最近在看关于Matting的文章,这篇论文算是比较经典的老论文了,所以翻译过来,阅读更加方便些。
文章翻译大部使用谷歌在线翻译,对其中小部分错误进行了修正。
A Bayesian Approach to Digital Matting
1、Introduction
In digital matting, a foreground element is extracted from a background image by estimating a color and opacity for the foreground element at each pixel.
通过估计每个像素处的前景元素的颜色和不透明度,从背景图像中提取前景元素。
The opacity value at each pixel is typically called its alpha (0~1)
Matting is used in order to composite the foreground element into a new scene.
使用融合(Matting)来将前景元素合成为新场景。
2、Background
the alpha channel—and showed how synthetic images with alpha could be useful in creating complex digital images. The most common compositing operation is the over operation, which is summarized by the compositing equation:
alpha通道展示了具有alpha的合成图像如何在创建复杂的数字图像时有用。最常见的合成操作是过操作,其由合成方程是:
![]()
where C, F, and B are the pixel’s composite, foreground, and background colors, respectively, and α is the pixel’s opacity component used to linearly blend between foreground and background.
其中C,F和B分别是像素的合成,前景和背景颜色,α是用于在前景和背景之间线性组合的像素不透明度组件。
Blue screen matting was among the first techniques used for live action matting. The principle is to photograph the subject against a constant-colored background, and extract foreground and alpha treating each frame in isolation. This single image approach is underconstrained since, at each pixel, we have three observations and four unknowns. Vlahos pioneered the notion of adding simple constraints to make the problem tractable; this work is nicely summarized by Smith
蓝屏消光是用于真人动作消光的首批技术之一。原理是在恒定颜色的背景下拍摄对象,并提取前景和alpha处理每个帧。这种单一图像方法不受约束,因为在每个像素处,我们有三个观察值和四个未知数。Vlahos开创了添加简单约束以使问题易于处理的概念; Smith & Blinn [Blue Screen Matting]很好地总结了这项工作。
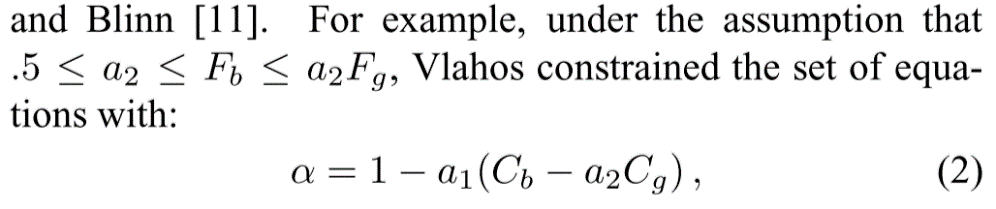
Where and $c_{g}$ are the blue and green channels of the input image,
其中$c_{b}$和$c_{g}$是输入图像的blue和green通道
respectively, and a1 and a2 are user-controlled tuning parameters. Additional constraint equations such as this one, however, while easy to implement, are ad hoc, require an expert to tune them, and can fail on fairly simple foregrounds.
$a_{1}和$a_{2}分别是用户控制的调谐参数。然而,诸如此类的附加约束方程虽然易于实现,但这是临时的,需要人来调整它们,并且有可能在很简单的前景的情境下出现错误。
More recently, Mishima [5] developed a blue screen matting technique based on representative foreground and background samples. In particular, the algorithm starts with two identical polyhedral (triangular mesh) approximations ofa sphere in rgb space centered at the average value B of the background samples.
最近,Mishima [5]开发了一种基于代表性前景和背景样本的蓝屏消光技术。特别地,该算法通过RGB空间以背景样本B之平均值为中心的两个相同的多面体(三角形网络)近似开始
The vertices of one of the polyhedra (the background polyhedron) are then repositioned by moving them along lines radiating from the center until the polyhedron is as small as possible while still containing all the background samples. The vertices of the other polyhedron (the foreground polyhedron) are similarly adjusted to give the largest possible polyhedron that contains no foreground pixels from the sample provided. Given a new composite color C, then, Mishima casts a ray from B through C and defines the intersections with the background and foreground polyhedra to be B and F, respectively. The fractional position of C along the line segment BF is α.
然后通过沿着从中心辐射的线移动多面体的一个顶点(背景多面体)来重新定位,直到多面体尽可能小,同时仍然包含所有背景样本。类似地调整另一个多面体(前景多面体)的顶点以给出最大可能的多面体,其不包含来自所提供的样本的前景像素。给定一个新的复合颜色C,然后,Mishima投射从B到C的光线,并将背景和前景多面体的交点分别定义为B和F. 沿着线段BF的C的分数位置是α。

Under some circumstances, it might be possible to photograph a foreground object against a known but non-constant background. One simple approach for handling such a scene is to take a difference between the photograph and the known background and determine α to be 0 or 1 based on an arbitrary threshold. This approach, known as difference matting [9] is error prone and leads to “jagged” mattes. Smoothing such mattes by blurring can help with the jaggedness but does not generally compensate for gross errors.
