混淆矩阵
混淆矩阵(Confusion Matrix)是可视化工具,特别用于监督学习,在无监督学习中一般叫做匹配矩阵,主要用于比较分类结果和实际测得值,可以把分类结果的精度显示在一个混淆矩阵里面。
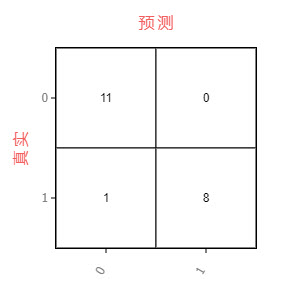
TP的定义:实际为正预测为正
FP的定义:实际为负但预测为正
TN的定义:实际为负预测为负
FN的定义:实际为正但预测为负
召回率(Recall,TNR):预测对的正例数占真正的正例数的比率
计算公式:Recall=TP / (TP+FN)
准确率:反映分类器统对整个样本的判定能力,能将正的判定为正,负的判定为负
计算公式:Accuracy=(TP+TN) / (TP+FP+TN+FN)
精准率:指的是所得数值与真实值之间的精确程度;预测正确的正例数占预测为正例总量的比率
计算公式:Precision=TP / (TP+FP)
F值:F-score是Precision和Recall加权调和平均数,并假设两者一样重要
计算公式:F1 Score=(2RecallPrecision) / (Recall+Precision)

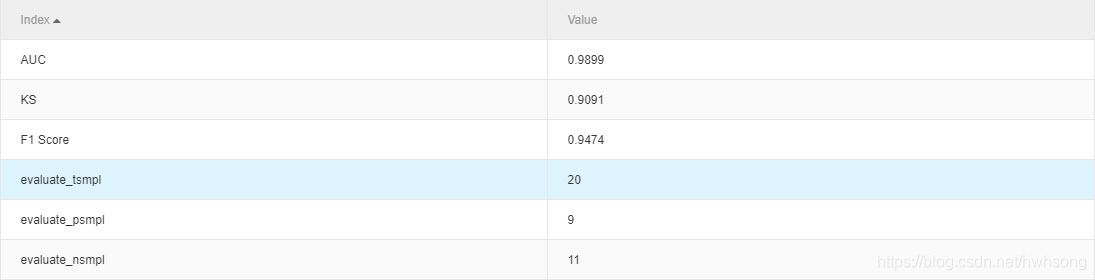
二分类评估
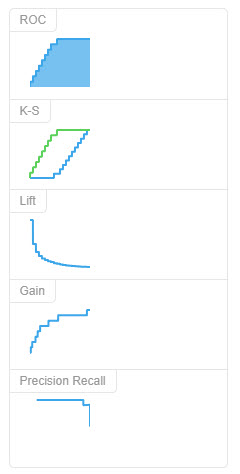
**AUC(Area Under Curve)**被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
AUC值是一个概率值,当你随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值。当然,AUC值越大,当前的分类算法越有可能将正样本排在负样本前面,即能够更好的分类。
KS值,正样本洛伦兹曲线记为f(x),负样本洛伦兹曲线记为g(x),K-S曲线实际上是f(x)与g(x)的差值曲线。K-S曲线的最高点(最大值)定义为KS值,KS值越大,模型分值的区分度越好,KS值为0代表是最没有区分度的随机模型。准确的来说,K-S是用来度量阳性与阴性分类区分程度的。