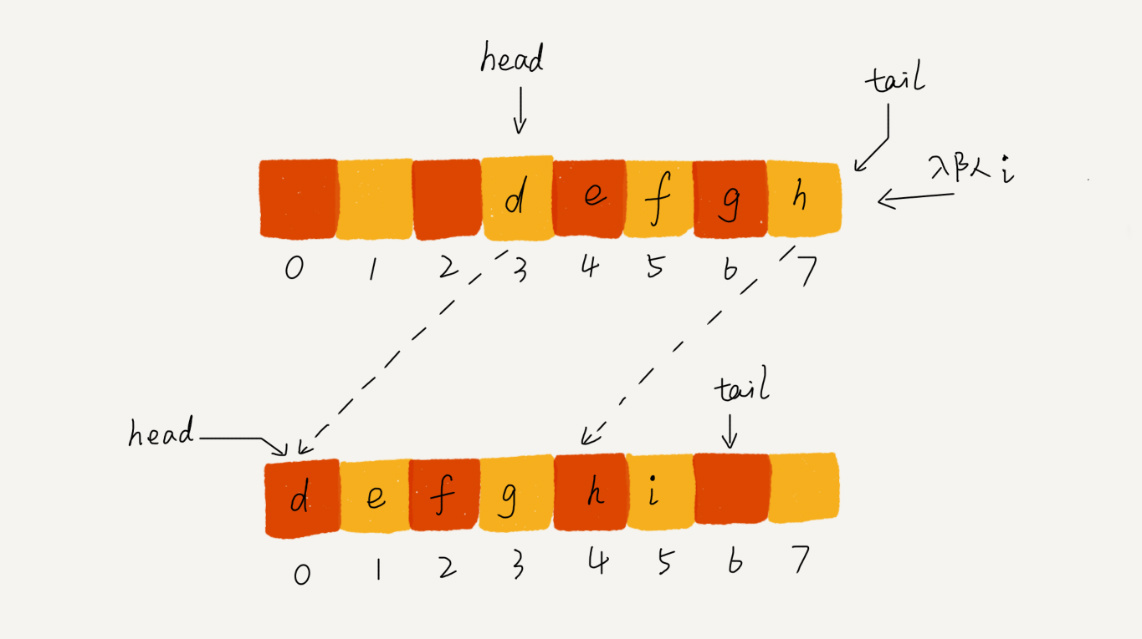
当有数据入队的时候,tail指针就向后移动一位,当有数据出队的时候head指针就向后移动一位。随着不断地入队和出队,你肯定会发现,当tail移动到末尾的时候,即使前面的数组仍然有空间,但这个时候也无法往里面添加数据了。这个时候,我们可以想到用数组的数据搬移。但如果每一次有数据入队就使用数据搬移,那明显时间复杂度就是O(n)。
实际上,我们在出队的时候,如果没有空闲的空间了,我们只需要在入队的时候,再集中触发一次数据搬移的操作。这样的改进出队的时间间复杂度为O(1),入队的平均时间复杂度为:head指针出现在0,1,2....n,的概率都是1/n+1,而每一种情况的时间复杂度是1,n,n-1,.....1,累加起来的平均时间复杂度应该是O(n)。
 这里给出顺序队列的代码实现:
这里给出顺序队列的代码实现:
#include <iostream>
using namespace std;
class queue{
int* arr;
int capacity;
int head;
int tail;
queue(int size){
arr = new int[size];
capacity = size;
head = 0;
tail = 0;
}
void enqueue(int data){
if(tail == capacity){
if(head==0)
{
cout << "队满" << endl;
return;
}else{
for(int i=head;i<tail;++i){
arr[i-head] = arr[i];
}
tail -= head;
head = 0;
}
}
arr[tail] = data;
++tail;
}
int dequeue(){
if(head == tail){
cout << "队空" << endl;
return -1;
}
int data = arr[head];
++head;
return data;
}
};如何实现链式队列?