在某些情况下,它可以针对已知但非恒定的背景拍摄前景对象。处理这种场景的一种简单方法是在照片和已知背景之间取差异,并基于任意阈值确定α为0或1。这种被称为差异消光的方法(参见例如[9])容易出错并导致“锯齿状”融合。通过模糊来平滑这些融合能够有助于减少锯齿状,但通常不能弥补严重错误。
One limitation of blue screen and difference matting is the reliance on a controlled environment or imaging scenario that provides a known, possibly constant-colored background. The more general problem of extracting foreground and alpha from relatively arbitrary photographs or video streams is known as natural image matting. To our knowledge, the two most successful natural image matting systems are Knockout, developed by Ultimatte (and, to the best ofour knowledge, described in patents by Berman et al. [1, 2]), and the technique of Ruzon and Tomasi [10]. In both cases, the process begins by having a user segment the image into three regions: definitely foreground, definitely background, and unknown (as illustrated in Figure 1(a)). The algorithms then estimate F,B, and α for all pixels in the unknown region.
蓝屏和差异消光的一个限制是依赖于受控环境或成像场景,其提供已知的,可能是恒定颜色的背景。从相对任意的照片或视频中提取前景和alpha的更一般的问题被称为自然图像消光。据我们所知,两个最成功的自然图像消光系统是由Ultimatte开发的Knockout(以及Berman等[1,2]专利中描述的最佳知识),以及Ruzon和Tomasi的技术[10]。在这两种情况下,该过程首先让用户将图像分成三个区域:绝对前景,明确背景和未知(如图a所示)。 然后算法估计未知区域中所有像素的F,B和α。
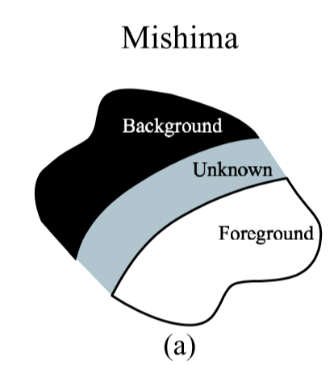
For Knockout, after user segmentation, the next step is to extrapolate the known foreground and background colors into the unknown region. In particular, given a point in the unknown region, the foreground F is calculated as a weighted. sum of the pixels on the perimeter of the known foreground region. The weight for the nearest known pixel is set to 1, and this weight tapers linearly with distance, reaching 0 for pixels that are twice as distant as the nearest pixel. The same procedure is used for initially estimating the background B based on nearby known background pixels. Figure 1(b) shows a set of pixels that contribute to the calculation of F and B of an unknown pixel.
对于Knockout,在用户分割之后,下一步是将已知的前景色和背景色外推到未知区域。特别地,给定未知区域中的点,前景F被计算为加权。已知前景区域周边上的像素之和。最近的已知像素的权重设置为1,并且该权重随距离线性地逐渐变细,对于距离最近像素两倍的像素,该权重达到0。基于附近的已知背景像素,使用相同的过程来初始估计背景B. 图b显示了一组有助于计算未知像素的F和B的像素。
The estimated background color B is then refined to give B using one of several methods [2] that are all similar in character. One such method establishes a plane through the estimated background color with normal parallel to the line BF. The pixel color in the unknown region is then projected along the direction of the normal onto the plane, and this projection becomes the refined guess for B. Figure 1(f) illustrates this procedure.
然后将估计的背景颜色B细化以使用几种在性质上相似的方法[2]中的一种来给出B. 一种这样的方法通过估计的背景颜色建立平面,其中法线平行于线B`F。然后将未知区域中的像素颜色沿法线方向投影到平面上,并且该投影成为B的精确猜测。图f示出了该过程。
最后,Knockout根据公式估计α
![]()
where f(·) projects a color onto one of several possible axes through rgb space (e.g., onto one of the r-, g-, or b- axes). Figure 1(f) illustrates alphas computed with respect to the r- axes and g- axes. In general, α is computed by projection onto all of the chosen axes, and the final α is taken as a weighted sum over all the projections, where the weights are proportional to the denominator in equation (3) for each axis.
