MiCT: Mixed 3D/2D convolutional tube for human action recognition
Absatrct: 无论3D还是2D都是在静止图像上有很好的效果。对于时空融合的这种,巨大内存成本还是太高了。混合卷积MiCT,将2D/3D卷积模块相结合,以生成更深入,更丰富的信息特征图。
Introduction
空间和时间信号通过每个3D卷积彼此耦合,it becomes much more difficult to optimize the network with dozens of such 3D convolution layers because of the exponential growth of the solution space with respect to the case of 2D cnns.3D卷积储存成本太高,这使得3D cnn的特征通常不够深,11层3d cnn需要的内存几乎是152残差网络的1.5倍。基于上述观察,在限制3d 卷积层数目的同时增加特征图的深度是有意义的

基于2D-cnn和3D cnn的方法

基于2D-cnn特征的方法的共性在于涉及的特征都是通过2d cnn获得的。在视频中使用2d cnn的一个简单方法就是对视频中的每一帧使用2d卷积,但是视频是三维数据,这种方法忽略了视频中时间维度的信息,没有利用联系帧间的运动信息。于是,双流体系结构应运而生,它的迹象就是分别训练两个2Dcnn分别学习外观(RGB)和运动(光流)两路输入信息的特征,并基于这两类特征作出行为的判断。此外,lstm也用来探索帧级2d特征的时空关系。

2d cnn和3d cnn在结构上是相似的,但是3d cnn在卷积过程中可以将视频中连续帧堆叠为立方体,并在此立方体中运用3d卷积核,从而能够提取时空混合特征。
但是由于3d cnn比2d cnn结构复杂,参数量大,通常其网络深度有限,难以训练,于是,出现了一些近似的深度神经网络,2d卷积网膨胀或者2d+1d网络来逼近3d卷积网络。
3D/2D混合卷积模块
将时空维度混合在一起的同时,也增加了3D cnn网络的优化难度。与相应的2d cnn相比,参数量大,大量参数堆叠在一起形成3d cnn,这极大的增加了优化难度,内存使用和计算成本,使得训练一个深度3d cnn变得非常困难
视频图像中时空信息的分布并不是均衡的,同空域信息相比,视频中时域信息的冗余度较高,相邻两帧间的内容通常很相似。
每个空域都会产生一个混合了时空信息的2d特征图,增强2d特征图的分析能力也能够进一步提升3d卷积的性能
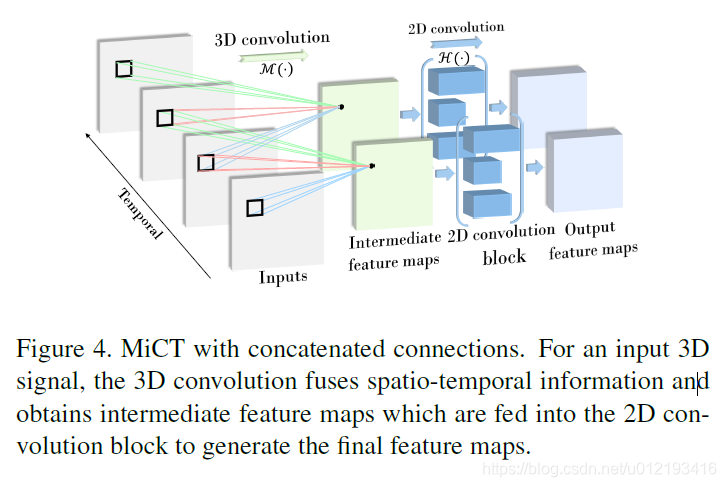
在模块中,我们提出在每个3D卷积之后串联一个深度2d cnn。通过3D/2D串联模块,我们可以有效的增加3d cnn的深度,加强2d空域的学习能力,从而生成更深更强的3d特征,并使得3d cnn可以充分利用在图像数据上预先训练的2d cnn模型,在相关的网络设计中,我们提出相应的减少3d卷积的数目,从而进一步的减少墨香的大小,提升模型的效率。
(3d cnn有自己的卷积操作,这就是说通过对cnn之后的卷积进行2d cnn从而减少3d cnn的纵深,尽量少的使用3d cnn)
3D/2D跨域残差并联模块
通过3D/2D串联模块的使用,我们得到了一个更深的3D卷积神经网络,然而,更深的cnn通常意味着更难的训练过程。如果只是简单堆叠层数来加深网络可能造成梯度消失并导致更大的训练误差。为了解决这个问题,我们提出利用3d和2d特征图之间的相关性,让3d和2d卷积来共享空间信息。由于2d空间特征相对容易学习,我们可以利用2d卷积并通过残差学习的方式来促进3d特征的学习。
(通过2d cnn加深3d cnn的cnn空域能力)
在3d cnn的输入和输出之间引入另一个2d cnn的残差连接,以进一步降低时空融合的复杂性,并有效的促进整个网络的优化

