1. 概率论
与之相关的有概率论的一些知识,这里先做简单知识复习。
1.1 条件概率
条件概率是指事件A在另外一个事件B已经发生条件下的发生概率。条件概率表示为:P(A|B),读作“在B的条件下A的概率”。若只有两个事件A,B,那么
P(A∣B)=P(B)P(AB)设E 为随机试验,Ω 为样本空间,A,B 为任意两个事件,设P(A)>0,称
P(B∣A)=P(A)P(AB)为在“事件A 发生”的条件下事件B 的条件概率。上述乘法公式可推广到任意有穷多个事件时的情况。设
A1,A2,...,An为任意n个实践(n>=2)且
P(A1A2...An)>0,则
P(A1A2...An)=P(A1)P(A2∣A1)...P(An∣A1A2...An−1)
1.2 全概率公式
定义:(完备事件组/样本空间的划分)
设B1,B2,…Bn是一组事件,若
(1)
∀i̸=jϵ{1,2,...n},BinBj=∅
(2)B1∪B2∪…∪Bn=Ω
则称B1,B2,…Bn样本空间Ω的一个划分,或称为样本空间Ω 的一个完备事件组。
定理(全概率公式):
设事件组
{B}是样本空间Ω 的一个划分,且P(Bi)>0(i=1,2,…n)则对任一事件B,有
P(A)=i=1∑nP(Bi)P(A∣Bi)
1.3 贝叶斯公式
设B1,B2,…Bn…是一完备事件组,则对任一事件A,P(A)>0,有
P(Bi∣A)=P(A)P(ABi)=∑iP(Bi)P(A∣Bi)P(Bi)P(A∣Bi)
1.4 独立性
当且仅当两个随机事件A与B满足P(A∩B)=P(A)P(B)的时候,它们才是统计独立的,这样联合概率可以表示为各自概率的简单乘积。同样,对于两个独立事件A与B有P(A|B)=P(A)以及P(B|A)=P(B)换句话说,如果A与B是相互独立的,那么A在B这个前提下的条件概率就是A自身的概率;同样,B在A的前提下的条件概率就是B自身的概率。
2. 简单图分析(简单贝叶斯网络独立性分析)
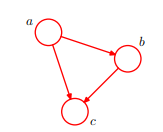
P(A,B,C)=P(C∣A,B)P(B∣A)P(A) 这个是对上面图的简单表示三个变量a,b,c的联合概率分布。对这个简单图有一定了解后深入了解会的到下列几个有趣的结论,后面可能会用到。
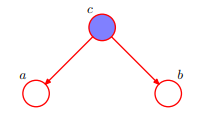
即 :在c给定的条件下,a,b被阻断(blocked)是独立的。
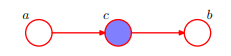
即 :在c给定的条件下,a,b被阻断(blocked)是独立的。
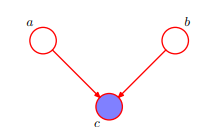
即 :而对于上图,在c未知的条件下,a,b被阻断(blocked)是独立的。
上面都是可以根据基本公式推导出来,如果感兴趣可以参考 : PRML 模式识别与机器学习
3. 朴素贝叶斯
朴素贝叶斯(Naive Bayes,NB)是基于** “特征之间是独立的”**这一朴素假设,应用贝叶斯定理的监督学习算法。
3.1朴素贝叶斯的推导
- 对于给定的特征向量
x1,x2,...,xn
- 类别 y 的概率可以依据贝叶斯公式得到:
P(y∣x1,x2,...,xn)=P(x1,x2,...,xn)P(y)P(x1,x2,...,xn∣y)
- 使用朴素的独立性假设:
P(xi∣y,x1,x2,...,xn)=P(xi∣y)
- 类别 y 的概率可简化为:
P(y∣x1,x2,...,xn)=P(x1,x2,...,xn)P(y)P(x1,x2,...,xn∣y)=P(x1,x2...,xn)P(y)∏i=1nP(xi∣y)
- 在给定样本的前提下,
P(x1,x2...,xn)是常数:
P(y∣x1,x2,...,xn)∞P(y)i=1∏nP(xi∣y)
- 从而有
y^=argmaxP(y)i=1∏nP(xi∣y)
3.2 高斯朴素贝叶斯(Gaussian Naive Bayes)
- 根据样本使用MAP估计
P(y),建立合理的模型估计
P(xi∣y),从而得到样本的类别。
y^=argmaxP(y)i=1∏nP(xi∣y)
- 假设特征服从高斯分布,即:
P(xi∣y)=2π
σy1exp(−2σy2(xi−μy)2)
参数估计使用MLE极大似然就可以
3.3 多项分布朴素贝叶斯(Multinomial Native Bayes)
- 假设特征服从多项分布,从而,对每个类别y,参数为
θy=(θy1,θy2,...,θyn),其中n为特征的数目,
P(xi∣y)的概率为
θyi。
- 参数
θy使用MLE估计的结果为:
θyi^=Ny+α⋅nNyi+α,α≥0
- 假定训练集为
T,有:
Nyi=xϵT∑xi,Ny=i=1∑∣a∣Nyi
- 其中
α=1称为Laplace平滑,
α<1称为Lidstone平滑。