其中f(·)通过RGB空间(例如,在r轴,g轴或b轴之上)将颜色投影到几个可能的轴之上。图f示出了相对于r轴和g轴计算的α。通常,α通过投影到所有选定轴上来计算,并且最终α被视为所有投影的加权和,其中权重与等式(3)中的每个轴的分母成比例。
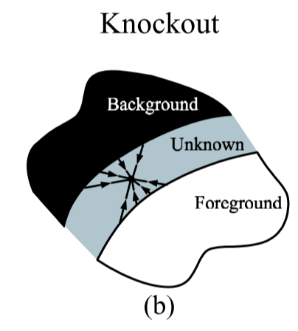
Ruzon and Tomasi [10] take a probabilistic view that is somewhat closer to our own. First, they partition the unknown boundary region into sub-regions. For each sub-region, they construct a box that encompasses the sub-region and includes some of the nearby known foreground and background regions (see Figure 1(c)). The encompassed foreground and background pixels are then treated as samples from distributions P(F) and P(B), respectively, in color space. The foreground pixels are split into coherent clusters, and unoriented Gaussians (i.e., Gaussians that are axis-aligned in color space) are fit to each cluster, each with mean F and diagonal covariance matrix ΣF. In the end, the foreground distribution is treated as a mixture (sum) of Gaussians. The same procedure is performed on the background pixels yielding Gaussians, each with mean B and covariance ΣB, and then every foreground cluster is paired with every background cluster. Many of these pairings are rejected based on various “intersection” and “angle” criteria. Figure 1(g) shows a single pairing for a foreground and background distribution.
Ruzon和Tomasi [10]采用的概率观点更接近我们的方法。首先,它们将未知边界区域划分为子区域。对于每个子区域,它们构造一个包含子区域的框,并包括一些附近已知的前景区域和背景区域(参见图c)。然后将包围的前景和背景像素分别作为来自颜色空间中的分布P(F)和P(B)的样本处理。前景像素被分成相干簇,并且未定向高斯(即,在颜色空间中轴对齐的高斯)适合于每个簇,每个簇具有平均F和对角线协方差矩阵ΣF。最后,前景分布被视为高斯的混合(和)。对产生高斯的背景像素执行相同的过程,每个高斯具有均值B和协方差ΣB,然后每个前景聚类与每个背景聚类配对。基于各种“交叉”和“角度”标准,许多这些配对被拒绝。图1(g)显示了前景和背景分布的单个配对。
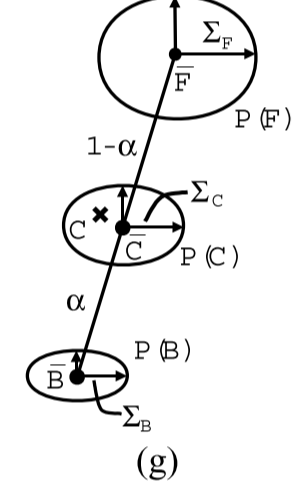
After building this network of paired Gaussians, Ruzon and Tomasi treat the observed color C as coming from an intermediate distribution P(C), somewhere between the foreground and background distributions. The intermediate distribution is also defined to be a sum ofGaussians, where each Gaussian is centered at a distinct mean value C located fractionally (according to a given alpha) along a line between the mean of each foreground and background cluster pair with fractionally interpolated covariance ΣC, as depicted in Figure 1(g). The optimal alpha is the one that yields an intermediate distribution for which the observed color has maximum probability; i.e., the optimal α is chosen independently of F and B. As a post-process, the F and B are computed as weighted sums of the foreground and background cluster means using the individual pairwise distribution probabilities as weights. The F and B colors are then perturbed to force them to be endpoints of a line segment passing through the observed color and satisfying the compositing equation.
在构建成对高斯的这个网络之后,Ruzon和Tomasi将观察到的颜色C视为来自中间分布P(C),介于前景和背景分布之间。中间分布也被定义为高斯函数的和,其中每个高斯中心位于沿着每个前景和背景聚类对的平均值之间的线小数(根据给定的α)定位的不同平均值C,具有分数插值协方差ΣC ,如图g所示。最佳α是产生中间分布的α,其中观察到的颜色具有最大概率;即,最优α独立于F和B选择,作为后处理。F和B被计算为前景和背景聚类均值的加权和,使用各个成对分布概率作为权重。然后扰动F和B颜色以迫使它们成为穿过观察到的颜色并满足合成方程的线段的端点。
Both the Knockout and the Ruzon-Tomasi techniques can be extended to video by hand-segmenting each frame, but more automatic techniques are desirable for video. Mitsunaga et al. [6] developed the AutoKey system for extracting foreground and alpha mattes from video, in which a user seeds a frame with foreground and background contours, which then evolve over time. This approach, however, makes strong smoothness assumptions about the foreground and background (in fact, the extracted foreground layer is assumed to be constant near the silhouette) and is designed for use with fairly hard edges in the transition from foreground to background; i.e., it is not well-suited for transparency and hair-like silhouettes.
