基础模型:比如你想通过输入一个法语句子来将它翻译成一个英语句子,如下图,seq2seq模型,用x<1>一直到x<5>来表示输入句子的单词,然后我们用y<1>到y<6>来表示输出的句子的单词,如何训练一个新的网络,来输入序列x和输出序列y,这里有一些方法。首先,我们先建立一个网络,这个网络叫做编码网络,它是一个RNN的结构,RNN的单元可以是GRU,也可以是LSTM,每次只向该网络中输入一个法语单词,将输入序列接收完毕后,这个RNN网络会输出一个向量来代表这个输入序列。之后,你可以建立一个解码网络,它以编码网络的输出作为输入,之后它可以被训练为每次输出一个翻译后的单词,一直到它输出序列的结尾或者句子的结尾标记,这个解码网络的工作就结束了。

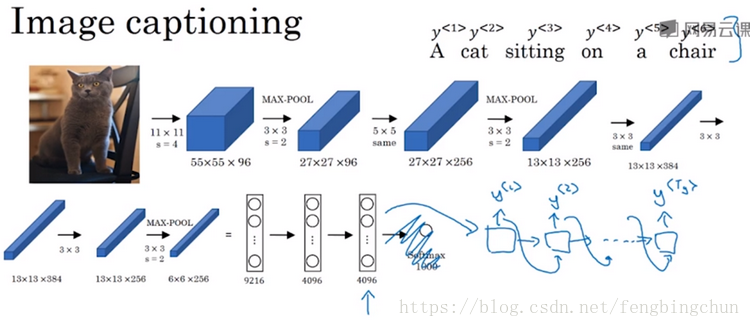
图像描述(image captioning):如下图,给出一张图片,比如这张猫的图片,它能自动地输出该图片的描述,一只猫坐在椅子上。如何训练出这样的网络通过输出图像来输出描述?方法如下:将图片输入到卷积神经网络中,比如一个预训练的AlexNet结构,然后让其学习图片的编码,或者学习图片的一系列特征,如果去掉最后的softmax单元,这个预训练的AlexNet结构会输出一个4096维的特征向量,向量表示的是这张图片的描述,所以这个预训练网络可以是图像的编码网络,接着你可以把这个向量输入到RNN中,RNN要做的就是生成图像的描述,每次生成一个单词,让网络输出序列或者说一个一个地输出单词序列。
Picking the most likely sentence: 如下图,你可以把机器翻译想成是建立一个条件语言模型。在语言模型中,能够估计句子的可能性,你也可以将它用于生成一个新的句子。机器翻译,如图中,用绿色表示encoder网络,用紫色表示decoder网络,decoder网络和语言模型很相似。机器翻译模型其实和语言模型非常相似,不同在于语言模型总是以零向量开始,而encoder网络会计算出一系列向量来表示输入句子而不是以零向量开始。所以把机器翻译叫做条件语言模型。

通过模型将法语翻译成英文:如下图,通过输入的法语句子,模型将会告诉你各种英文翻译所对应的可能性。你并不是从得到的分布中进行随机取样,而是你要找到一个英语句子y使得条件概率最大化。所以在开发机器翻译系统时,你需要作的一件事就是想出一个算法用来找出合适的y值使得该项最大化。而解决这种问题最通用的算法就是束搜索(beam search)。

为什么不用贪心搜索(greedy search)?贪心搜索是一种来自计算机科学的算法,生成第一个词的分布以后,它将会根据你的条件语言模型挑选出最有可能的第一个词,进入你的机器翻译模型中,在挑选出第一个最有可能的第一个词后,它将会继续挑选出最有可能的第二个词,然后继续挑选第三个最有可能的词,这种算法就叫做贪心搜索。但是你真正需要的是一次性挑选出整个单词序列来使得整体的概率最大化。一次仅仅挑选一个词并不是最佳的选择。
束搜索(beam search):如下图,输入法语句子翻译成英语句子。束搜索算法首先做的就是挑选要输出的英语翻译中的第一个单词,如一个10000个词的词汇表,在束搜索的第一步中评估第一个单词的概率值,束搜索算法会考虑多个选择,束搜索算法会有一个参数B,叫束宽,在这个例子中束宽设成3,意味着束搜索不会只考虑一个可能结果而是一次会考虑3个。束搜索算法会把结果存到计算机内存里以便后面尝试用这三个词。如果束宽设的不一样第一个单词的最可能的选择也不一样。为了执行束搜索的第一步你需要输入法语句子到编码网络然后会解码这个网络。束搜索算法的第二步,会针对每个第一个单词考虑第二个单词是什么,在第二步中我们更关心的是要找到最可能的第一个和第二个单词对,所以不仅仅是第二个单词有最大的概率而是第一个第二个单词对有最大的概率。然后用于下一次束搜索,最终这个过程的输出一次增加一个单词,束搜索最终会找到英语句子。如果束宽设为1实际上就变成了贪婪搜索算法。


改进束搜索(refinements to beam search):长度归一化就是对束搜索算法稍作调整的一种方式能够帮助你得到更好的结果。如下图,束搜索就是最大化这个概率,实际中总是记录概率的对数和而不是概率的乘积。

