Bayesian Network是有向无环图(directed acyclic graph, DAG),其推断的过程是由根节点(root node)逐次扩散到叶节点(leaf node)的过程,在Bayesian Network的一个节点可以描述为以下方向图:

图1 Bayesian Network的一个节点
图1中
Zj
是Bayesian Network中的一个节点,即一个随机变量,
Paj
是它的Parents(父节点)。设
pθ(Zj|Paj)=N(Zj ; hθ(Paj),σ2zI)
,表示在给定Parents时,
Zj
是以
hθ(Paj)
为中心的正态分布。在我们用MC(蒙地卡罗)方法进行推断时,为获得
Zj
的样本,需要先得到
Paj
的样本
paj
,然后通过
pθ(Zj|Paj=paj)=N(Zj ; hθ(paj),σ2zI)
抽样才能得到,即构造了一个新的分布后再抽样。
文章《Fast Gradient-Based Inference with Continuous Latent Variable Models in Auxiliary Form》为我们提出了一种辅助模型,该模型简单地可见图2:

图2 辅助模型
辅助模型在原有的模型上添加了一个新的随机变量
Ej
原来的
pθ(Zj|Paj)
成为了新的模型
p̂θ(Zj,Ej|Paj)
,令
pθ(Zj|Paj)
是
p̂θ(Zj,Ej|Paj)
的边沿分布:
pθ(Zj|Paj)=∫Ejp̂θ(Zj,Ej|Paj) dEj=∫Ejp̂θ(Zj|Paj,Ej)p̂θ(Ej|Paj) dEjEj is independent to Paj,so=∫Ejp̂θ(Zj|Paj,Ej)p̂θ(Ej) dEj(1)
上式中
p̂θ(Zj|Paj,Ej)
被称为conditionally deterministic variables的密度,它是
δ(⋅)
函数,即
Paj
和
Ej
一旦确定,则
Zj
便能确定,不再是随机量。我们令:
zj=gθ(paj,ej)so thatp̂θ(Zj=zj|Paj=paj,Ej=ej)=δ(zj−gθ(paj,ej))(2)
式中
gθ(paj,ej)
是我们可以选择的生成函数,将(2)代入(1)有:
pθ(Zj=zj|Paj=paj)=∫eδ(zj−gθ(paj,ej))⋅p̂θ(e) de(3)
根据
δ(⋅)
性质,则有:
zj=gθ(paj,ej)
。
假设图1所反映的条件分布是正态分布:
pθ(Zj=zj|Paj=paj)=N(zj;hθ(paj),σ2zI)(4)
式中
hθ(paj)
是变量
Zj
的所有父节点参与的一个映射,
pθ(Zj=zj|Paj=paj)
是以这个映射的像为均值的正态分布,映射可以由一层(或多层)神经网络实现。
设计生成函数
gθ(⋅)
如下:
zj=gθ(paj,ej)=hθ(paj)+ej⋅σz(5)其中,ej∈N(0,I)⇒ej=zj−hθ(paj)σz∼N(0,I)⇒zj∼N(hθ(paj),σ2zI)(6)
代入(3)即有:
∫eδ(zj−gθ(paj,ej))⋅p̂θ(e) de=N(zj;hθ(paj),σ2zI)(7)
由此例可见,加入了辅助变量,并不影响原来的变量关系和概率分布。但我们在产生
Zj
的样本时的方法不同:
1、原来模型,是从(4)式所定义的分布:
N(zj;hθ(paj),σ2zI)
进行抽样;
2、辅助模型,是从
ej∈N(0,I)
中进行抽样,然后代入生成函数产生:
zj=gθ(paj,ej)=hθ(paj)+ej⋅σz
由上比较可见,采用辅助模型在实现时是要简单一点的。其实在VAE的实现时,对CODE进行抽样就是这样完成的:
1、Encoder对输入样本
xj
(例如:MNIST图),进行编码,这相当于
hθ(paj)
,此时的
paj
就是Encoder输入的
xj
,编码Code相当于
zj
;
2、Decoder对
zj
的抽样进行映射得到
xj^
。其概率图如下:
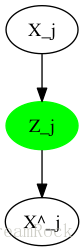
图3 VAE概率图模型
具体实现时,在VAE原来模型上增加了辅助变量,产生了新的辅助模型,如图:
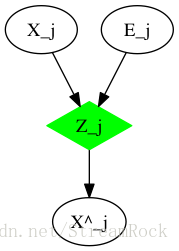
图4 VAE实现模型
其中
Zj
抽样是按公式(5)实现的。
参考:
1、《Fast Gradient-Based Inference with Continuous Latent Variable Models in Auxiliary Form》Diederik P. Kingma 2013.6
Diederik P. Kingma在2014年,发表了著名的《Auto-Encoding Variational Bayes》,提出了VAE模型,可以说[1]就是VAE的先导。