Knockout和Ruzon-Tomasi技术都可以通过手动分割每个帧扩展到视频,但视频需要更多的自动技术。Mitsunaga等人[6]开发了AutoKey系统,用于从视频中提取前景和alpha融合,其中用户播种具有前景和背景轮廓的帧,然后随着时间的推移进化。然而,这种方法对前景和背景做出了很强的平滑假设(事实上,假设提取的前景层在轮廓附近是恒定的),并且设计用于从前景到背景的过渡中相当硬的边缘; 即,它不适合透明度和头发般的轮廓。
In each of the cases above, a single observation of a pixel yields an underconstrained system that is solved by building spatial distributions or maintaining temporal coherence. Wallace [12] provided an alternative solution that was independently (and much later) developed and refined by Smith and Blinn [11]: take an image of the same object in front of multiple known backgrounds. This approach leads to an overconstrained system without building any neighborhood distributions and can be solved in a least-squares framework. While this approach requires even more controlled studio conditions than the single solid background used in blue screen matting and is not immediately suitable for live-action capture, it does provide a means ofestimating highly accurate foreground and alpha values for real objects. We use this method to provide ground-truth mattes when making comparisons.
在上述每种情况下,对像素的单次观察产生通过构建求解的欠约束系统空间分布或保持时间一致性。Wallace[12]提供了另一种解决方案,由Smith & Blinn [11]独立(后来)开发和完善:在多个已知背景前拍摄同一物体的图像。这种方法导致过度约束系统而不构建任何邻域分布,并且可以在最小二乘框架中求解。虽然这种方法需要比蓝屏遮中使用的单一实体背景更加受控制的工作室条件,并且不能立即适用于实时捕捉,但它确实提供了一种估算真实物体的高精度前景和alpha值的方法。我们使用这种方法在进行比较时提供ground-truth融合。
3、Our Bayesian framework
For the development that follows, we will assume that our input image has already been segmented into three regions: “background,” “foreground,” and “unknown,” with the background and foreground regions having been delineated conservatively. The goal of our algorithm, then, is to solve for the foreground color F, background color B, and opacity α given the observed color C for each pixel within the unknown region of the image. Since F, B, and C have three color channels each, we have a problem with three equations and seven unknowns.
对于随后的开发,我们将假设我们的输入图像已经被分割成三个区域:“背景”,“前景”和“未知”,其中背景和前景区域已经保守地描绘。然后,我们的算法的目标是在给定图像的未知区域内的每个像素的观察到的颜色C的情况下求解前景色F,背景色B和不透明度α。由于F,B和C各有三个颜色通道,因此我们遇到三个方程和七个未知数的问题。
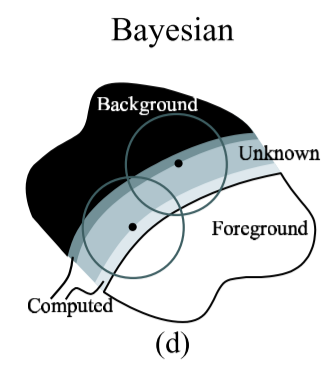
Like Ruzon and Tomasi [10], we will solve the problem in part by building foreground and background probability distributions from a given neighborhood. Our method, however, uses a continuously sliding window for neighborhood definitions, marches inward from the foreground and background regions, and utilizes nearby computed F, B, and α values (in addition to these values from “known” regions) in constructing oriented Gaussian distributions, as illustrated in Figure 1(d). Further, our approach formulates the problem of computing matte parameters in a well-defined Bayesian framework and solves it using the maximum a posteriori (MAP) technique. In this section, we describe our Bayesian framework in detail.
像Ruzon和Tomasi [10]一样,我们将通过构建来自给定邻域的前景和背景概率分布来解决问题。然而,我们的方法使用连续滑动窗口进行邻域定义,从前景和背景区域向内行进,并利用附近计算的F,B和α值(除了来自“已知”区域的这些值)构造定向高斯分布,如图d所示。此外,我们的方法制定了在明确定义的贝叶斯框架中计算融合参数的问题,并使用最大后验(MAP)技术来解决它。在本节中,我们将详细描述贝叶斯框架。
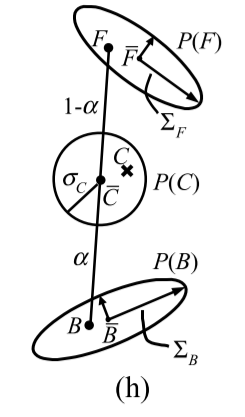
In MAP estimation, we try to find the most likely estimates for F, B, and α, given the observation C. We can express this as a maximization over a probability distribution P and then use Bayes’s rule to express the result as the maximization over a sum of log likelihoods:
在MAP估计中,我们试图在给定观察C的情况下找到最可能的F,B和α估计。我们可以将其表达为概率分布P的最大化,然后使用贝叶斯规则将结果表示为最大化对数似然总和:

where L(·) is the log likelihood L(·) = logP(·), and we drop the P(C) term because it is a constant with respect to the optimization parameters. (Figure 1(h) illustrates the distributions over which we solve for the optimal F, B, and α parameters.)