同数组队列类似,我们同样需要两个指针,head指针和tail指针,他们分别指向链表的第一个结和最后一个结点。
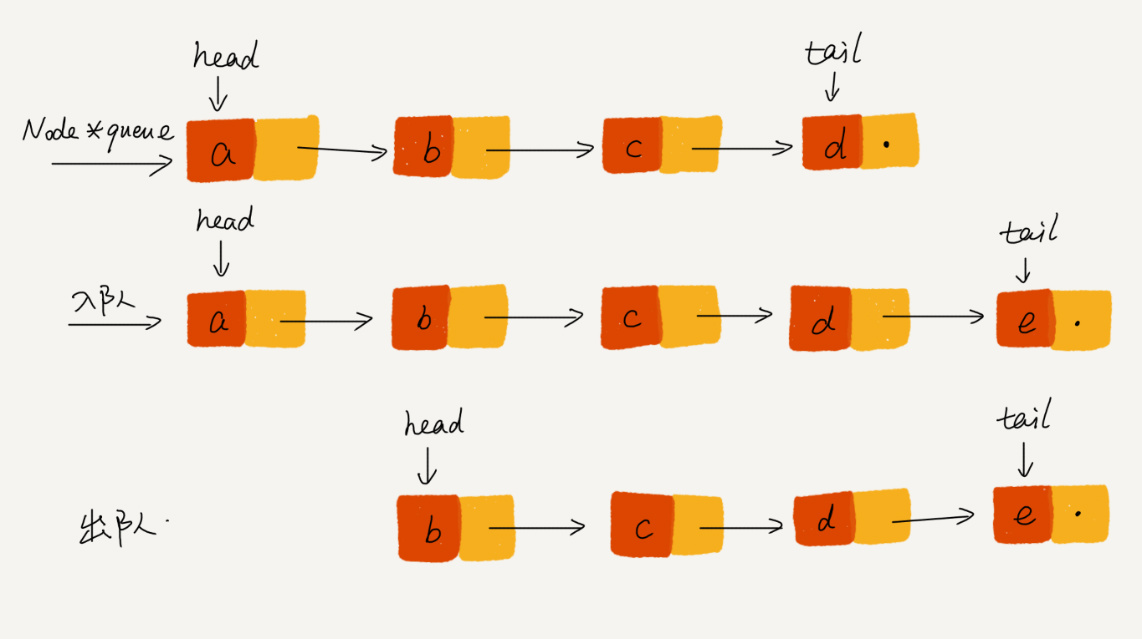 这里直接给出代码的实现:
这里直接给出代码的实现:
typedef struct linkqueue
{
int data;
linkqueue* next;
}linkqueue;
class Linkqueue{
private:
linkqueue* head;
linkqueue* tail;
public:
Linkqueue(){
head = new linkqueue;
tail = head;
}
void enqueue(int data){
// 这里没有使用带头结点的链表
if(tail->data == 0){
tail->data = data;
}else{
linkqueue* p = new linkqueue;
p->data = data;
p->next = NULL;
tail->next = p;
tail = tail->next;
}
}
void dequeue(){
head = head->next;
}
void print(){
linkqueue* start;
for(start=head;start!=tail;start = start->next){
cout << start->data << " " << endl;
}
cout << tail->data << endl;
}
};
如何实现循环队列?
我们刚刚使用数组来实现队列的时候,在tail == capacity的时候,会发生数据的迁移,这样入队的性能就受到的影响。
循环队列,顾名思义,是一个环,我们把首尾进行相连,形成了一个环。
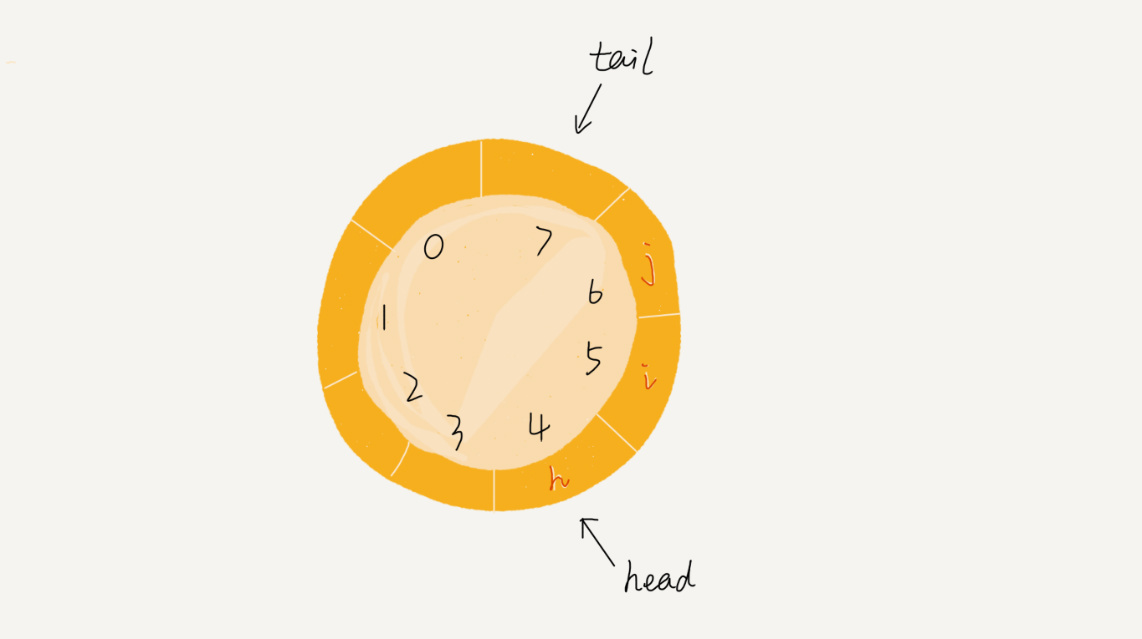
通过这样的方法我们避免了数据的搬移,但是如何确定队空和队满的条件?
