Bayesian Network是一个主要用于分类的网络模型,理论基础是Naive Bayesian Classification,同时也是HMM的前身。
1. Naive Bayesian Classifier
Naive Bayesian基于特征独立的假设,应用Bayes' Theorem进行supervised learning。因为NB的假设too naive,所以名字才叫Naive Bayesian。和其他基于discriminative approach的模型不同,Naive Bayesian是通过学习joint probability distribution预测conditional probability的分类模型,属于generative model,收敛速度比discriminative model更快。
对于给定的特征向量x1,x2,...,xn,类别y的概率可以表示为:

假设特征之间相互独立:
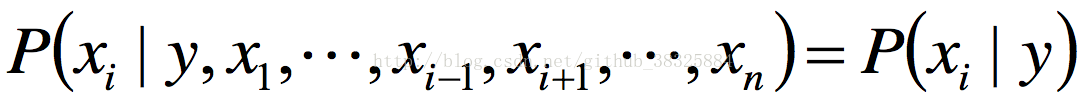
这个假设的目的是对P(x1,x2,...,xn|y)部分化简,这部分本来等于P(x1|y)P(x2,x3,...,xn|y,x1),基于特征独立假设,可以写成
P(x1|y)P(x2,x3,...,xn|y)。然后对所有x都做相同处理,得P(x1|y)P(x2|y)P(x3|y)...P(xn|y)。因此之前的式子可以化简为:
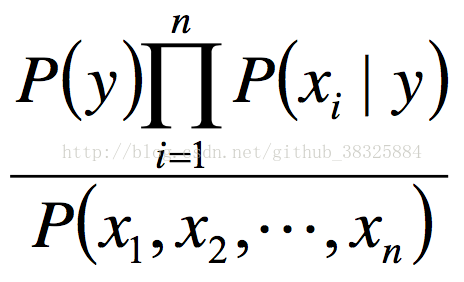
样本给定的前提下,分母部分的P(x1,x2,...,xn)是定值。因此有:
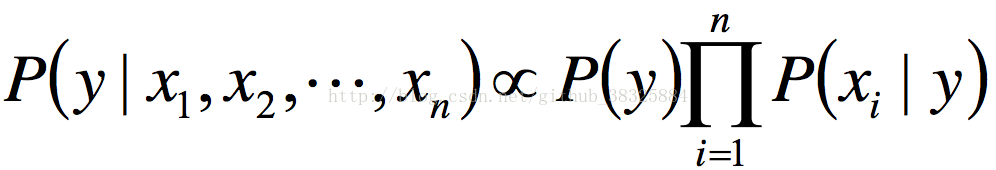
这样可以得到:
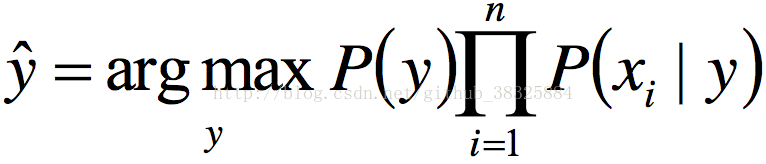
上式就是NB的一般情况公式。对于式子里的P(y),我们可以基于对客观世界的理解做估算出来,比如掷骰子我们认为每一面出现的概率都是1/6,也可以通过对样本求MLE求出来。总之这部分的值实际上应该是个已知量。我们要关注的不是P(y)自身的取值,而是这个值和x之间的关系,也就是P(xi|y)这项。如果我们面对的样本是连续的,我们可以认为模型服从高斯分布,也就是说P(xi|y)这项应该可以找到对应的标准差和期望,那么P(xi|y)的标准差和期望其实就是这个GNB模型的参数部分。当然,这个参数实际上也可以靠EM算法之类的方法训练出来。
同样的道理,如果处理离散问题,可以假设模型服从多项式分布。