其中L(·)是对数似然L(·)= logP(·),我们删除P(C)项,因为它是关于优化参数的常数。(图h说明了我们求解最优F,B和α参数的分布。)
The problem is now reduced to defining the log likelihoods L(C | F, B, α), L(F), L(B), and L(α).
We can model the first term by measuring the difference between the observed color and the color that would be predicted by the estimated F, B, and α:
现在将问题简化为定义对数似然L(C | F,B,α),L(F),L(B)和L(α)。
我们可以通过测量观察到的颜色与估计的F,B和α预测的颜色之间的差异来建模第一项:
![]()
This log-likelihood models error in the measurement ofC and corresponds to a Gaussian probability distribution centered at C = αF + (1 − α)B with standard deviation σC.
该对数似然模型在C的测量中模型误差并且对应于以C =αF+(1-α)B为中心的高斯概率分布,具有标准偏差σC。
We use the spatial coherence of the image to estimate the foreground term L(F). That is, we build the color probability distribution using the known and previously estimated foreground colors within each pixel’s neighborhood N. To more robustly model the foreground color distribution, we weight the contribution of each nearby pixel i in N according to two separate factors. First, we weight the pixel’s contribution by $a_{i}^{2}$ which gives colors of more opaque pixels higher confidence. Second, we use a spatial Gaussian fall off $g_{i}$ with σ = 8 to stress the contribution of nearby pixels over those that are further away. The combined weight is then $ω_{i}$ = $a_{i}^{2}$*$g_{i}$
我们使用图像的空间相干性来估计前景项L(F)。也就是说,我们使用每个像素的邻域N内的已知和先前估计的前景颜色来建立颜色概率分布。为了更加鲁棒地模拟前景颜色分布,我们根据两个单独的因子来加权每个邻近像素i在N中的贡献。首先,我们将像素的贡献加权$a_{i}^{2}$,这给了更多的不透明像素更高的可信度颜色。其次,我们使用σ= 8的空间高斯衰减$g_{i}$来强调附近像素对远离那些像素的贡献。然后,合并的权重为$ω_{i}$ = $a_{i}^{2}$*$g_{i}$
Given a set of foreground colors and their corresponding weights, we first partition colors into several clusters using the method of Orchard and Bouman [7]. For each cluster, we calculate the weighted mean color F and the weighted covariance matrix ΣF:
给定一组前景色及其相应的权重,我们首先使用Orchard和Bouman [7]的方法将颜色分成几个簇。对于每个聚类,我们计算加权平均颜色F和加权协方差矩阵ΣF:
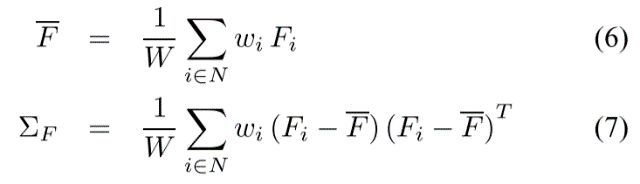
W=$\sum_{i\epsilon N}^{}$$\omega _{i}$ The log likelihoods for the foreground L(F) can then be modeled as being derived from an oriented elliptical Gaussian distribution, using the weighted covariance matrix as follows:
然后可以使用加权协方差矩阵W=$\sum_{i\epsilon N}^{}$$\omega _{i}$ 将前景L(F)的对数似然建模为从定向椭圆高斯分布导出,如下:
![]()
The definition of the log likelihood for the background L(B) depends on which matting problem we are solving. For natural image matting, we use an analogous term to that of the foreground, setting $\omega _{i}$ to $ (1-a_{i})^{2}g_{i}$ and substituting B in place of F in every term of equations (6), (7), and (8). For constant-color matting, we calculate the mean and covariance for the set of all pixels that are labelled as background. For difference matting, we have the background color at each pixel; we therefore use the known background color as the mean and a user-defined variance to model the noise of the background.
背景L(B)的对数似然的定义取决于我们正在解决的问题。对于自然图像消光,我们使用类似于前景的术语,将 $\omega _{i}$设置为$ (1-a_{i})^{2}g_{i}$
并且在等式(6),(7)的每个项中用B代替F,并且(8)对于恒定颜色消光,我们计算标记为背景的所有像素集的均值和协方差。对于差异消光,我们在每个像素处都有背景颜色; 因此,我们使用已知的背景颜色作为均值和用户定义的方差来模拟背景噪声。
In this work, we assume that the log likelihood for the opacity L(α) is constant (and thus omitted from the maximization in equation (4)). A better definition of L(α) derived from statistics of real alpha mattes is left as future work.
