对于分类模型的评估,除了使用estimator.score()来获取正确分类的百分比,还可以从其他的角度来进行分析,比如:混淆矩阵、精准率、召回率、F1-score等。除此之外,我们调节超参数可以使用网格搜索。
参考:
黑马传智播客机器学习入门视频
本文代码片段基于上篇文章–knn实现鸢尾花分类
目录
1、分类模型的评估
2、交叉验证以及网格搜索
1、分类模型的评估
01 混淆矩阵

from sklearn.metrics import confusion_matrix
c = confusion_matrix(y_test, y_pred, labels=[0, 1, 2])
print(c)
运行结果:
[[11 0 0]
[ 0 12 1]
[ 0 0 6]]
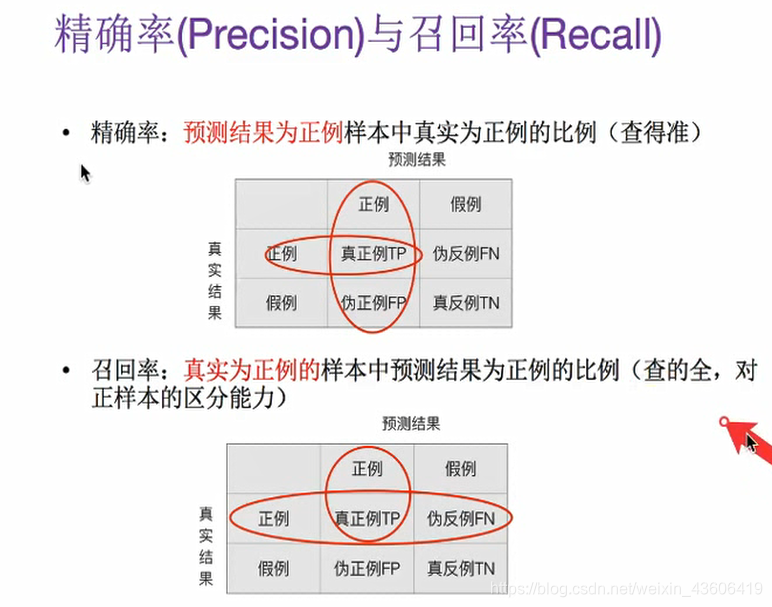
02 精准率(Precision)与召回率(Recall)
03 F1-Score

from sklearn.metrics import classification_report
print("每个类别的精准率与召回率")
print(classification_report(y_test, y_pred, target_names=iris.target_names))
运行结果:
precision recall f1-score support
setosa 1.00 1.00 1.00 11
versicolor 1.00 0.92 0.96 13
virginica 0.86 1.00 0.92 6
avg / total 0.97 0.97 0.97 30
注:可以把混淆矩阵的结果和精准率、召回率结合着分析。
2、交叉验证以及网格搜索
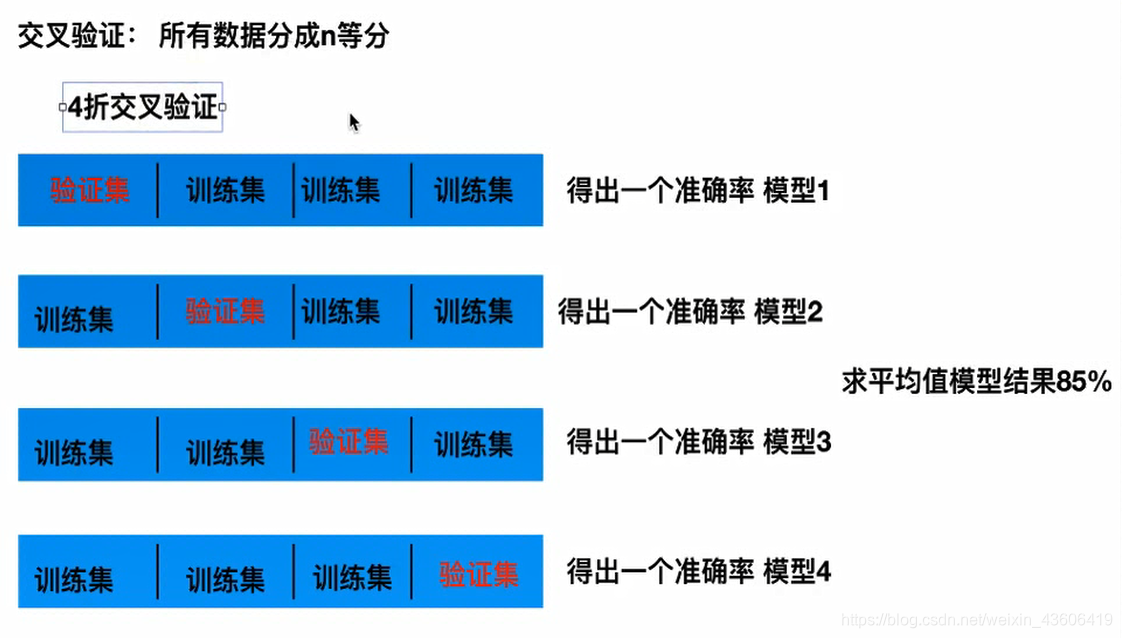
01 交叉验证
02 网格搜索(超参数搜索)

from sklearn.model_selection import GridSearchCV
# 交叉验证以及网格搜索
param = {'n_neighbors': [3, 7, 10]}
cv = GridSearchCV(knn, param_grid=param, cv=2)
cv.fit(x_train, y_train)
print("在测试集上的准确率")
print(cv.score(x_test, y_test))
print("最好的模型")
print(cv.best_estimator_)
print("最好的参数")
print(cv.best_params_)
print("最好的准确率")
print(cv.best_score_)
print("每次交叉验证的结果")
print(cv.cv_results_)