如何选择束宽B?B越大,你考虑的选择越多,你找到的句子可能越好,但是B越大,你的算法的计算代价越大。在产品中,经常看到将束宽设到10,也取决于不同应用,也有取更大值的如100,1000等。
束搜索的误差分析:束搜索算法是一种近似搜索算法,也被称作启发式搜索算法,它不总是输出可能性最大的句子,它仅记录着B为前3或者前10种可能。对束搜索算法进行误差分析(error analysis with beam search),如下图,判断是RNN网络还是束搜索导致的问题,先遍历开发集,然后在其中找出算法产生的错误,能够执行误差分析得出束搜索算法和RNN模型出错的比例是多少,你就可以对开发集中的每一个错误例子,尝试确定这些错误是搜索算法出了问题还是RNN模型出了问题。

Bleu score: 机器翻译的一个难题是一个法语句子可以有多种英文翻译,而且都同样好,所以当有同样好的答案时,怎样评估一个机器翻译系统?常见的解决办法是通过一个叫做BLEU得分的东西来解决。如下图,BLEU得分是一个有用的单一实数评估指标,用于评估生成文本的算法,判断输出的结果是否与人工写出的参考文本的含义相似.

Attention model intuition: 如下图,注意力模型(attention model)非常适用于机器翻译中的长句子。对于长句子,人工会一边读一边翻译,在神经网络中记忆非常长句子是非常困难的。注意力模型翻译的很像人类一次翻译句子的一部分。注意力模型会计算注意力权重,图中α表示注意力权重。
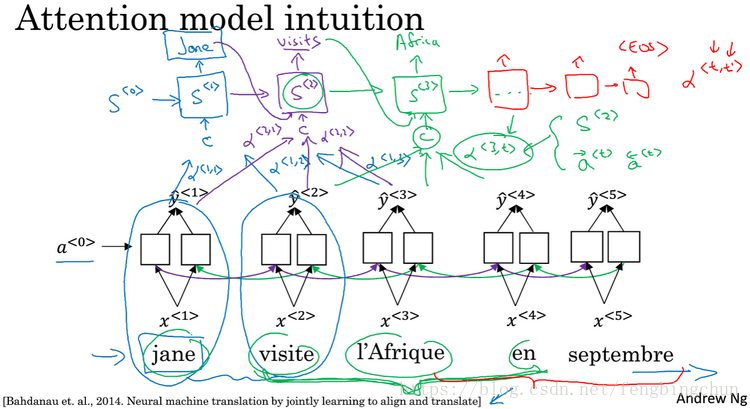
Attention model: 如下图,假定有一个输入句子并使用双向的RNN或者双向的GRU或者双向的LSTM去计算每个词的特征。对于前向传播,你有第一个时间步的前向传播的激活值,第一个时间步后向传播的激活值,第二个时间步的前向传播激活值,第二个时间步后向的激活值,以此类推。它们一共向前了5个时间步,也向后了5个时间步,a<0>和a<6>都是0的因子,a<t>是时间步t上的特征向量。α为注意力参数,告诉我们应该花多少注意力,也告诉我们上下文有多少取决于我们得到的特征。

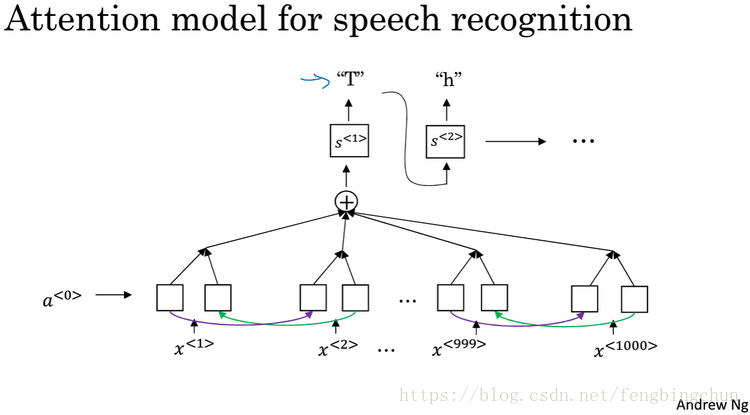
语音识别:有一个音频片段x,你的任务是自动生成文本y。用一个很大的数据集,可能长达300个或3000个小时。可以将注意力模型或CTC损失函数应用到语音识别系统中,如下图:
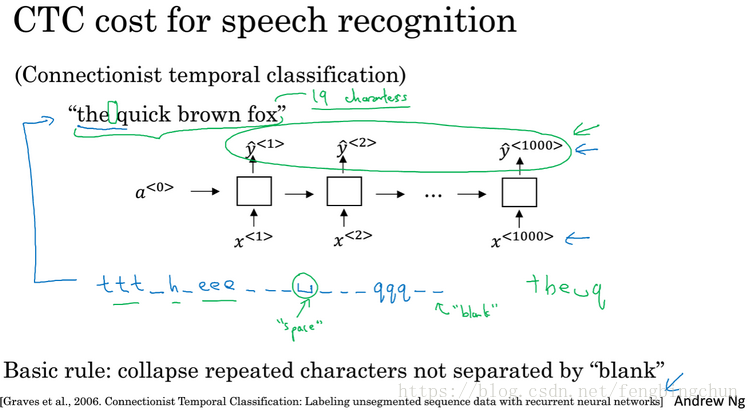
Trigger word detection: 触发字系统(trigger word system):随着语音识别的发展越来越多的设备可以通过你的声音来唤醒,这有时被叫做触发字检测系统。触发字系统的例子包括,如下图:Amazon echo, 它通过单词Alexa唤醒;百度DuerOS设备通过”小度你好”来唤醒;苹果的Siri用Hey Siri来唤醒;Google Home使用Okey Googel来唤醒。