Because of the multiplications ofα with F and B in the log likelihood L(C | F, B, α), the function we are maximizing in (4) is not a quadratic equation in its unknowns. To solve the equation efficiently, we break the problem into two quadratic sub-problems. In the first sub-problem, we assume that α is a constant. Under this assumption, taking the partial derivatives of (4) with respect to F and B and setting them equal to 0 gives:
在这项工作中,我们假设不透明度L(α)的对数似然是常数(因此从等式(4)的最大化中省略)。从真实alpha融合的统计得出的更好的L(α)定义留作未来的工作。
由于在对数似然L(C | F,B,α)中α与F和B的乘积,我们在(4)中最大化的函数不是其未知数中的二次方程。为了有效地求解方程,我们将问题分解为两个二次子问题。在第一个子问题中,我们假设α是常数。在这个假设下,对于F和B取(4)的偏导数并将它们设置为等于0给出:
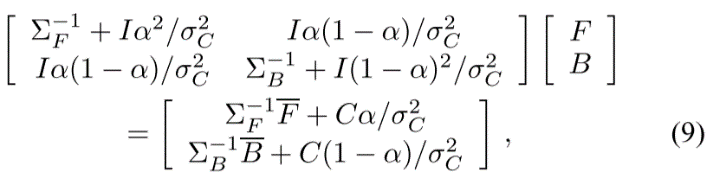
where I is a 3×3 identity matrix. Therefore, for a constant α, we can find the best parameters F and B by solving the 6×6 linear equation (9).
In the second sub-problem, we assume that F and B are constant, yielding a quadratic equation in α. We arrive at the solution to this equation by projecting the observed color C onto the line segment F B in color space:
其中I是3×3单位矩阵。因此,对于常数α,我们可以通过求解6×6线性方程(9)找到最佳参数F和B.
在第二个子问题中,我们假设F和B是常数,在α中产生二次方程。我们通过将观察到的颜色C投影到颜色空间中的线段F B上来得到该等式的解:
![]()
where the numerator contains a dot product between two color difference vectors. To optimize the overall equation (4) we alternate between assuming that α is fixed to solve for F and B using (9), and assuming that F and B are fixed to solve for α using (10). To start the optimization, we initialize α with the mean α over the neighborhood of nearby pixels and then solve the constant-α equation (9).
其中分子包含两个色差矢量之间的点积。为了优化整个等式(4),我们在假设α被固定以使用(9)求解F和B并假设F和B被固定以使用(10)求解α之间交替。为了开始优化,我们用附近像素附近的平均α初始化α,然后求解常数α方程(9)。
When there is more than one foreground or background cluster, we perform the above optimization procedure for each pair of foreground and background clusters and choose the pair with the maximum likelihood. Note that this model, in contrast to a mixture of Gaussians model, assumes that the observed color corresponds to exactly one pair of foreground and background distributions. In some cases, this model is likely to be the correct model, but we can certainly conceive of cases where mixtures of Gaussians would be desirable, say, when two foreground clusters can be near one another spatially and thus can mix in color space. Ideally, we would like to support a true Bayesian mixture model. In practice, even with our simple exclusive decision model, we have obtained better results than the existing approaches.
当存在多个前景或背景聚类时,我们对每对前景和背景聚类执行上述优化过程,并选择具有最大似然的对。注意,与高斯模型的混合相比,该模型假设观察到的颜色恰好对应于一对前景和背景分布。在某些情况下,这个模型可能是正确的模型,但我们当然可以设想需要高斯混合的情况,例如,当两个前景聚类在空间上彼此靠近并因此可以在颜色空间中混合时。理想情况下,我们希望支持真正的贝叶斯混合模型。在实践中,即使使用我们简单的独家决策模型,我们也获得了比现有方法更好的结果。
4、Result and comparisons
We tried out our Bayesian approach on a variety of different input images, both for blue-screen and for natural image matting. Figure 2 shows four such examples. In the rest of this section, we discuss each of these examples and provide comparisons between the results of our algorithm and those of previous approaches. For more results and color images, please visit the URL listed under the title.
我们在各种不同的输入图像上尝试了贝叶斯方法,包括蓝屏和自然图像消光。图2显示了四个这样的例子。在本节的其余部分,我们将讨论这些示例中的每一个,并提供我们的算法结果与以前方法的结果之间的比较。有关更多结果和彩色图像,请访问标题下列出的URL。

Figure 2 Summary of input images and results. Input images (top row): a blue-screen matting example of a toy lion, a synthetic “natural image” of the same lion (for which the exact solution is known), and two real natural images, (a lighthouse and a woman). Input segmentation (middle row): conservative foreground (white), conservative background (black), and “unknown” (grey). The leftmost segmentation was computed automatically (see text), while the rightmost three were specified by hand. Compositing results (bottom row): the results of compositing the foreground images and mattes extracted through our Bayesian matting algorithm over new background scenes.