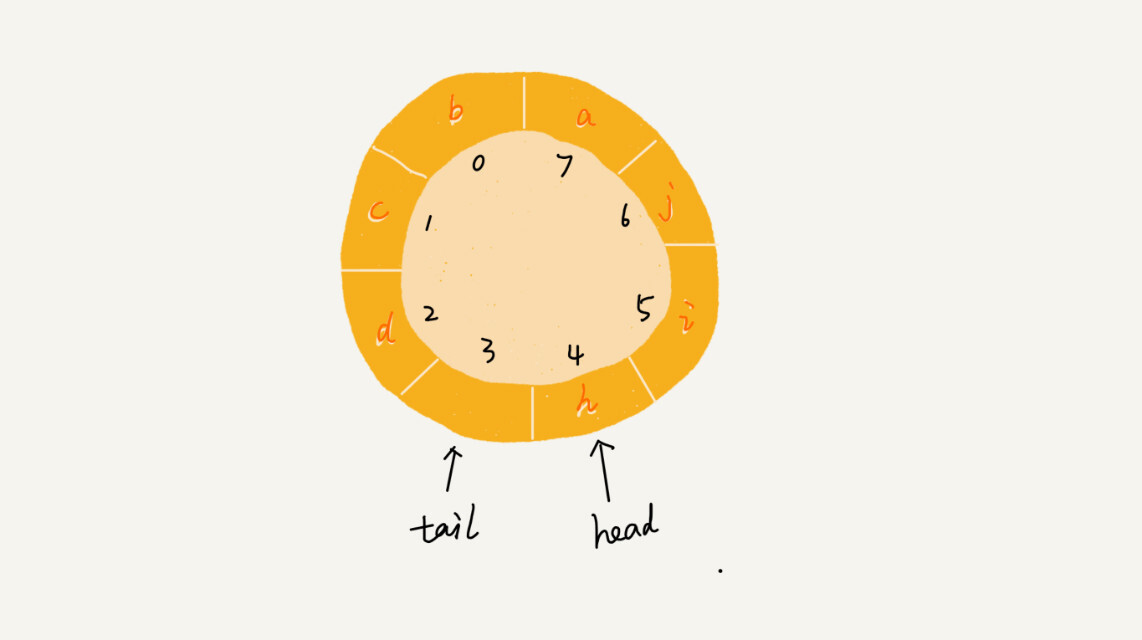
队列为空的判断条件仍然是 head == tail。但队列满的判断条件是(tail + 1)%n = head,实际上,当队满时,图中的tail指向的位置实际上是没有存储数据的,所以,循环队列会浪费一个数组的存储空间。那么访问呢?这里也要注意了,数组是支持随机访问的,但是对于循环队列来说,我们进行访问的时候,比如你想查询最后一个结点的时候,应该这样:arr[tail%n],注意要与循环队列的大小进行取模。
这里给出代码的实现:
class circlequeue{
private:
int* arr;
int capacity;
int head;
int tail;
public:
circlequeue(int size){
arr = new int[size];
capacity = size;
head = 0;
tail = 0;
}
void enqueue(int elem){
if((tail+1) % capacity == head){
cout << "队满" << endl;
return;
}
arr[tail] = elem;
tail = (tail+1)%capacity;
}
int dequeue(){
if(head == tail){
return -1;
}
int elem = arr[head];
head = (head+1) % capacity;
return elem;
}
void print(){
for(int i=head; i!=tail; i = (i+1)%capacity){
cout << arr[i] << " " << endl;
}
}
};阻塞队列
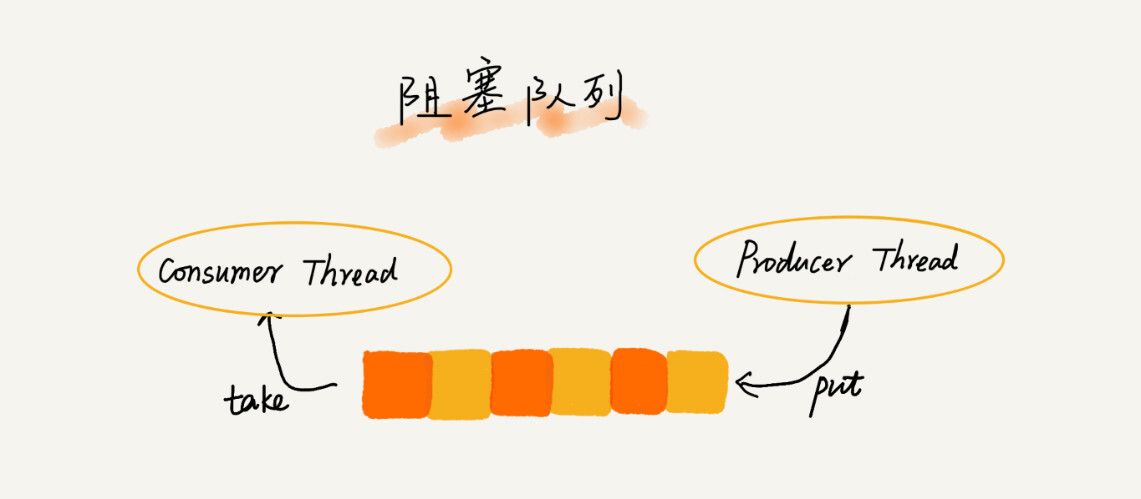
