混淆矩阵
混淆矩阵
| 实际 | 预测 1 | 预测 0 |
|---|---|---|
| 真实值 1 | TP | FN |
| 真实值 0 | FP | TN |
TP = True Postive = 真阳性; FP = False Positive = 假阳性
FN = False Negative = 假阴性; TN = True Negative = 真阴性
引出True Positive Rate(真阳率)、False Positive(伪阳率)两个概念:
TPR = TP / (TP + FN)
FPR = FP / (FP + TN)
TPR的意义是所有真实类别为1的样本中,预测类别为1的比例。
FPR的意义是所有真是类别为0的样本中,预测类别为1的比例。
AUC
AUC是一个模型评价指标,只能用于二分类模型的评价
AUC的本质含义反映的是对于任意一对正负例样本,模型将正样本预测为正例的可能性 大于 将负例预测为正例的可能性的 概率
计算方法: 有TPR和FPR构成的ROC曲线下的面积大小就是auc
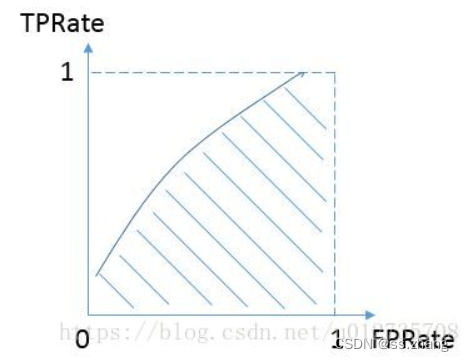
如果希望auc更大,那么在给定TPR的情况下,我们是希望FPR越小越好的,同样给定FPR,希望TPR越大越好,
这样才能给曲线拉向对角线上方。所以我们可以认为:优化auc就是希望同时优化TPR和(1-FPR)。
F1-Score
精度(precision) = TP / (TP + FP)
召回(recall) = TP / (TP + FN)
F1就是希望同时优化recall和precision
F1score = 2∗recall∗precision / (recall + precision)
区别
F1和AUC
这里两个指标在recall之外,其实是存在内在矛盾的。如果说召回率衡量我们训练的模型(制造的一个检验)对既有知识的记忆能力(召回率),
那么两个指标都是希望训练一个能够很好拟合样本数据的模型,这一点上两者目标相同。但是auc在此之外,希望训练一个尽量不误报的模型,
也就是知识外推的时候倾向保守估计,而f1希望训练一个不放过任何可能的模型,即知识外推的时候倾向激进,这就是这两个指标的核心区别。
auc不容易受样本不平衡的影响,所以对于imbalance的情况优先使用auc