图2输入图像和结果摘要。输入图像(顶行):玩具狮子的蓝屏消光示例,同一狮子的合成“自然图像”(已知确切解决方案),以及两个真实的自然图像(灯塔和女人))。输入分割(中间行):保守前景(白色),保守背景(黑色)和“未知”(灰色)。最左边的分割是自动计算的(见文本),而最右边的三个是手动指定的。合成结果(底行):合成前景图像和通过贝叶斯消光算法在新背景场景中提取的融合的结果。
4.1 Blue screen Matting
We filmed our target object, a stuffed lion, in front of a computer monitor displaying a constant blue field. In order to obtain a ground-truth solution, we also took radiance-corrected, high dynamic range [3] pictures of the object in front of five additional constant-color backgrounds. The ground-truth solution was derived from these latter five pictures by solving the overdetermined linear system of compositing equations (1) using singular value decomposition.
我们在显示恒定蓝色区域的计算机显示器前拍摄了我们的目标物体,一只毛绒狮子。为了获得地面实况解决方案,我们还在五个额外的恒定颜色背景前面拍摄了物体的辐射校正,高动态范围[3]图片。通过使用奇异值分解求解合成方程(1)的超定线性系统,从后五个图中得出了真实性解。
Both Mishima’s algorithm and our Bayesian approach require an estimate of the background color distribution as input. For blue-screen matting, a preliminary segmentation can be performed more-or-less automatically using the Vlahos equation (2) from Section 2. Setting a1 to be a large number generally gives regions of pure background (where α ≤ 0), while setting a1 to a small number gives regions of pure foreground (where α ≥ 1). The leftmost image in the middle row of Figure 2 shows the preliminary segmentation produced in this way, which was used as input for both Mishima’s algorithm and our Bayesian approach.
Mishima’s算法和贝叶斯方法都需要估计背景颜色分布作为输入。对于蓝屏消光,可以使用第2节中的Vlahos方程(2)自动执行初步分割。将a1设置为大数通常给出纯背景区域(其中α≤0),而将a1设置为较小的数字会给出纯前景区域(其中α≥1)。图2中间行的最左边的图像显示了以这种方式产生的初步分割,它被用作Mishima算法和贝叶斯方法的输入。
In Figure 3, we compare our results with Mishima’s algorithm and with the ground-truth solution. Mishima’s algorithm exhibits obvious “blue spill” artifacts around the boundary, whereas our Bayesian approach gives results that appear to be much closer to the ground truth.
在图3中,我们将我们的结果与Mishima的算法和地面实况解决方案进行了比较。Mishima的算法在边界周围显示出明显的“蓝色溢出”伪影,而我们的贝叶斯方法给出了出现的结果
更接近实际情况。

Figure 3 Blue-screen matting of lion (taken from leftmost column of Figure 2). Mishima’s results in the top row suffer from “blue spill.” The middle and bottom rows show the Bayesian result and ground truth, respectively.
4.2 Natural image Matting
Figure 4 provides an artificial example of “natural image matting,” one for which we have a ground-truth solution. The input image was produced by taking the ground-truth solution for the previous blue-screen matting example, compositing it over a (known) checkerboard background, displaying the resulting image on a monitor, and then re-photographing the scene. We then attempted to use four different approaches for re-pulling the matte: a simple difference matting approach (which takes the difference of the image from the known background, thresholds it, and then blurs the result to soften it); Knockout; the Ruzon and Tomasi algorithm, and our Bayesian approach. The ground-truth result is repeated here for easier visual comparison. Note the checkerboard artifacts that are visible in Knockout’s solution. The Bayesian approach gives mattes that are somewhat softer, and closer to the ground truth, than those of Ruzon and Tomasi.
图4提供了一个“自然图像消光”的人工例子,我们有一个真实的解决方案。输入图像是通过采用前一个蓝屏消光示例的地面实况解决方案,在(已知的)棋盘背景上合成,在监视器上显示结果图像,然后重新拍摄场景而产生的。 然后我们尝试使用四种不同的方法来重新拉动融合:一种简单的差异融合方法(它从已知背景中获取图像的差异,对其进行阈值处理,然后模糊结果以使其柔化);Knockout,Ruzon和Tomasi算法,以及我们的贝叶斯方法。这里复现了真实的地面场景,以便于进行视觉比较。请注意Knockout解决方案中可见的棋盘工件。 与Ruzon和Tomasi相比,贝叶斯方法给出了更柔和,更接近ground truth的融合。

Figure 4 “Synthetic” natural image matting. The top row shows the results of difference image matting and blurring on the synthetic composite image of the lion against a checkerboard (column second from left in Figure 2). Clearly, difference matting does not cope well with fine strands. The second row shows the result of applying Knockout; in this case, the interpolation algorithm poorly estimates background colors that should be drawn from a bimodal distribution. The Ruzon-Tomasi result in the next row is clearly better, but exhibits a significant graininess not present in the Bayesian matting result on the next row or the ground-truth result on the bottom row.