阻塞队列其实就是在队列基础上增加了阻塞操作。简单来说,就是在队列为空的时候,从队头取数据会被阻塞。因为这个时候没有数据可以取,直到队列队列中有数据才可以返回。如果队列的已经满了,那么插入数据的操作就会被阻塞,直到队列中有空闲的位置后再插入数据,然后再返回。
其实这就是一个生产者与消费者的模型,可以有效第协调生产和消费的速度。当生产者产数据的速度过快,“消费者”来不及消费,存储数据的队列很快就会被满了。这个时候,生产者就阻塞等待,直到消费者消费了数据,生产者 才会被唤醒继续生产。
举个实际的例子:在计算机视觉中,我们经常要用摄像头读取图片,读取图片的速度一般来说能够达到帧率。但是如果这个时候,我们处理图片的速度比较快,那么我们就得一直等待图的产生才行。如果我们把读取图片比作生产者,处理图片比作消费者,那么我们用阻塞队列多线程的话,当队列中没有满的时候,图片可以一直读取,这样就节省了处理图片的时间。
队列在线程池等有限资源池的应用
当我们向一个固定大小的线程池中请求一个线程的时候,如果线程池中没有空闲的资源了,这个时候线程池如何处理这个请求?是拒绝请求还是排队请求?各种处理策略又是如何实现的呢?
我们有两种处理的策略。第一种是非阻塞型的处理方式,直接拒绝任务请求;另一种是阻塞型的处理方式,将请求排队,等到有空闲的线程时,取出排队的请求继续处理。那么如何储存排队的请求?
我们希望用一个先进先服务的策略,所以队列就很适合了。这里有两种实现队列的方式,一种是数组,一种是链表。对于链表来说,我们可以实现一个无限长的队列,但是可能会导致过多的请求排队,请求处理的响应时间太长。所以,针对响应时间比较敏感的系统,基于链表实现的队列是不合适的。
而对于数组来说,我们队列的大小有限,所以线程中排队的请求超过队列大小时,接下来的请求就会被拒绝,这种实现方式,响应时间不会很长,但是你需要事先设置一个合理的队列大小。
另外,出啦线程池以外,对于大部分资源有限的场景,当没有空闲资源的时候,基本上都可以通过”队列“这种数据结构事先请求排队。