有信息(启发式)的搜索策略
文章目录
性能评估:
- 完备性
- 最有效
- 复杂性
盲目搜索:
(上节课讲的都是盲目搜索)
缺点:不知道哪个节点离目标最近。
需要一个启发式函数来评估远近。
启发式函数:
= 结点n到目标节点的最小代价路径的代价估计值。
要注意的是 以结点为输入,但它与 不同,它只依赖于结点状态。
路径花费函数:path cost
结点到n的花费
评价函数
:
评价函数被看做是代价估计。
若n 是目标节点,则 .
1 贪婪最佳优先搜索
,也分为图搜索和树搜索
Bucharest问题
= 直线距离

为什么叫做“贪婪的”,因为它的每一步都在试图找到离目标最近的结点。
性能分析
完备性
树搜索:(GBFS tree)
可能会进入死循环,出不来。
在有限空间内和无限空间:不完备
图搜索:(GBFS graph)
不会进入死循环。
有限空间:完备; 无限空间:不完备。
贪婪最佳优先搜索与深度优先搜索类似,即使是有限状态空间,它也是不完备的。
最优性
不能保证最优性
时间和空间复杂度
算法的时间复杂度和空间复杂度都是 ,其中m是搜索空间的最大深度。
?如果想要启发式函数找到最优解,那就一定要把路径代价考虑进去。
2 A*搜索:缩小总评估代价
A*搜索对结点的评估结合了
,即到达此结点已经花费的代价,和
,从该节点到目标节点所花代价:
是从开始结点到结点n 的路径代价。
是从结点n到目标结点的最小代价路径的估计值
因此:
假设启发式函数 满足特定的条件,A搜索既是完备的也是最优的。算法与一致代价搜索类似,除了A使用g+h 而是g。
如果在新展开的结点中,存在已经在frontier中的结点,则比较两个节点,选择 最小的那个。
A*算法的最优性
由于启发函数的设计不当导致找不到最优解。
解决方法:估计值 小于实际的代价值。
如果
是可采纳的,那么A的树搜索版本是最优的。
如果
是一致的,那么图搜索的A算法是最优的。

一致启发式函数 → 可采纳启发式函数
→
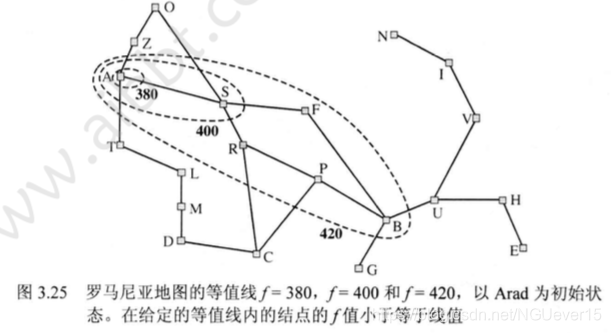
如果 是最优解路径的代价值,可以得到:
- A*算法扩展所有 的结点。
- A*算法在扩展目标结点钱可能会扩展一些正好处于“目标等值线”( )上。
完备性要求代价小于等于C的结点是有穷的,前提条件是每步代价都超过e并且b是有穷的。
A算法对于任何给定的一致的启发式函数都是效率最优的。
如果算法不扩展所有 的结点,那么就很有可能会漏掉最优解。
是从根节点到目标结点的实际代价,相对误差定义为 ,绝对误差定义为 。
h2 比h1占优势(h1 和h2都小于h*,但是h2>h1)
如何获得可采纳的启发式函数?
6 启发式函数
如果想用A*算法找到最短路径解,叫我们需要一个绝不会高估到达目标的步数的启发式函数。
常用的两个启发式函数:
- h1 = 不在位的棋子数。
- h2 = 所有旗子到其目标位置的距离和。
h1是一个可采纳的启发式函数。
计算距离是指水平和竖直的距离和。这有时被称为市街区距离或曼哈顿距离。
h2 也是可采纳的。
松弛问题
减少了行动限制的问题称为 松弛问题。
减少限制导致了图中边的增加。
由于松弛问题增加了状态空间的边,原有问题总的任一最优解同样是松弛问题的最优;
但是松弛问题可能存在更好的解,理由是增加的边可能导致捷径。
所以一个松弛问题的最优解代价是原问题的可采纳的启发式。
定义新的启发式从而从中得到最好的:
子问题
**模式数据库(pattern databases)**的思想:
对每个可能的子问题实例存储解代价。
数据库本身的构造是通过从目标状态向后 搜索并记录下每个遇到的新模式的代价完成的;
搜索的开销分摊到许多的子问题实例上。
两个子问题的代价之和仍然是求解整个问题的代价的下届。
这就是不想交的模式数据库的思想。