图4“合成”自然图像消光。顶行显示了狮子与棋盘的合成图像上的差异图像消光和模糊的结果(图2中左起第二列)。显然,差异消光不能很好地应对细线。第二行显示应用Knockout的结果; 在这种情况下,插值算法很难估计应该从双峰分布中提取的背景颜色。下一行的Ruzon-Tomasi结果显然更好,但在下一行的贝叶斯消光结果或底行的真实结果中表现出明显的颗粒度。
Figure 5 repeats this comparison for two (real) natural images (for which no difference matting or ground-truth solution is possible). Note the missing strands of hair in the close-up for Knockout’s results. The Ruzon and Tomasi result has a discontinuous hair strand on the left side ofthe image, as well as a color discontinuity near the center of the inset. In the lighthouse example, both Knockout and Ruzon-Tomasi suffer from background spill. For example, Ruzon-Tomasi allows the background to blend through the roof at the top center of the composite inset, while Knockout loses the railing around the lighthouse almost completely. The Bayesian results exhibit none of these artifacts.
图5重复了两个(真实的)自然图像的比较(对此没有差异消光或地面真实解决方案)。注意Knockout结果中特写的头发缺失。Ruzon和Tomasi结果在图像的左侧具有不连续的发束,以及在插图的中心附近的颜色不连续性。在灯塔示例中,Knockout和Ruzon-Tomasi都遭遇背景泄漏。例如,Ruzon-Tomasi允许背景通过复合材料插入物顶部中心的屋顶混合,而Knockout几乎完全失去灯塔周围的栏杆。贝叶斯结果没有表现出这些伪影。

Figure 5 Natural image matting. These two sets of photographs correspond to the rightmost two columns of Figure 2, and the insets show both a close-up of the alpha matte and the composite image. For the woman’s hair, Knockout loses strands in the inset, whereas Ruzon-Tomasi exhibits broken strands on the left and a diagonal color discontinuity on the right, which is enlarged in the inset. Both Knockout and Ruzon-Tomasi suffer from background spill as seen in the lighthouse inset, with Knockout practically losing the railing.
图5自然图像消光。这两组照片对应于图2中最右边的两列,并且插图显示了alpha融合和合成图像的特写。对于女人的头发,Knockout在插图中丢失了股线,而Ruzon-Tomasi在左边展示了断裂的股线,在右边展示了对角线颜色不连续,在插图中放大了。Knockout和Ruzon-Tomasi都遭遇了背景溢出,如灯塔插图所示,Knockout几乎失去了栏杆。
5、Conclusions
In this paper, we have developed a Bayesian approach to solving several image matting problems: constant-color matting, difference matting, and natural image matting. Though sharing a similar probabilistic view with Ruzon and Tomasi’s algorithm, our approach differs from theirs in a number of key aspects; namely, it uses (1) MAP estimation in a Bayesian framework to optimize α, F and B simultaneously, (2) oriented Gaussian covariances to better model the color distributions, (3) a sliding window to construct neighborhood color distributions that include previously computed values, and (4) a scanning order that marches inward from the known foreground and background regions. To sum up, our approach has an intuitive probabilistic motivation, is relatively easy to implement, and compares favorably with the state of the art in matte extraction.
在本文中,我们开发了一种贝叶斯方法来解决几个图像消光问题:恒色消光,差异消光和自然图像消光。 虽然与Ruzon和Tomasi的算法共享类似的概率视图,但我们的方法在许多关键方面与他们的方法不同; 即,它使用(1)贝叶斯框架中的MAP估计同时优化α,F和B,(2)定向高斯协方差以更好地模拟颜色分布,(3)构建邻域颜色分布的滑动窗口,包括先前计算的 值,以及(4)从已知前景和背景区域向内行进的扫描顺序。总之,我们的方法具有直观的概率动机,相对容易实现,并且与现有的消光提取技术相比是有利的。
In the future, we hope to explore a number of research directions. So far, we have omitted using priors on alpha. We hope to build these priors by studying the statistics of ground truth alpha mattes, possibly extending this analysis to evaluate spatial dependencies that might drive an MRF approach to image matting. Next, we hope to extend our framework to support mixtures of Gaussians in a principled way, rather than arbitrarily choosing among paired Gaussians as we do currently. Finally, we plan to extend our work to video matting with soft boundaries.
在未来,我们希望探索一些研究方向。到目前为止,我们已经省略了在alpha上使用priors。 我们希望通过研究地面实况alpha融合的统计数据来构建这些先验,可能会扩展此分析以评估可能驱动MRF方法进行图像融合的空间依赖性。接下来,我们希望扩展我们的框架,以原则的方式支持高斯混合,而不是像我们目前那样随意选择配对的高斯。最后,我们计划将我们的工作扩展到具有软边界的视频融合。