更详细的数据集介绍(有图形分析,应该比较好理解)
https://blog.csdn.net/weixin_42567027/article/details/107416002
数据集
数据集有三个类别,每个类别有50个样本。
ROC曲线与AUC
理论知识
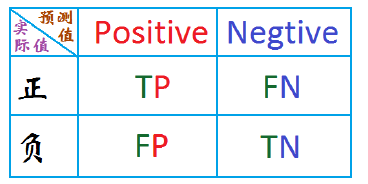
ROC曲线是二值分类问题的一个评价指标。它是一个概率曲线,在不同的阈值下绘制TPR与FPR的关系图,从本质上把“信号”与“噪声”分开。
ROC曲线的x轴是FPR,y轴是TPR。
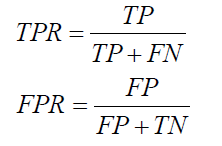
曲线理解
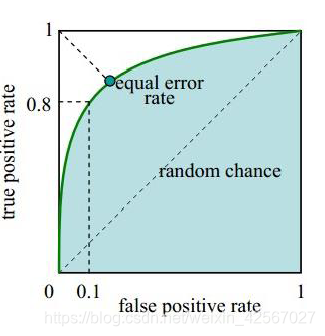
random chance这条直线是随机概率,一半的概率是对的,一半的概率是错的。如果低于这条线,说明算法极差,都不如随机猜的。
因此在这条线的左边说明算法还好点。
然后实际的曲线根据计算得到的FPR,TPR的值得到。
实例计算
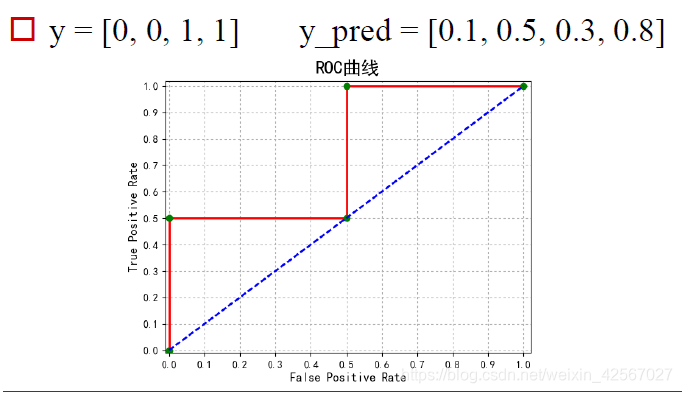
具体计算过程

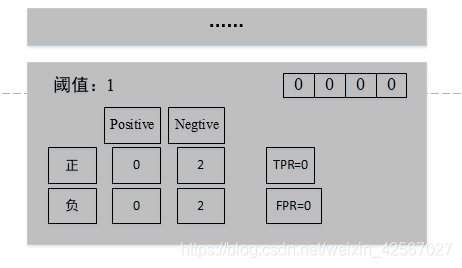
AUC
AUC是分类器区分类的能力的度量,也就是ROC的面积,得出来的就是一个数。
AUC值越大,当前的分类算法越有可能将正样本排在负样本前面,即能够更好的分类。
代码
// An highlighted block
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegressionCV
from sklearn import metrics
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import label_binarize
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
if __name__ == '__main__':
pd.set_option('display.width', 300)
pd.set_option('display.max_columns', 300)
'''加载数据'''
data = pd.read_csv('F:\pythonlianxi\iris.csv', header=None)
#设置列标签
columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'type']
#rename:用于命名文件或目录
data.rename(columns=dict(zip(np.arange(5), columns)), inplace=True)
#Categorical:将类别信息转化成数值信息,因此将type中的数据类型进行转化
data['type'] = pd.Categorical(data['type']).codes
#print (data)
'''数据集和标签集'''
#x存储的是除type类外的数据,也就是数据集
x = data.loc[:, columns[:-1]]
#y中存储的是type数据,也就是标签集
y = data['type']
'''LR分类'''
#训练集和测试集样本
x, x_test, y, y_test = train_test_split(x, y, train_size=0.7)
clf = Pipeline([
#做线性回归预测时候,为了提高模型的泛化能力,经常采用多次线性函数建立模型
#PolynomialFeatures:特征选择 degree:选择线性函数次数
('poly', PolynomialFeatures(degree=2, include_bias=True)),
('lr', LogisticRegressionCV(Cs=np.logspace(-3, 4, 8), cv=5, fit_intercept=False))])
#调参
clf.fit(x, y)
y_hat = clf.predict(x)
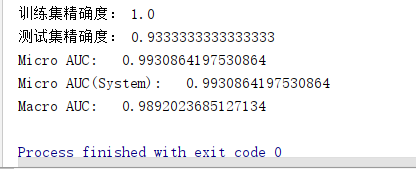
print ('训练集精确度:', metrics.accuracy_score(y, y_hat))
y_test_hat = clf.predict(x_test)
print ('测试集精确度:', metrics.accuracy_score(y_test, y_test_hat))
'''AUC-ROC曲线'''
n_class = len(data['type'].unique())
#y_test:测试集的标签 label_binarize:标签二值化
y_test_one_hot = label_binarize(y_test, classes=np.arange(n_class))
#predict_proba返回的是一个n行k列的数组,
# 第i行第j列上的数值是模型预测第i个预测样本为某个标签的概率,并且每一行的概率和为1。
#测试集分类正确的概率
y_test_one_hot_hat = clf.predict_proba(x_test)
##metrics.roc_curve:计算ROC曲线面积,选取一个阈值计算TPR/FPR
fpr, tpr, thresholds= metrics.roc_curve(y_test_one_hot.ravel(), y_test_one_hot_hat.ravel())
print ('Micro AUC:\t', metrics.auc(fpr, tpr))
print ('Micro AUC(System):\t', metrics.roc_auc_score(y_test_one_hot, y_test_one_hot_hat, average='micro'))
#阈值的选取规则是在scores值中从大到小的以此选取
auc = metrics.roc_auc_score(y_test_one_hot, y_test_one_hot_hat, average='macro')
print( 'Macro AUC:\t', auc)
'''绘图'''
mpl.rcParams['font.sans-serif'] = u'SimHei'
mpl.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(8, 7), dpi=80, facecolor='w')
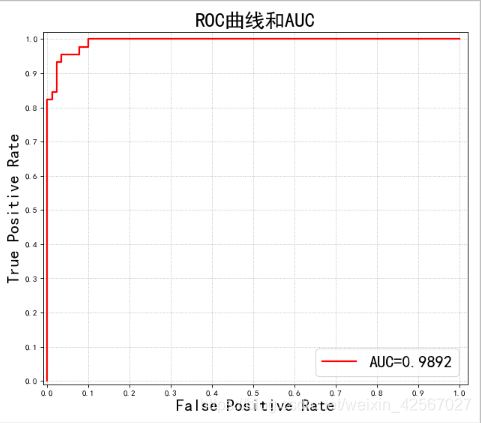
plt.plot(fpr, tpr, 'r-', lw=2, label='AUC=%.4f' % auc)
plt.legend(loc='lower right',fontsize=20)
#对x轴,y轴的坐标值进行限制
plt.xlim((-0.01, 1.02))
plt.ylim((-0.01, 1.02))
plt.xticks(np.arange(0, 1.1, 0.1))
plt.yticks(np.arange(0, 1.1, 0.1))
plt.xlabel('False Positive Rate', fontsize=20)
plt.ylabel('True Positive Rate', fontsize=20)
plt.grid(b=True, ls=':')
plt.title(u'ROC曲线和AUC', fontsize=24)
plt.show()