Shortcut是跨域的,并联的两路并不是相同的2d或者3d卷积,其中一路是处理3d输入的3d卷积,一路是处理2d输入的2d卷积
由于视频流中包含大量相似连续帧,这导致沿着时间维度的特征图中包含大量的冗余信息。通过引入2d卷积来提取信息丰富但是静止的2d特征,mict中3d卷积仅需要沿时间维度学习残差信息。同时,2d和3d卷积共享空域信息,因此,跨域残差连接在很大程度上降低了3d特征学习的复杂性。

结合上述两个子模块:3D/2D串联混合模块和3D/2D跨域残差并联模块,实现功能和效率的提高
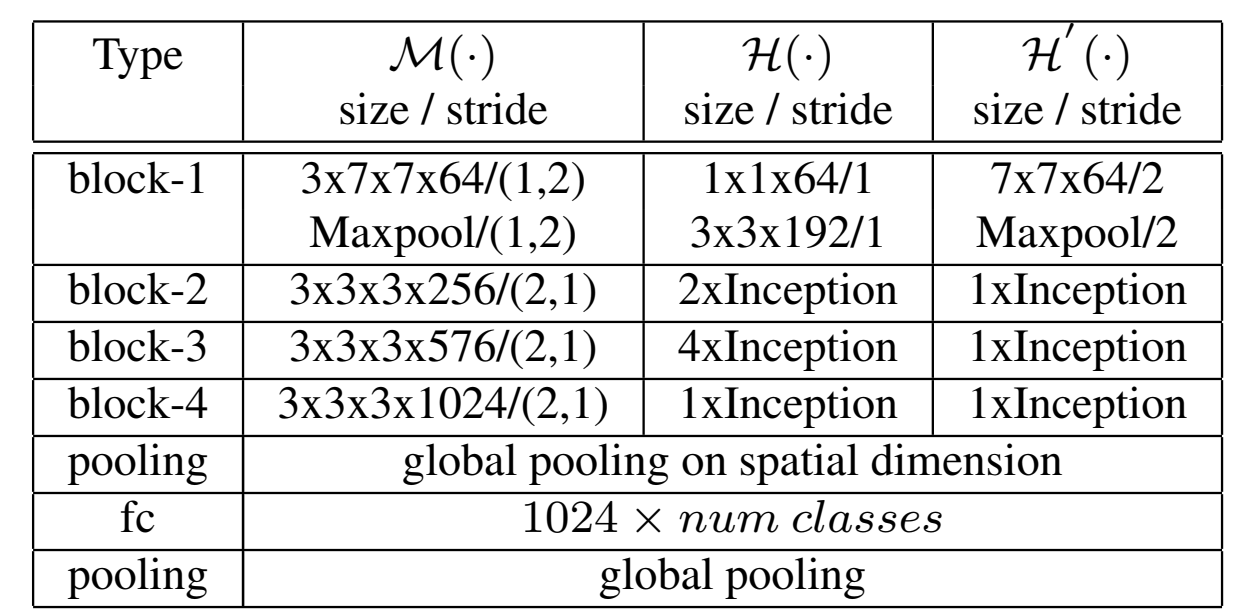
深度Mict网络mict-net
4个mict模块,4个3d cnn,将rgb视频序列作为输入,可进行端到端学习,最后一层使用时间维度上的全局池化,使网络可以接受任意长度的视频作为输入

包含较少的用于时空融合的3d卷积,但是产生可更深的特征图,同时有效的控制了整个深度模型的复杂性。此外,与传统的3d cnn不同,我们的框架能够利用在大型图像数据集上预训练的2d模型,可能会为2d卷积模块提供更好的初始化。